LongCat-2.0, a Chinese-made AI model with 1.6 trillion parameters, has emerged, achieving performance comparable to the Gemini 3.1 Pro without using an NVIDIA AI chip.

Meituan, a Chinese company, has released ' LongCat-2.0, ' an AI model with 1.6 trillion parameters and a context length of 1 million tokens. The entire process, from pre-training to inference, was reportedly run on more than 50,000 chips in China.
Introducing LongCat-2.0
Completed the complete study of the country's core piece, universal large model LongCat-2.0 cloth
China claims biggest AI model trained on local chips, as Meituan releases LongCat-2.0 | South China Morning Post
https://www.scmp.com/tech/tech-trends/article/3358854/china-debuts-biggest-ai-model-trained-local-chips-meituan-releases-longcat-20
LongCat-2.0 is a massive MoE language model with a total of 1.6 trillion parameters, where approximately 48 billion parameters are activated per token. The maximum context length is 1 million tokens, and these specifications are roughly equivalent to DeepSeek's cutting-edge model, ' DeepSeek-V4-Pro '.
The underlying model is ' LongCat-Flash ,' with a total of 560 billion parameters, and improvements have been made to parameter efficiency and learning and inference speed in long text contexts.
According to Meituan, the proliferation of AI agent applications has created a need for large-scale language models to efficiently process long inputs, but there was a bottleneck in the 'attention' technique, which determines where to place weights in the input. Therefore, Meituan developed and introduced LongCat Sparse Attention (LSA), an evolution of the existing DeepSeek Sparse Attention. This has reportedly accelerated the processing of long contexts without compromising the quality of the model.

LongCat-2.0 is unique in that it runs entirely on domestically produced ASIC (Application-Specific Integrated Circuit) superpods, from training to deployment. While most existing cutting-edge AI models are trained and inferred using NVIDIA chips, China lags behind the US in AI development due to US regulations preventing it from obtaining the highest-performing NVIDIA chips. Companies like DeepSeek and Z.AI perform inference tasks on chips from Chinese manufacturers, including Huawei, but they still face challenges in training large-scale models.
Meituan did not specify which chip they used in their release, but later revealed on WeChat that they used the 'Huawei Collective Communication Library (HCCL).' This is an inter-chip communication system similar to the '
The accelerator used by Meituan has significantly less memory per device than the NVIDIA H800 (80GB) chip intended for the Chinese market, so they addressed this issue from two perspectives: parallelization strategy and memory management.
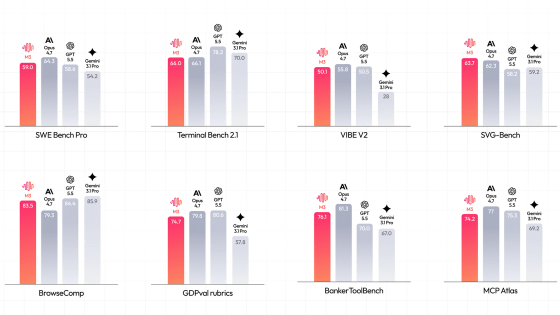
A table comparing LongCat-2.0 to other companies' models across three categories—Code Agent, General Agent, and Foundational Functions—has also been published. Its performance is comparable to Gemini 3.1 Pro.
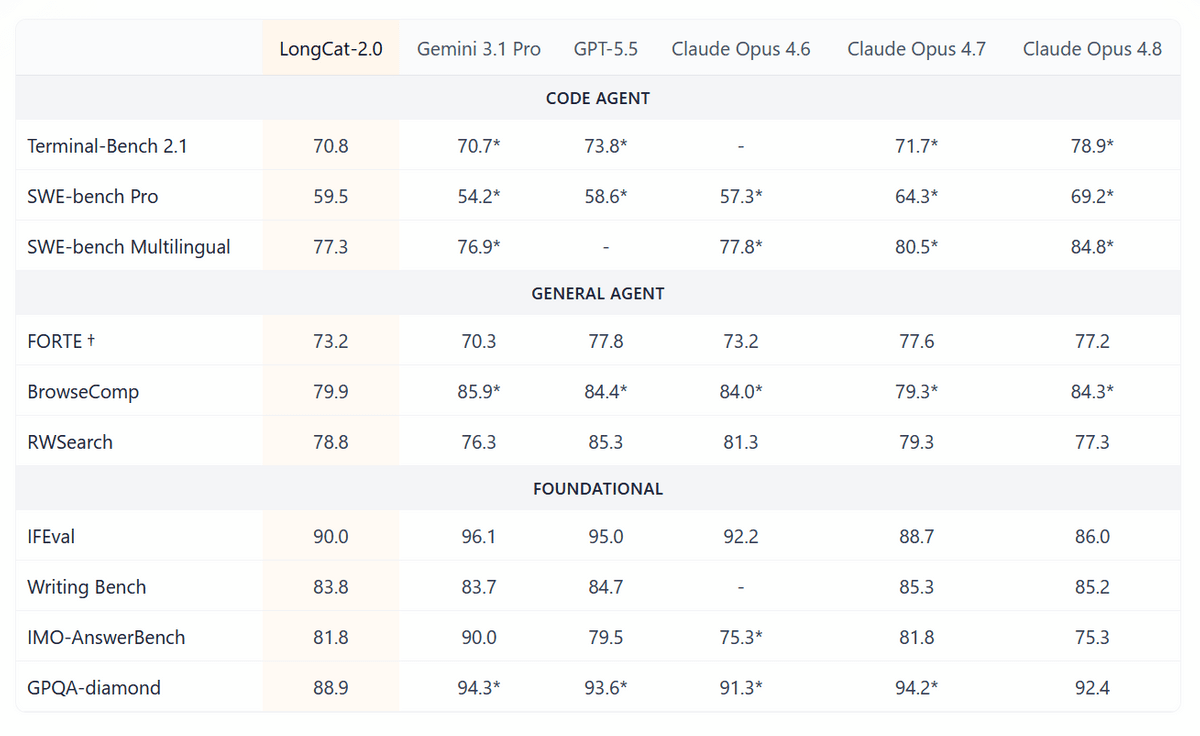
LongCat-2.0 is scheduled to be released as an open model soon, and a page for the model is already available on Hugging Face. The related code is also available on GitHub.
meituan-longcat/LongCat-2.0 · Hugging Face
https://huggingface.co/meituan-longcat/LongCat-2.0
GitHub - meituan-longcat/LongCat-2.0 · GitHub
https://github.com/meituan-longcat/LongCat-2.0
Related Posts:






in AI, Posted by log1p_kr