




Appleが1枚の画像からリアルな照明効果を持つ3Dオブジェクトを再現できるAIモデルを発表

Appleの研究チームが反射やハイライト、その他の効果を様々な視点から見ても一貫して維持しながら、一枚の画像から3Dオブジェクトを再構築することができるAIモデルの「LiTo」を開発しました。
LiTo: Surface Light Field Tokenization - Apple Machine Learning Research
https://machinelearning.apple.com/research/lito

New Apple model recreates 3D objects with realistic lighting effects - 9to5Mac
https://9to5mac.com/2026/03/16/apples-new-ai-model-recreates-3d-objects-with-realistic-lighting-effects-from-a-single-image/
機械学習における潜在空間の概念は全く新しいものではありません。しかし、Transformerモデルに基づくAIモデルや世界モデルの登場により、これまで以上に潜在空間の人気は高まっているそうです。
潜在空間とは、情報を要約して概念を数値で表現し、この数値を多次元空間に配置し、各次元における数値間の距離を計算できるようにするというものです。古典的な例として挙げられるのが「王」というトークンを取得し、「男」というトークンを差し引き、「女」というトークンを加えると、「女王」というトークンの一般的な多次元領域にたどり着くというもの。
情報を潜在空間に数学的表現として保存することで、それらの間の距離を測定したり、生成されるべきものの確率を推定したりする処理が、より高速かつ計算コストを抑えて行えるようになるというものです。

Appleの新しい研究では、物体の形状と視点に依存する外観を同時にモデル化する3D潜在表現の「LiTo」を提案しています。これは、潜在空間において三次元物体をどのように再構築するかだけでなく、物体と相互作用する光が様々な角度からどのように見えるべきかを表現する方法を開発したとも言えます。
Appleの研究チームによると、これまでの同様の研究のほとんどは3D形状の再構築か視点に依存しない拡散反射の予測のいずれかに焦点を当てており、現実的な視点依存効果を捉えるのに苦労していたそうです。
これに対して、Appleの発表したLiToはRGB深度画像が表面光場のサンプルを提供するという点を活用します。LiToは表面光場のランダムなサブサンプルをコンパクトな潜在ベクトルセットにエンコードすることで、統一された3D潜在空間内で形状と外観の両方を表現することを学習します。これにより、複雑な照明下における鏡面反射やフレネル反射などの視点依存効果を再現することが可能となります。

また、研究チームは従来のように異なる角度からの画像を用いて3D再構成を行うのではなく、単一の画像からこれらの処理をすべて実行できるようにAIモデルをトレーニングすることにも成功しました。
テクノロジーメディアの9to5Macは、LiToの革新的な点は以下の2点であると称賛しています。
・エンコーダーは物体に関する情報を潜在空間内のコンパクトな表現に圧縮。つまり、目に見えるすべての詳細を保存する代わりに、物体の形状と光がその表面とどのように相互作用するかについて、凝縮された数学的記述を学習します。
・デコーダーはその逆の処理を実行。つまり、コンパクトな表現から完全な3Dオブジェクトを再構築し、形状と反射やハイライトといった照明効果がさまざまな視点から見た際にどのようになるかのの両方を生成します。
研究チームはLiToのトレーニングに、150種類の異なる視点と3種類の照明条件でレンダリングされた数千個のオブジェクトを用意。そして、その情報をすべて直接AIモデルに入力するのではなく、サンプルからランダムに小さなサブセットを選択して、それらを潜在表現に圧縮しました。
次に、デコーダーはデータの一部から物体全体とその様々な角度や照明条件下での外観を再構築するようトレーニングされます。
トレーニングの過程でシステムは物体の形状と、視点方向によって外観がどのように変化するかの両方を捉える潜在表現を学習。それが完了すると、さらに別のAIモデルをトレーニングしました。このAIモデルは物体の単一画像を入力として受け取り、それに対応する潜在表現を予測します。次に、デコーダーは視点角度の変化に伴う外観の変化を含む、完全な3Dオブジェクトを再構築します。
以下のページでは元の3Dオブジェクト(左)、Appleの開発したLiToが再構築した3Dオブジェクト(真ん中)、3Dモデル生成AIの「TRELLIS」が生成した3Dオブジェクト(右)の精度を比較することができます。
LiTo: Surface Light Field Tokenization
https://apple.github.io/ml-lito/index.html#recon-comparison
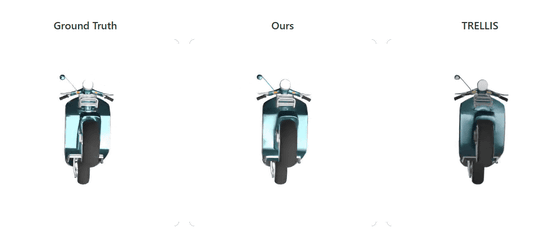
LiToの再構築した3Dオブジェクトは、TRELLISの生成した3Dオブジェクトと比較すると明らかに光の反射などの表現が元の3Dオブジェクトに忠実です。
・関連記事
Appleが1枚の画像を3Dシーンに変換できる手法「SHARP」を発表、標準的なGPUで1秒未満で処理可能 - GIGAZINE
AppleのAI研究チームがAIモデル「Depth Pro」をリリース、単一の画像を使用して標準GPUで225万ピクセルの3D深度マップを0.3秒で生成できる - GIGAZINE
無料でiPhoneを使って現実の物体を3DスキャンできるEpic Games公式アプリ「RealityScan」がリリースしたので使ってみた - GIGAZINE
Appleがスマホの画面を認識できるマルチモーダルLLM「Ferret-UI」を発表、SiriがiPhoneアプリのUIを理解できるようになる可能性も - GIGAZINE
・関連コンテンツ







in AI, Posted by logu_ii
You can read the machine translated English article Apple has announced an AI model that can….