DwarfStar 4 is a compact native inference engine designed specifically for DeepSeek V4 Flash.

Salvatore Sanfilippo, the developer of the open-source in-memory database '
GitHub - antirez/ds4: DeepSeek 4 Flash local inference engine for Metal and CUDA · GitHub
https://github.com/antirez/ds4
A few words on DS4 - <antirez>
https://antirez.com/news/165
While typical local AI tools aim to run a wide range of AI models, DwarfStar 4 takes the opposite approach, specializing in a single model. DwarfStar 4 is specifically designed for 'DeepSeek v4 Flash,' released in April 2026 by the Chinese AI company DeepSeek.
The 'DeepSeek-V4' has finally arrived, an open-top model with performance exceeding that of the Claude Opus 4.6 - GIGAZINE
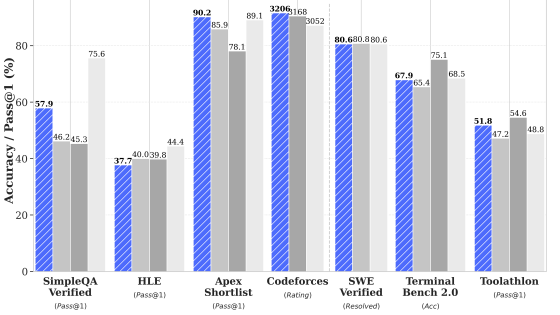
San Filippo cited several reasons for choosing DeepSeek V4 Flash, including: 'It has a context window of 1 million tokens,' 'It operates faster due to fewer active parameters,' 'In thinking mode, it avoids prolonging inference unnecessarily, resulting in much shorter thinking sections than other models,' and 'Its ability to write in English and Italian has been significantly improved.'
According to Sanfilippo, DwarfStar 4 leverages GPT 5.5, but the brainstorming, testing, and debugging processes were largely human-driven. He also stated that it wouldn't have been possible without llama.cpp and GGML , which was largely optimized manually.
A distinctive feature of DwarfStar 4 is a technique called 'asymmetric 2-bit/8-bit quantization.' Typically, large-scale language models require hundreds of gigabytes of memory, so they generally run on a cloud-based system. However, DwarfStar 4 significantly reduces memory consumption by compressing the model's weight data using a quantization format pioneered by the llama.cpp project. As a result, DwarfStar 4 reportedly ran smoothly on a MacBook with 128GB of RAM, and even on a 96GB system, it was able to run a context window with 250,000 tokens.
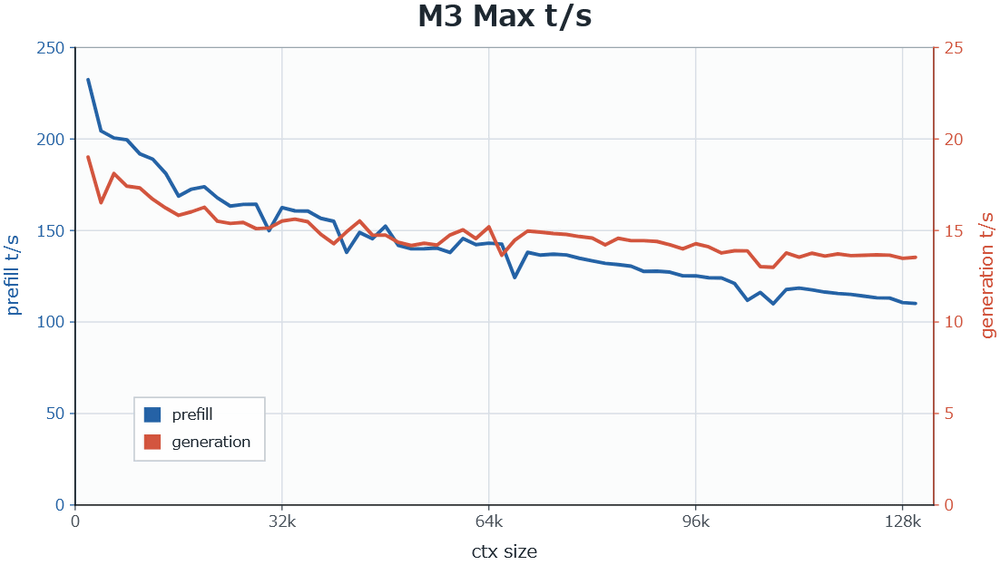
The following graph shows the performance of DwarfStar 4 running on an Apple M3 Max-equipped MacBook. Although the token generation speed (vertical axis) decreases as the context size (horizontal axis) increases, it maintains a practical speed even when exceeding 100,000 tokens.
DwarfStar 4 has garnered attention, receiving over 9,000 'stars' on GitHub. San Filippo wrote in a blog post, 'We didn't expect it to become popular this quickly. There was clearly a need for a local AI experience focused on single-model integration, but its success stems from the fact that a massive, fast model that redefines local inference was released, demonstrated that it works very well with highly asymmetric 2-bit/8-bit quantization techniques, can run on 96GB or 128GB of RAM, and became even more readily available thanks to GPT 5.5, all happening almost simultaneously.'
DwarfStar 4 has also been a hot topic on the social news site Hacker News, receiving high praise such as, 'Of course, the processing speed is much slower than Claude, but it's surprising how close it feels to Claude, to the point that I don't think the performance is significantly inferior,' comments pointing out the high reliability of tool calls compared to other open-source models, and comments expressing surprise that 'the long contextual inference is something I've never seen even in state-of-the-art models.' Simon Willison, the engineer who devised his own benchmark of having the AI draw a ' pelican riding a bicycle, ' also commented , 'I recently ran DwarfStar 4 on a 128GB M5. It was very easy, and the model ran on about 80GB of RAM, exhibiting very high capabilities in writing code and executing tools.'
Related Posts:








in AI, Posted by log1e_dh