Looking back at what was happening in the AI field in 2024, many AI models that surpassed GPT-4, which swept the market in 2023, appeared, and the expansion of context windows and multimodal models became common, causing prices to plummet.

Simon Willison, former engineering director at
Things we learned about LLMs in 2024
https://simonwillison.net/2024/Dec/31/llms-in-2024/
◆ The GPT-4 wall is completely broken
OpenAI's large-scale language model (LLM) GPT-4 , released in March 2023, was the best-performing AI model as of December of that year. However, by the end of 2024, many AI models had emerged that performed better than the original GPT-4.
According to Chatbot Arena , an open source AI benchmark for comparing LLM performance, at the time of writing there are 70 AI models that rank higher than the original GPT-4.
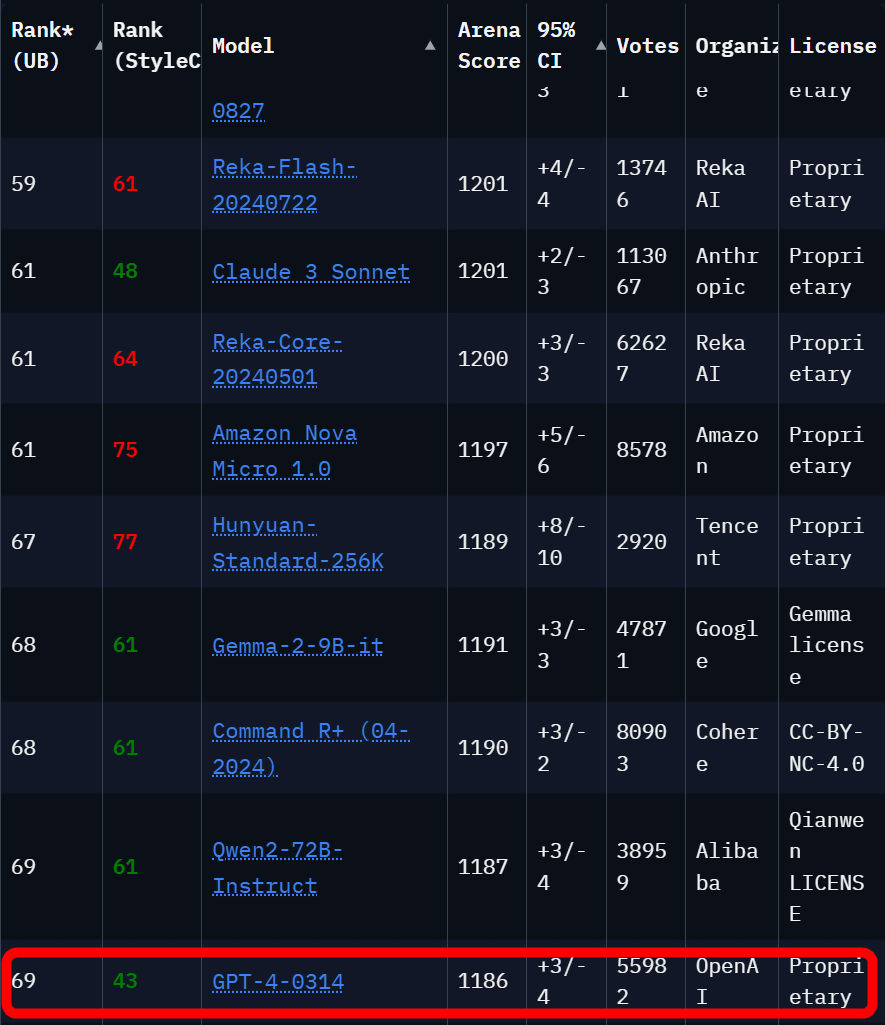
The oldest AI model that has performed better than the original GPT-4 is Google's Gemini 1.5 Pro (announced in February 2024). In addition to being able to generate outputs equivalent to the original GPT-4, Gemini 1.5 Pro can process 1 million tokens at a time (context window) and also has video input capabilities.
Google releases Gemini 1.5, which can handle up to 1 million tokens and handle 1 hour of movies and 700,000 words of text - GIGAZINE

