




Anthropicが生命情報解析のベンチマーク「BioMysteryBench」を発表、Mythosは人間が解けなかった問題のうち約30%を解決
AIモデルの「Claude」を開発するAnthropicが、生命情報解析を行う研究分野「バイオインフォマティクス」におけるAIの能力を測定するベンチマーク「BioMysteryBench」を発表しました。科学分野におけるAIの性能をこれまで以上に効果的に測れるものと紹介されています。
Evaluating Claude’s bioinformatics research capabilities with BioMysteryBench \ Anthropic
https://www.anthropic.com/research/Evaluating-Claude-For-Bioinformatics-With-BioMysteryBench
Anthropicは「医師や弁護士になるためには試験があるが、科学者になるための試験は存在しない。同じ問題はAIにも当てはまり、科学分野のベンチマークではソフトウェアにおける『SWE-bench』ほど標準的なものはまだ存在していない。これは、科学研究、特に生物学が、ベンチマークによる評価を非常に難しくするいくつかの特性を持っているためだ」と指摘しています。
特に、生物学では数学などとは違い「正しいやり方」が複数存在することが多く、個々の研究判断が非常に主観的で、ノイズの多いデータセットではまったく異なる結論につながる可能性があり、人間がまだ答えを出せていない生物学的問いが多く存在するといった課題が挙げられ、効果的にAIの性能を評価できるベンチマークが必要とされていました。

