Googleの自己ゲーム学習AI「DQN」も苦戦した「Montezuma’s Revengeでハイスコアをたたき出すAIの開発」をたったひとつのデモンストレーションから学習することで達成

囲碁チャンピオンを打ち破った人工知能(AI)のAlphaGoや、ゲームを自ら学んで人間以上に上達できるAI・DQNを開発するGoogleの人工知能開発企業・DeepMindは、過去にDQNを使って主人公がすぐに死んでしまうゲーム「Montezuma's Revenge」をプレイさせるという試みにチャレンジしています。このチャレンジが発表されてから2年が経過した2018年7月に、突如AIをオープンソース化する非営利の研究機関であるOpenAIが「Montezuma's Revengeでハイスコアをたたき出すAIの開発」に挑戦しています。
Learning Montezuma's Revenge from a Single Demonstration
https://blog.openai.com/learning-montezumas-revenge-from-a-single-demonstration/
OpenAIは「たったひとつの人間によるデモンストレーションプレイデータ」から、主人公がすぐに死んでしまう高難易度ゲームの「Montezuma's Revenge」で、7万4500点というハイスコアをたたき出すことが可能なAIエージェントの開発に成功しています。AIエージェントを学習する過程では、Dota 2の5対5バトルで人間チームに勝利可能なOpenAI Fiveを支える強化学習アルゴリズムのProximal Policy Optimization(PPO)が用いられており、これによりゲームスコアの最適化が図られているとのことです。
OpenAIによるAIエージェントが「Montezuma's Revenge」で7万4500点というハイスコアをたたき出す瞬間は、以下の画像をクリックした先のページ上部に埋め込まれているムービーで確認できます。ムービーは倍速再生されているため再生時間は6分ほどですが、実際には約12分のプレイで7万4500点というハイスコアを記録。また、AIエージェントは「Montezuma's Revenge」のプレイに利用しているエミュレーターの欠陥を利用することでハイスコアにつなげることが可能なプレイ方法(4分25秒前後)を、独自に編み出しています。つまり、学習に利用したデモンストレーションプレイデータにはないプレイ方法を独自に考案して実行に移しているというわけです。

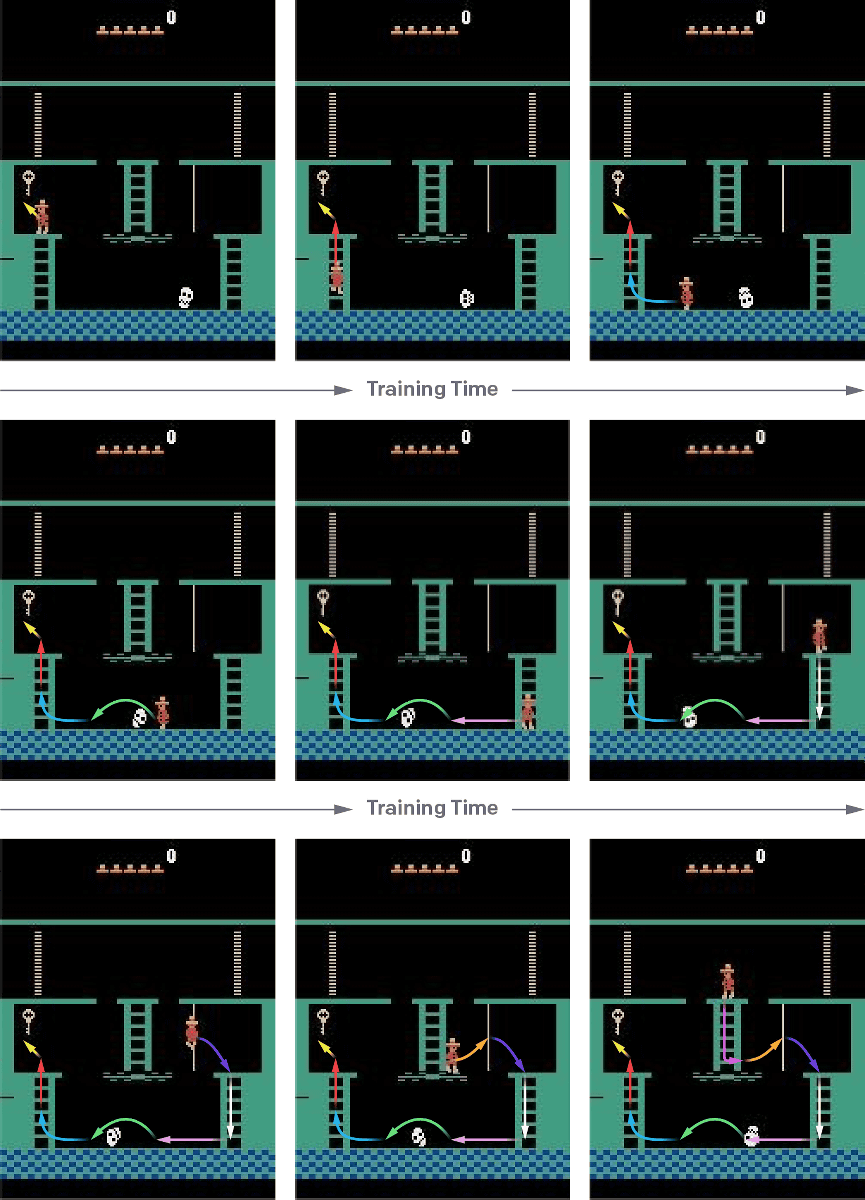
OpenAIは「Montezuma's Revenge」でハイスコアをたたき出すために、AIエージェントが「肯定的な報酬につながる一連の行動を見つける」という探索上の問題と、「取るべき一連の行動を覚えておき、関連する微妙に異なるシチュエーションを一般化する」という学習上の問題の2つをクリアする必要があると考えたそうです。探索上の問題については、各強化学習のエピソードをデモンストレーション状態からリセットしてスタートすることでクリアできるようになったとのこと。これはデモンストレーション状態から強化学習のエピソードをスタートすると、AIエージェントはリセットした時と比べて探索から学習する内容が少なくなるためだそうです。OpenAIは「Montezuma's RevengeやPrivateEyeのような似たゲーム性のAtariゲームをAIエージェントにプレイさせる中で、探索と学習を比べると、探索がより難しい問題としてAI学習の前に立ちはだかることがわかった」と記しています。