Willison pointed out that Gemini 1.5 Pro also shows 'increased context length,' one of the major themes for 2024. While most of the context windows of AI models released in 2023 were '4096 tokens' or '8192 tokens,' Anthropic's ' Claude 2.1 ,' released in November 2023, has a context window of 200,000 tokens, and Gemini 1.5 Pro has been updated to extend the context window from 1 million to 2 million tokens.
Google updates Gemini 1.5 Pro, expanding context window from 1 million tokens to 2 million tokens - GIGAZINE

The expanded context window dramatically expands the range of problems that AI models can solve, making it possible to input an entire book and have it summarize its contents or ask questions about it. It also enables AI models to solve coding problems correctly, allowing you to input large amounts of sample code. 'Use cases for AI models that involve long inputs are much more interesting than short prompts that rely solely on the information already built into the AI model's weights. Many of my tools were built using this pattern,' Willison wrote.
Anthropic's 'Claude 3', released in March 2024, outperformed GPT-4 in multiple benchmark tests, and Willison wrote that it 'has quickly become my favorite everyday AI model.'
'Claude 3', a Japanese-compatible multimodal AI that can process images and text simultaneously with performance exceeding GPT-4, will be released - GIGAZINE

In addition, 'Claude 3.5 Sonnet' will be announced in June 2024, achieving even higher performance.
Anthropic suddenly releases Claude 3.5 Sonnet, benchmark results rival GPT-4o - GIGAZINE
The AI organizations that own AI models that performed better than the original GPT-4 in the Chatbot Arena are Google, OpenAI, Alibaba, Anthropic, Meta, Reka AI, 01 AI, Amazon, Cohere, DeepSeek, NVIDIA, Mistral, NexusFlow, Zhipu AI, xAI, AI21 Labs, Princeton, and Tencent.
Some models of GPT-4 can run on laptops
Willison is using a 2023-year-old M2-equipped MacBook Pro with 64GB of memory (RAM). Although the M2-equipped MacBook Pro is a high-performance laptop, it is important to understand that it is a model that was released in 2022. It seems that such an M2-equipped MacBook Pro was at a level where it could somehow run an AI model equivalent to GPT-3, but as of the end of 2024, it will be able to run an AI model equivalent to GPT-4.
Regarding this, Willison said, 'This is still a surprise to me. I thought that a model with the capabilities and output quality of GPT-4 would require one or more data center-class servers with GPUs costing more than $40,000 (about 6.3 million yen). However, in reality, you can run these on a laptop with 64GB of RAM. However, it takes up a large portion of RAM, so you can't run it often and you can't afford to use the laptop for other purposes. The fact that these can be run is a testament to the incredible improvements in training and inference performance that have been uncovered over the past year. We've seen that there are a lot of low-hanging fruit in terms of the efficiency of AI models. I expect there will be more to come.'
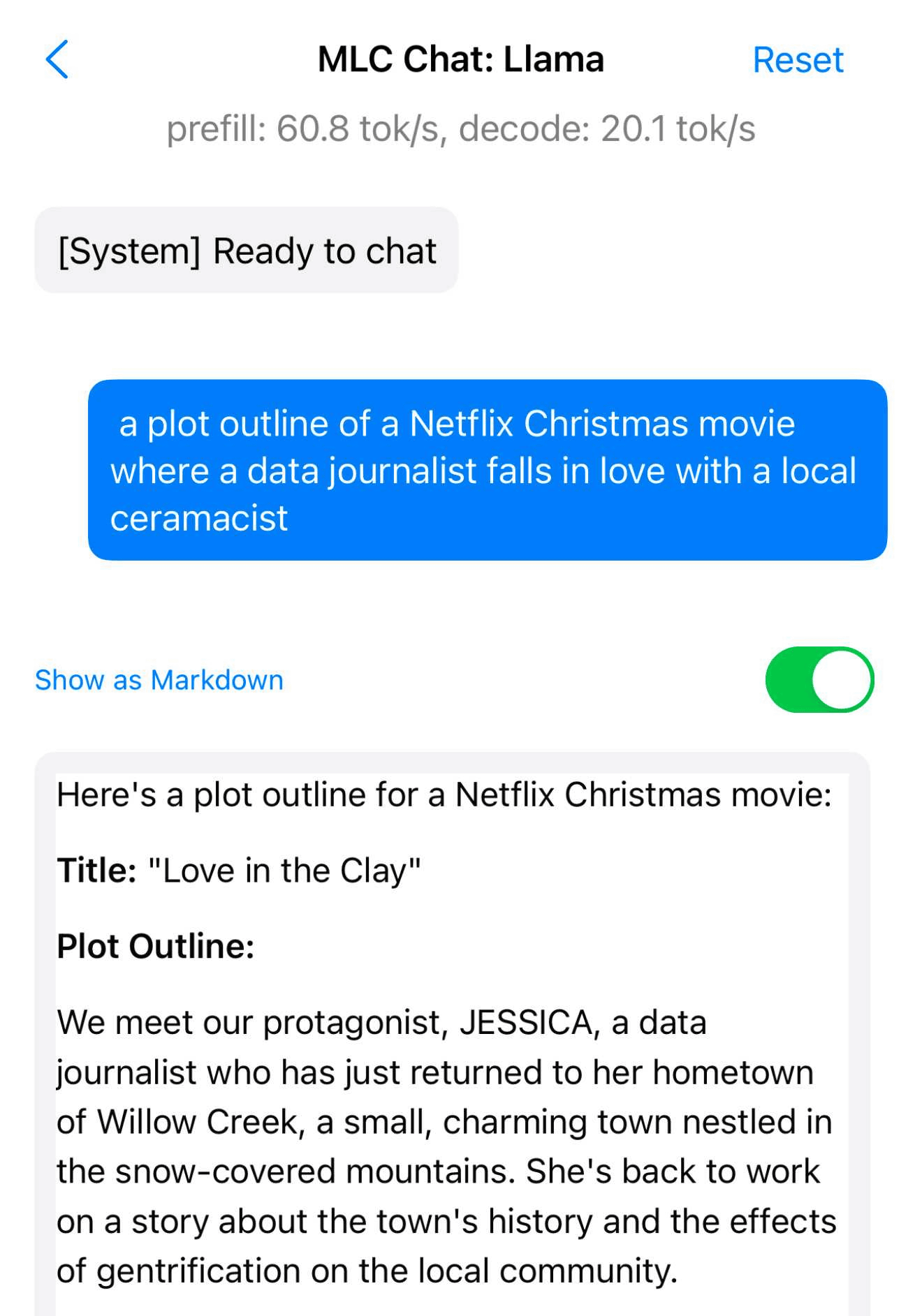
Of particular note is 'Llama 3.2', which Meta released in September 2024. There are multiple models of Llama 3.2, including a small-scale model that can run locally on a smartphone.
Meta releases 'Llama 3.2', with improved image recognition performance and a smaller version for smartphones - GIGAZINE