BioMysteryBenchは、現実世界の複雑なバイオインフォマティクスデータを使用しつつ、そのデータに内在する複雑さや課題が評価の質を損なわないようにしたベンチマークです。研究の自由度と創造性が許容されていて、AIは多様な戦略を選択して問題を解くことが可能。さらに、評価はモデルがたどった経路ではなく最終的な回答に基づいて行われ、正しい生物学的結論に到達すれば高く評価されるため、モデルの結論が科学者の結論と一致するかどうかを判断しつつ、モデルが創造的な解決策を考案できるかどうかなど複数の項目を横断的に検証することができるとされています。
BioMysteryBenchは、バイオインフォマティクスのさまざまな分野からの99個の問題で構成されており、中には客観的な正解が存在するにもかかわらず、人間が自力で解決するのが困難または不可能な問題がいくつか含まれています。
Anthropicは各問題について、最大5人の専門家に回答してもらいました。少なくとも1人の人間が正解した場合、その問題は人間が解けると見なしました。
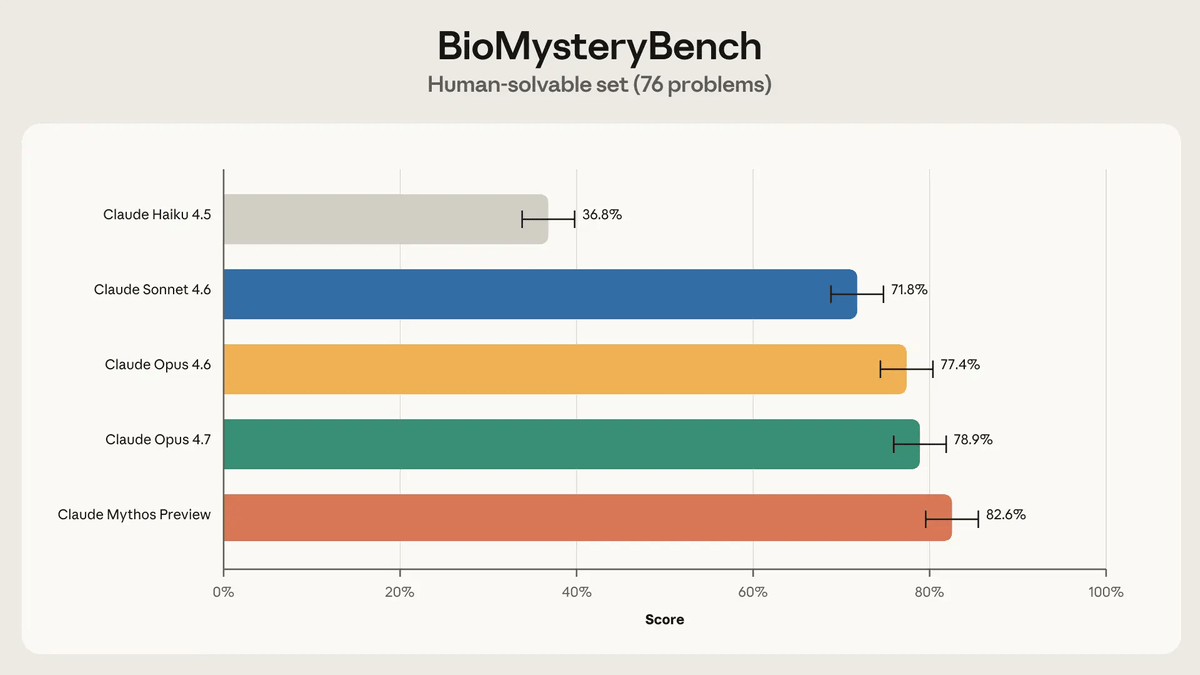
99問中、人間が解答できたのは76問でした。これらの問題を複数のAIモデルに解かせたところ、Claude Mythos Previewは5回の試行で平均82.6%の正答率を記録。Claude Sonnet 4.6、Claude Opus 4.6、Claude Opus 4.7も70%を超える正答率を記録しました。
Claudeは人間の戦略を模倣することもあれば、まったく異なるアプローチを取ることもありました。また、一例では人間の専門家がアルゴリズムやデータベースを用いてデータセットの特性を特定・注釈付けしていたのに対し、Claudeは特定のパターンや配列を直感的に認識していたこともあったそうです。このような抽象化はAIに特有というわけではなく、人間が行った過去の発見でも同様の事例があります。Anthropicは「『直感』は従来の生物学の機械学習モデルでは構築が困難でしたが、大規模言語モデルはこのようなパターンを前例のない規模で発見できる可能性があります」と考察しています。
残りの23問は人間が解けない問題でした。これは、問題が不適切または破損している、問題が本質的に解決不能である(例えばシグナルがデータに含まれていない)、理論的には解けるが人間は必要な知識を持っていないという3つのいずれかを意味します。
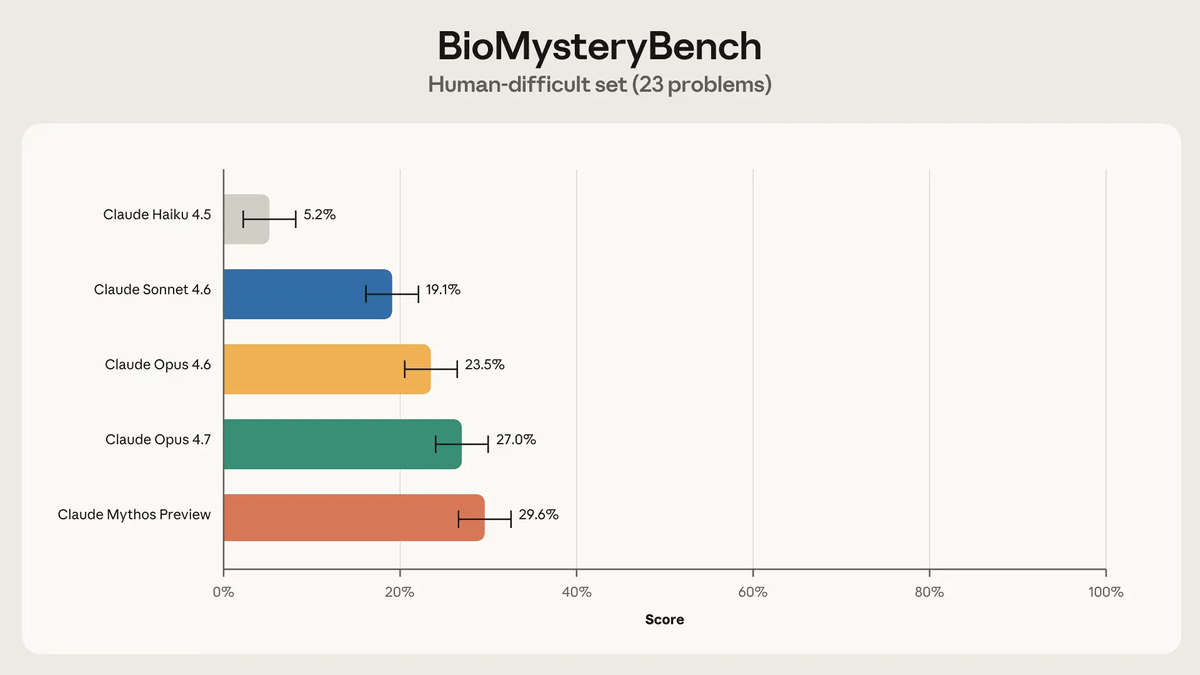
Anthropicが不適切または破損している問題を省く19問を各モデルに解かせたところ、平均5回の試行で以下の正答率が示されました。もっとも正答率が高かったのはやはりClaude Mythos Previewで、最大で30%に達していました。
モデルのうちClaude Opus 4.6の戦略を分析したところ、2つの主要な方法を採っていたことが明らかになります。
1つはAI特有のもので、AIが持つ膨大な知識を活用して解析を行うというものでした。人間であればメタアナリシスを実行したり複数のデータベースをつなぎ合わせたりする必要がありますが、Claude Opus 4.6はそのデータ構造を駆使してリアルタイムの解析を行っていました。
もう1つは、複数の手法を重ね合わせ、異なる証拠の系統を組み合わせて結論に到達するというものでした。これは人間がしばしば行う手法でもあります。
事前知識がClaudeにとって圧倒的に有利に働くように見えた一方で、人間が解ける問題群の中では逆に弱点となることも観察されました。Claude Opus 4.6は、答えに確信が持てない場合、簡単な問題でもしばしば複数の異なる方法で問題を解こうとし、複数のアプローチが収束する答えを選択して間違えてしまったそうです。
また、BioMysteryBenchには他の多くのベンチマークと同様に「人間もAIも解けていないタスクについて、それが不可能なのか、単に非常に難しいだけなのかを確信することはできない」という限界があります。
Anthropicは「BioMysteryBenchは科学的能力の有望なベンチマークです。最新世代のClaudeは、人間が解ける問題の大半を安定して解決し、人間にとって解決困難な問題では専門家を上回っています。モデルは世代ごとに改善しており、人間の科学者に追随するだけでなく、一部のタスクでは先行しています。私たちは、モデルの研究能力をさらに押し広げる、より長期的で現実世界に即したタスクを構築したいと考えており、他の人々からの創造的なアイデアを歓迎しています」と述べました。
・関連記事
生命科学研究のための推論AIモデル「GPT-Rosalind」をOpenAIが発表 - GIGAZINE
Nature誌が選ぶ「科学を変革したコンピューター技術10選」 - GIGAZINE
AIが「その感覚、完全に正しいです」などのごますり構文を使ってくる条件がAnthropicの調査により判明 - GIGAZINE
・関連コンテンツ








in AI, Posted by log1p_kr
You can read the machine translated English article Anthropic has released 'BioMysteryBench,….