




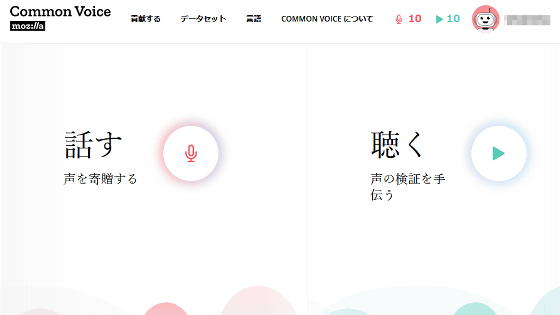
Mozillaによる18言語・1361時間にもおよぶパブリックドメインの音声データセット「Common Voice」
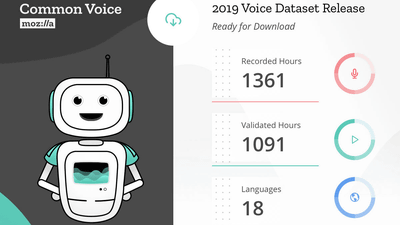
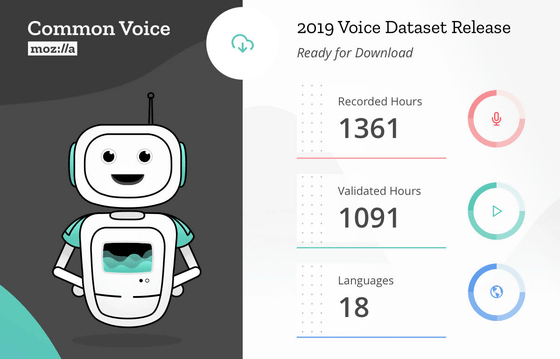
Mozillaが発表したパブリックドメインの音声データセットを提供するプロジェクト「Common Voice」が、4万2000人以上のデータ提供者から18言語・1361時間にもおよぶ音声データセットが集まったこと、そしてこのデータセットを公開することを明かしました。
Sharing our Common Voices - Mozilla releases the largest to-date public domain transcribed voice dataset - The Mozilla Blog
https://blog.mozilla.org/blog/2019/02/28/sharing-our-common-voices-mozilla-releases-the-largest-to-date-public-domain-transcribed-voice-dataset/
SiriやGoogleアシスタント、Alexaといった音声認識アシスタントを含む音声技術を開発することに最適化された、世界最大級の音声データセットを構築するため、MozillaはCommon Voiceプロジェクトを始動しました。MozillaはCommon Voiceプロジェクトの概要を明らかにした際、データセットのオープン性を保ち、高品質の音声データセットをスタートアップ、研究者、音声技術に興味を持つあらゆる人が利用できるようにすることを約束していました。
そして2019年2月28日、Mozillaは英語・ドイツ語・フランス語・ウェールズ語・ブルトン語・チュヴァシ語・トルコ語・タタール語・キルギス語・アイルランド語・カビル語・カタルーニャ語・中国語(台湾)・スロベニア語・イタリア語・オランダ語・ハーカチン語・エスペラント語という18言語に対応した、Common Voiceプロジェクトとしては初の多言語データセットをリリースすることを明かしました。このデータセットは4万2000人以上の協力者から提供された音声データから成り立っており、総再生時間は1368時間にもなります。
Mozillaは「継続的に成長しているCommon Voiceのデータセットは、今やこの種のデータセットとしては最大のものとなりつつあります。何万人もの人々が声とオリジナルの文章をパブリックドメインに投稿しています。今後はすべての音声データセットがCommon Voiceのサイト上からダウンロードできるようになります」と記しています。
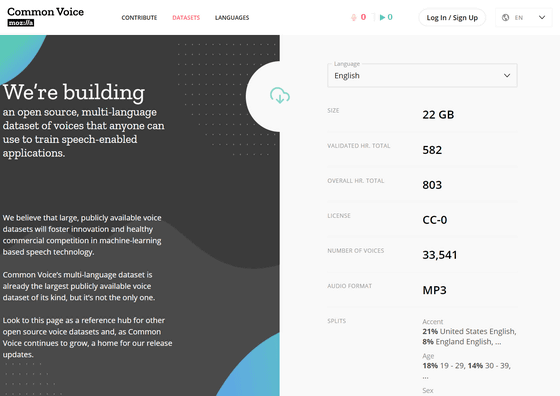
データセットは言語別にダウンロード可能となっており、音声データの形式はMP3です。例えば英語の場合、データサイズは22GB、音声時間は803時間、音声データの数は3万3541件、アメリカ英語が21%、イギリス英語が8%、データ提供者の年齢は19~29歳が18%、30~39歳が14%、性別は男性が41%、女性が10%で、以下からダウンロード可能です。
Common Voice
Common Voiceのデータセットはサイズが大きくオープンアクセスである点だけが特徴というわけではありません。データの多様性も非常にユニークなものとなっています。データ提供者は自分の年齢・性別・アクセントなどに関するメタデータを一緒に提供可能となっており、音声データを用いた開発に有用な情報をタグ付けすることができるようになっています。
Common Voiceが2018年6月に多言語のサポートを発表して以来、プロジェクトはよりグローバルで包括的なものに成長していきました。これはMozillaの期待を超える成果だそうで、「過去8か月間で、コミュニティはプロジェクトに熱心に集まり、70を超えるCommon Voice関連サイトの中で、22もの言語におけるデータ収集の取り組みがスタートしました」と記しています。音声データ収集はコミュニティ主導で行われており、自分たちの言語で音声データセットを作成することに関心を持つ、言語学者や技術者、ボランティアたちがそれぞれの取り組みを行っているとのこと。最近になって追加された言語として、Mozillaは「オランダ語、ハッカチン語、エスペラント語、ペルシア語、バスク語、スペイン語」などを挙げています。

by Panos Sakalakis
Mozillaはより多様で革新的な音声技術エコシステムへの貢献を目指していると公言しており、研究者や小規模なプレイヤーもサポートしながら音声対応製品を自分たちでリリースすることを目標に挙げています。Common Voiceを通してデータを提供することは、Mozillaの機械学習グループが推進するDeepSpeechや、オープンソースの「音声→テキスト」または「テキスト→音声」エンジンを訓練することに役立つはずとしています。
DeepSpeechはすでにMozilla以外のさまざまなプロジェクトで利用されています。例えば、オープンソースの音声ベースのアシスタント「Mycroft」や、オープンソースのパーソナルアシスタント「Leon」、さらには電話交換システムの「FusionPBX」などにも用いられています。将来的にDeepSpeechはスマートフォンや車載システムなどの、小型プラットフォームをターゲットとする音声技術製品に用いられることとなり、Mozilla内外で製品革新を促すことになるとのこと。
なお、Mozillaは「我々の全体的な目標は音声技術を構築し使用しようとしている世界中のすべての人々により多くの、そしてより良いデータを提供すること」と記しています。
・関連記事
IBMが100万人の顔データを収めた膨大なデータセットを「顔認識技術の公平性」を目指してリリース - GIGAZINE
Googleが科学者やジャーナリストを助ける「データセット検索」の提供を開始 - GIGAZINE
27TB以上の研究用データセットをBitTorrentで共有する「Academic Torrents」 - GIGAZINE
「バッハっぽさとは何か?」をAIに理解させることを可能にする330曲・100万音分のデータセットが公開される - GIGAZINE
史上最大規模の動画データセット「YouTube-8M」公開 - GIGAZINE
・関連コンテンツ





in ソフトウェア, Posted by logu_ii
You can read the machine translated English article 18 languages by Mozilla · 1361 hours of….