Regarding the small-scale model of Llama 3.2, Willison wrote, 'Despite the very small data size of less than 2GB, this is surprisingly high performance,' and presented the output when asked 'The plot of a Netflix Christmas movie in which a data journalist falls in love with a local potter.' He praised its high performance.
◆ LLM prices plummet as competition and efficiency increase
As of December 2023, OpenAI was charging $30 (about 4,730 yen) per million input tokens for GPT-4, $10 (about 1,580 yen) for GPT-4 Turbo, and $1 (about 158 yen) for GPT-3.5 Turbo.
However, at the time of writing, OpenAI charges $30 for the most expensive AI model, o1, $2.5 for GPT-4o, and $0.15 for GPT-4o mini.
Other AI models are cheaper: Anthropic's Claude 3 Haiku costs $0.25 per million input tokens, Google's Gemini 1.5 Flash costs $0.075, and Gemini 1.5 Flash 8B costs $0.0375.
Regarding the decline in the price of AI models, Willison wrote, 'The decline in the price of AI models is driven by two factors: increased competition and increased efficiency. Efficiency is crucial to anyone concerned about the environmental impact of LLMs. This price decline is directly related to how much energy is being used to run the prompts. While there are still many concerns about the environmental impact of building large AI data centers, many of the concerns about the energy costs of individual prompts are no longer credible.'
Willison calculated how much it would cost to use a Gemini 1.5 Flash 8B to add a brief description to each of his 68,000 photos. The cost of this process was only $1.68, so Willison wrote, 'I did the calculation three times to make sure it was correct.'
Below is an image of Willison outputting a simple description in Gemini 1.5 Flash 8B, along with an example of the output description.
The shallow dish, probably a hummingbird or butterfly feeder, is red in color. Orange fruit slices are visible in the dish. There are two butterflies in the feeder. One is dark brown or black with white or cream markings, and the other is a large brown butterfly with light brown, beige, and black markings and a prominent eye pattern. The large brown butterfly appears to be feeding on fruit.

