Google's self-game learning AI 'DQN' also struggled also 'development of AI to hike high score at Montezuma's Revenge' achieved by learning from only one demonstration

Google's artificial intelligence development company, DeepMind , which develops AlphaGo of artificial intelligence (AI) who broke the Go champion and AI · DQN which can learn game himself and can improve more than human beings · Deep Mind used the DQN in the past, the hero immediately I am challenging to try to play the dead game "Montezuma's Revenge". Two years after this challenge was announced July 2018, OpenAI which is a nonprofit research institute suddenly converting AI to open source challenges " development of AI which hits high score at Montezuma's Revenge " I will.
Learning Montezuma's Revenge from a Single Demonstration
https://blog.openai.com/learning-montezumas-revenge-from-a-single- demonstration/
OpenAI is aiming to develop AI agent capable of hitting high scores of 75,500 points at "Montezuma's Revenge" in a high difficulty game where the hero dies soon from "Only one human demonstration play data" I am successful. In the course of learning AI agents, Proximal Policy Optimization (PPO) of Reinforcement Learning Algorithm that supports OpenAI Five that can win against human team with 5 to 5 battle of Dota 2 is used, and optimization of game scores It is said to have been done.
The moment the AI agent by OpenAI hits the high score of 75,400 points in "Montezuma's Revenge", you can check with the movie embedded in the top part of the page you clicked on the following image. Since the movie is played at double speed, the playing time is about 6 minutes, but in fact it recorded a high score of 75,500 points in about 12 minutes of play. In addition, the AI agent has independently developed a playing method (about 4 minutes and 25 seconds) that can connect to the high score by using the defect of the emulator used for playing "Montezuma's Revenge". In other words, we devised a playing method that is not in the demonstration play data used for learning, and we are putting it into practice.

In order to hijack the high score with "Montezuma's Revenge", OpenAI has a problem in searching that the AI agent "finds a series of actions leading to positive rewards" and "a series of actions to be taken and related It seems that we thought that it was necessary to clear two problems of learning "generalizing slightly different situations". Regarding problems on searching, it is now possible to clear episodes of each reinforcement learning from the demonstration state and start by resetting them. This seems to be due to the fact that starting the episode of reinforcement learning from the demonstration state, the content of the AI agent learns from the search is less than when it is reset. OpenAI found that when searching and learning are compared while searching AI agents to play similar Atomic games like Atari games like Montezuma's Revenge and PrivateEye, it is found that searching is more difficult before AI learning as a difficult problem. " I write it.
Reinforcement learning without demonstration data like strategy gradient method or Q learning searches by causing the AI agent to execute an action at random. By strengthening those linked to the remuneration of random actions, the AI agent learns that "this action leads to rewards" and will execute that action in the actual situations. However, in a more complicated game, the series of actions to earn reward will be long, so the probability that such a series of actions occur randomly will be extremely low. In other words, the reinforcement learning method which does not use demonstration play data etc. seems to be unsuitable for learning about a complicated game that a series of long actions lead to reward. But in other words it works well for simple games where short action leads to reward.
Therefore, OpenAI adopts a method of letting the AI agent learn the playing method from the part near the end of the demonstration play data in reinforcement learning. When the agent learns repeatedly and the agent can reproduce the scoring method etc. obtained from the demonstration at least 20%, it will restore the demonstration learning point a little bit and start learning again. By continuing to repeat this, by continuing learning until the AI agent can play the game without finally using the demo at all, the AI agent can strike a higher score than a human skilled player It will become like it.