方策勾配法やQ学習のようなデモンストレーションデータなしでの強化学習は、AIエージェントにアクションをランダムに実行させることで探索を行います。ランダムアクションのうち報酬につながったものを強化することで、AIエージェントは「このアクションを行うと報酬につながる」ということを覚え、実際のシチュエーションでその行動を実行するようになります。しかし、より複雑なゲームになると報酬を得るまでの一連のアクションが長くなるため、そういった一連のアクションがランダムに発生する確率は極めて低くなってしまいます。つまり、デモンストレーションプレイデータなどを使用しない強化学習方法は、一連の長いアクションが報酬につながるような複雑なゲームについて学習させるには向いていないものと思われるわけです。しかし、言い換えれば短いアクションが報酬につながるような単純なゲームではうまく機能するということです。
そこで、OpenAIは強化学習に際してデモンストレーションプレイデータの最後に近い部分からAIエージェントにプレイ方法を学習させるという手法を採ります。繰り返し学習させてエージェントがデモから得られる得点方法などを少なくとも20%再現可能になったところで、デモの学習ポイントを少しだけ前に戻し、再び学習をスタートさせます。これを繰り返し続けることで、最終的にデモをまったく使用しなくてもAIエージェントがゲームをプレイできるようになるまで、学習を続けることで、AIエージェントが人間の熟練プレイヤーよりもハイスコアをたたき出せるようになるとのことです。
OpenAIは「我々のAIエージェントにより行われたステップバイステップの学習方法はゼロからゲームプレイを学ぶよりもはるかに簡単ですが、まだまだ平凡なものです」と語っています。実際、まだまだ多くの問題を抱えているとのことで、アクションのランダム性が原因で特定のアクションシーケンスが正確に再現されないケースもある模様。よって、エージェントは「非常に類似しているが同一でない状態を一般化することができるようになる必要がある」とOpenAIは記しています。OpenAIによるとMontezuma's Revengeの中ではこれに成功しているものの、より複雑なGravitarやPitfallといったゲームではあまりうまくいっていないとのことです。
加えて、方策勾配法のような標準的な教科学習法では探索と学習の間に慎重なバランスが必要となるという問題にも直面しているそうです。AIエージェントの行動があまりにもランダム過ぎると、ゲームのスタート時に決められたアクションを取る必要があるものでは最終スコアに大きな差が出るミスを連発してしまいます。逆にAIエージェントの行動があまりに決められたものとなってしまうと、エージェントは探索の途中で学習を辞めてしまう模様。GravitarやPitfallではこの「探索と学習における最適なバランス」を見つけ出すことができなかったともしており、「将来的な強化学習の進歩により、ランダムノイズやHyperパラメーターの選択に対する強固なアルゴリズムが得られることを願っている」とOpenAIは記しています。
なお、OpenAIが開発したAIに関するソースコードは以下で公開されています。
GitHub - openai/atari-reset: Learn RL policies for Atari by resetting from a demonstration
・関連記事
OpenAIの人工知能「OpenAI Five」がDota 2の5対5バトルで人間チームに勝利 - GIGAZINE
レトロゲームの攻略をAIに学習させてスーパープレイを生み出すことが可能な「Gym Retro」 - GIGAZINE
OpenAI開発の人工知能がゲームDota 2の1対1バトルで人間の世界チャンピオンに勝利 - GIGAZINE
・関連コンテンツ