'This combination of increased efficiency and falling prices is my favorite AI trend for 2024,' Willison wrote.
◆ Multimodal models become common
In 2024, almost every major AI company released a multimodal model: Anthropic released the Claude 3 series in March 2024, Google released the Gemini 1.5 Pro in April, Mistral released the Pixtral 12B and Meta released the Llama 3.2 in September, Hugging Face released the SmolVLM in November, and Amazon released the Amazon Nova in December.
Amazon announces 'Amazon Nova,' a multimodal generative AI model available on AWS - GIGAZINE

'I think that people who complain that improvements in LLM are lagging are often missing the great advances being made in multimodal models,' Willison wrote. 'The ability to run prompts on images, audio, and video is a fascinating new way to apply these models.'
Prompt-driven app creation is already a commodity
It has already become clear that LLMs are incredibly good at writing code: given the right instructions, they can build complete interactive applications using HTML, CSS, and JavaScript, often with just a single instruction.
Anthropic demonstrates the AI content creation capabilities in Claude 3.5 Sonnet with a feature called “Artifacts,” which allows users to create interactive applications and use them directly within the Claude interface.
You can find out what kind of applications you can create using Artifacts by reading the following article.
Claude 3.5 A summary of examples of apps created with 'Artifacts', a feature that allows you to create interactive single-page apps with Sonnet - GIGAZINE

◆Apple Intelligence is bad, but Apple's MLX library is excellent
Apple announced the machine learning framework 'MLX' for its in-house processor, Apple Silicon, in December 2023. This will help run various LLMs on Macs, and Willison said it's 'a real breakthrough and it's amazing.'
Apple's machine learning team releases MLX, a framework for training and deploying machine learning models on Apple Silicon, on GitHub - GIGAZINE

However, he called Apple's new personal AI, Apple Intelligence, 'mostly disappointing.' Willison said, 'As a power user of LLMs, I know the capabilities of these AI models very well. Apple's LLM feature is a poor imitation of state-of-the-art LLM features. It also misrepresents news headlines and provides completely useless writing assistants. Genmoji is quite fun, though.' He harshly criticized Apple Intelligence.
In addition, the case where Apple Intelligence misrepresented the news headline is summarized in the following article.
Apple Intelligence falsely reports that the murderer of the CEO of a health insurance company was a suicide, and the BBC strongly protests to Apple, Apple Intelligence summary function creates false information - GIGAZINE

◆At the time of writing, the best LLM available was trained in China for less than $6 million (approximately 946 million yen)?
DeepSeek, a Chinese AI company, released the AI model 'DeepSeek-V3' with a parameter size of 671 billion at the end of December 2024. This is the AI model with the largest parameter size among open license models available at the time of writing. It is rated as equivalent to Claude 3.5 Sonnet in benchmark tests and ranked 7th in Chatbot Arena, just behind Gemini 2.0 and OpenAI's GPT-4o and o1. This performance is the highest among open license models.
Chinese AI company DeepSeek releases AI model 'DeepSeek-V3' comparable to GPT-4o, with a threatening 671 billion parameters - GIGAZINE

The great thing about DeepSeek-V3 is that the training costs are overwhelmingly low. The training cost of DeepSeek-V3 is estimated at $5,576,000 (about 879 million yen), and it was trained for 2,788,000 hours using NVIDIA's H800 GPU. Regarding this, Willison wrote, ' The US government's restrictions on exporting GPUs to China appear to have affected effective training optimization.'
Related Posts:



in Software, Posted by logu_ii