Apple has announced an AI model that can recreate 3D objects with realistic lighting effects from a single image.

Apple's research team has developed ' LiTo ,' an AI model that can reconstruct 3D objects from a single image while consistently maintaining reflections, highlights, and other effects from various viewpoints.
LiTo: Surface Light Field Tokenization - Apple Machine Learning Research

New Apple model recreates 3D objects with realistic lighting effects - 9to5Mac
https://9to5mac.com/2026/03/16/apples-new-ai-model-recreates-3d-objects-with-realistic-lighting-effects-from-a-single-image/
The concept of latent space in machine learning is not entirely new. However, with the emergence of AI models based on Transformer models and world models , latent space is reportedly gaining more popularity than ever before.
Latent space is a way of summarizing information, representing concepts numerically, arranging these numerical values in a multidimensional space, and calculating the distance between numerical values in each dimension. A classic example is taking the token 'King,' subtracting the token 'Man,' and adding the token 'Woman,' which leads to the general multidimensional realm of the token 'Queen.'
By storing information as mathematical representations in a latent space, processes such as measuring the distance between them or estimating the probability of what should be generated can be performed more quickly and with lower computational costs.

Apple's new research proposes 'LiTo,' a 3D latent representation that simultaneously models the shape and viewpoint-dependent appearance of an object. This not only describes how to reconstruct a three-dimensional object in latent space, but also develops a way to represent how light interacting with the object should appear from various angles.
According to Apple's research team, most similar studies to date have focused on either reconstructing 3D shapes or predicting diffuse reflections that are independent of viewpoint, and have struggled to capture realistic viewpoint-dependent effects.
In contrast, Apple's LiTo leverages the fact that RGB depth images provide samples of the surface light field. LiTo learns to represent both shape and appearance in a unified 3D latent space by encoding random subsamples of the surface light field into a compact set of latent vectors. This makes it possible to reproduce viewpoint-dependent effects such as specular and Fresnel reflections under complex lighting conditions.

Furthermore, the research team succeeded in training an AI model that can perform all of these processes from a single image, rather than using images from different angles to perform 3D reconstruction as in the past.
Technology media outlet 9to5Mac praised LiTo for the following two innovative aspects:
The encoder compresses information about an object into a compact representation in latent space. In other words, instead of storing all the visible details, it learns a condensed mathematical description of the object's shape and how light interacts with its surface.
The decoder performs the reverse process: it reconstructs a complete 3D object from a compact representation, generating both the shape and how lighting effects such as reflections and highlights appear from various viewpoints.
The research team prepared thousands of objects rendered under 150 different viewpoints and 3 different lighting conditions for training LiTo. Instead of directly inputting all of this information into the AI model, they randomly selected a small subset from the samples and compressed them into a latent representation.
Next, the decoder is trained to reconstruct the entire object and its appearance from various angles and under different lighting conditions from a portion of the data.
During the training process, the system learned latent representations that captured both the shape of an object and how its appearance changes depending on the viewpoint direction. Once that was complete, another AI model was trained. This AI model takes a single image of an object as input and predicts its corresponding latent representation. The decoder then reconstructs the complete 3D object, including the changes in appearance as the viewpoint angle changes.
On the following page, you can compare the accuracy of the original 3D object (left), the 3D object reconstructed by Apple's LiTo (center), and the 3D object generated by the 3D model generation AI 'TRELLIS' (right).
LiTo: Surface Light Field Tokenization
https://apple.github.io/ml-lito/index.html#recon-comparison
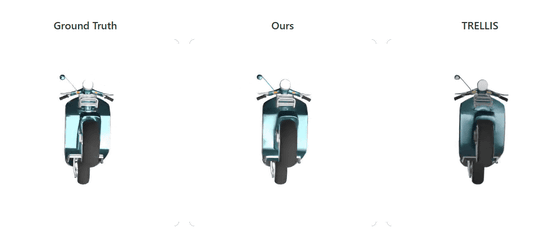
LiTo's reconstructed 3D objects are clearly more faithful to the original 3D objects in terms of rendering light reflections and other details compared to 3D objects generated by TRELLIS.
Related Posts:







in AI, Posted by logu_ii