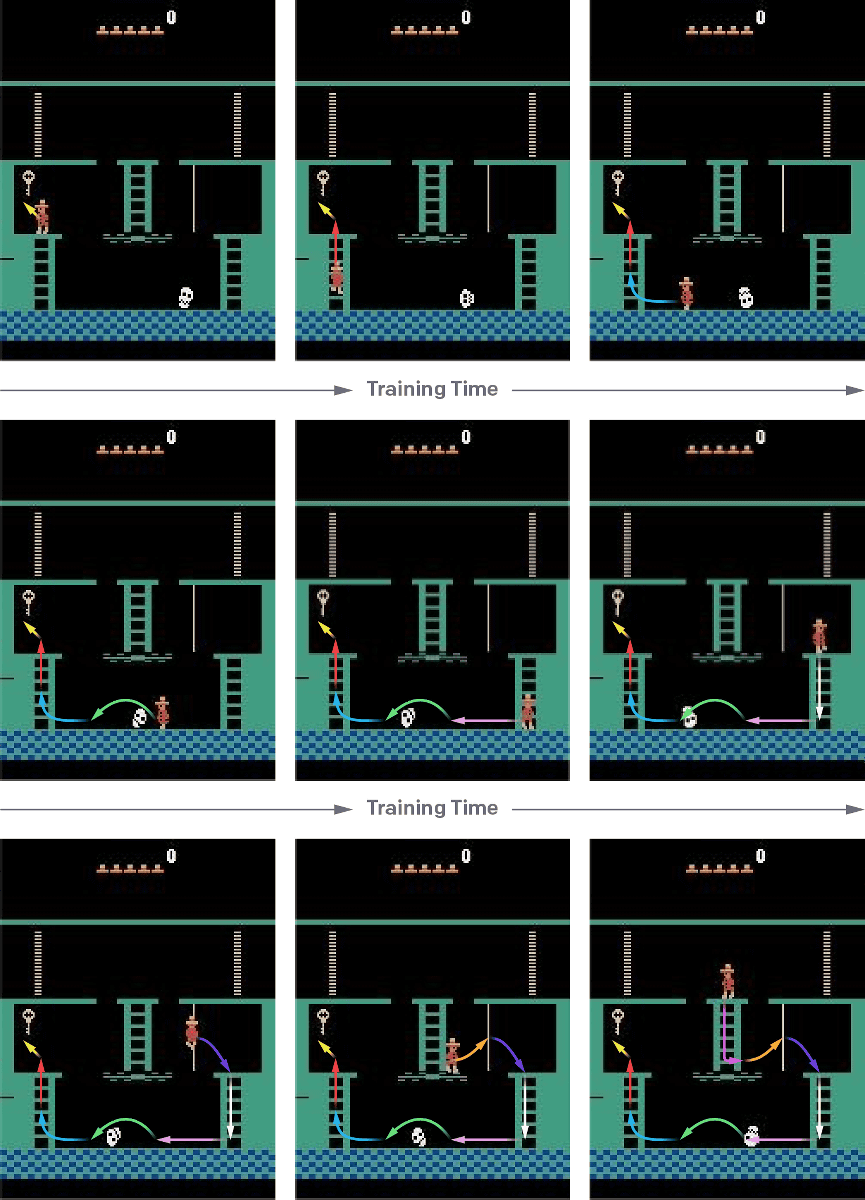
OpenAI says, "The step-by-step learning method performed by our AI agent is much easier than learning gameplay from scratch, but it is still trivial." Indeed, it seems that there are still many problems, and there are cases where the specific action sequence may not be accurately reproduced due to the random nature of the action. Therefore, the agent wrote "Open-ended IA needs to be able to generalize states that are very similar but not identical". According to OpenAI, although it is successful in Montezuma's Revenge, it is said that it is not so successful in games such as more complicated Gravitar and Pitfall.
In addition, it seems that we face the problem that a standard curriculum learning method such as the method gradient method requires a careful balance between exploration and learning. If the actions of the AI agent are too random, it will cause a series of mistakes that make a big difference in the final score if you need to take the actions decided at the start of the game. On the contrary, if the behavior of the AI agent is decided too much, the agent seems to leave learning in the middle of the search. Gravitar and Pitfall also said that he could not find out the "optimal balance in searching and learning", "I am able to obtain robust algorithms for selecting random noise and Hyper parameters by future advancement of reinforcement learning I am hoping for it, "OpenAI wrote.
The source code related to AI developed by OpenAI is published below.
GitHub - openai / atari - reset: Learn RL policies for Atari by resetting from a demonstration
Related Posts: