Google has released 'TabFM,' a foundational model that can predict tabular data in zero shots.
On June 30, 2026, Google Research announced 'TabFM,' a foundational model for tabular data. It is described as a model that can perform predictions such as classification and regression in zero shots on data composed of rows and columns.
Introducing TabFM: A zero-shot foundation model for tabular data

Much of the data handled by companies, such as sales, customers, transactions, and inventory, is stored in tabular form. Predicting future figures and classifying data into specific categories from tabular data is important, but traditionally, this required training models for each dataset, adjusting settings, and designing features that would aid in predictions.
While traditional methods like XGBoost and Random Forest have been widely used with tabular data, they require fine-tuning each time they are applied to new data. Google explains that simply running a model is not enough to obtain reliable predictions; a significant amount of time is spent on hyperparameter tuning and feature engineering.
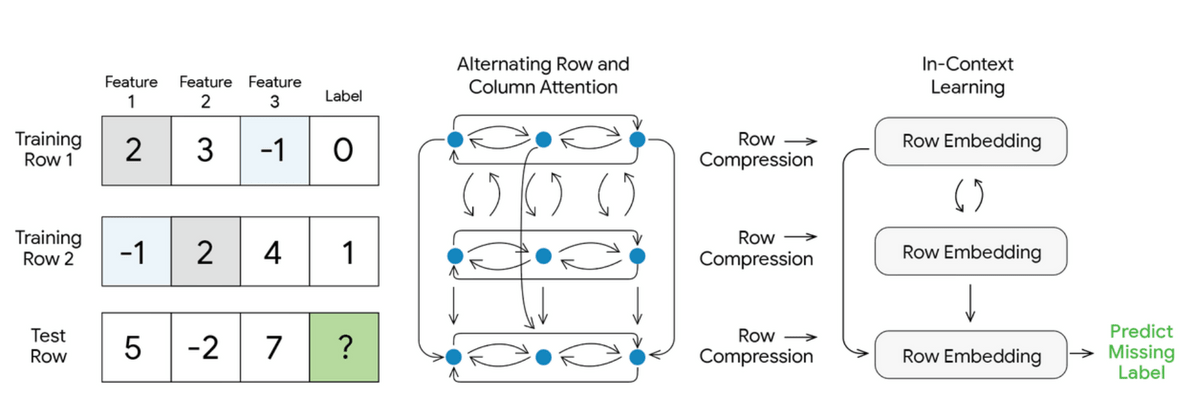
TabFM is a model developed to simplify the cumbersome process of analyzing tabular data, and it supports 'zero-shot' prediction, meaning it can make predictions without additional training tailored to the target data. TabFM reads past training examples and the row to be predicted together as a single context, interprets the relationships between columns and rows during inference, and generates predictions.
Unlike text, tabular data requires an understanding of the relationships between rows and columns, rather than a one-dimensional order like words. TabFM uses a mechanism that focuses on both row and column directions to represent the relationships within a table within the model. This process is said to reduce the burden on humans to manually create features.
AI training requires large datasets, but tabular data used by companies and other organizations often contains confidential information, making it difficult to collect publicly available data suitable for large-scale pre-training. Therefore, TabFM training uses a synthetic dataset of hundreds of millions of records rather than data from real companies.
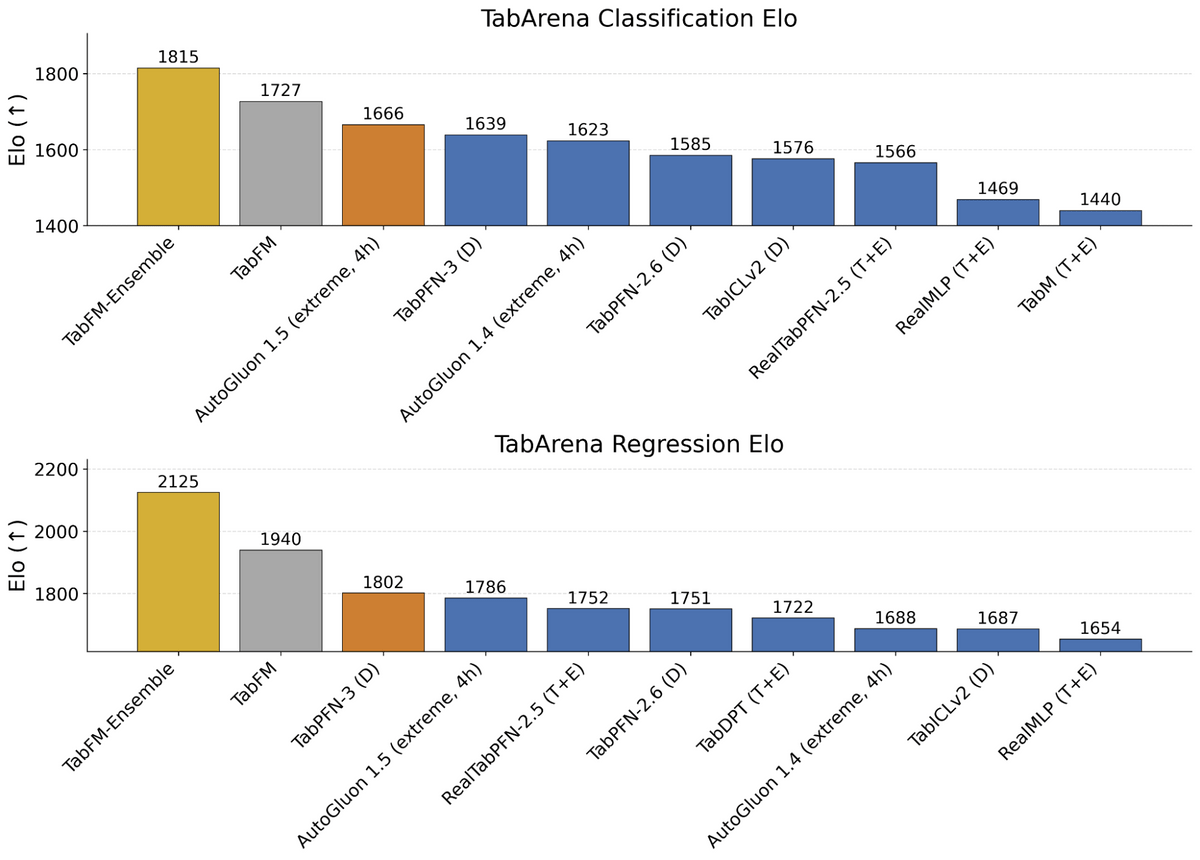
For performance evaluation, TabFM was validated using 'TabArena,' a tool that pits methods against each other in a competitive format and ranks them using Elo ratings. In both the classification task (upper panel) and the regression task (lower panel), 'TabFM-Ensemble,' which uses 32 different ensembles in addition to cross-sectional and SVD features, came in first place, while the standard 'TabFM' came in second.
Google plans to directly integrate TabFM into BigQuery, and within the next few weeks, BigQuery users will be able to perform regressions and classifications using the SQL command 'AI.PREDICT'.
The TabFM model itself is available under a non-commercial license on Hugging Face, and the usage code and samples are available on GitHub under the Apache 2.0 license.
google/tabfm-1.0.0-pytorch · Hugging Face
https://huggingface.co/google/tabfm-1.0.0-pytorch
GitHub - google-research/tabfm · GitHub
https://github.com/google-research/tabfm
Related Posts:






in AI, Posted by log1d_ts