``Groq'', which develops ``Language Processing Unit (LPU)'' that operates large-scale language models (LLM) at lightning speed, releases an explosive alpha demo

A company called Groq may have pushed AI chips to the next level
https://www.androidheadlines.com/2024/02/openai-groq-ai.html

Forget ChatGPT — Groq is the new AI platform to beat with blistering computation speed | Tom's Guide
https://www.tomsguide.com/ai/forget-chatgpt-groq-is-the-new-ai-model-to-beat-with-blistering-computation-speed
Groq is an AI company based in Mountain View, USA that has developed high-performance processors and software solutions for AI, machine learning, and high-performance computing applications. Although the name is very similar to Grok , an AI chatbot developed by Elon Musk's AI company xAI, it is completely different.
AI tools typically perform calculations using GPUs that are optimized for parallel graphics processing. This is because GPUs can perform calculations quickly and are generally very efficient at doing so. For example, GPT-3, an LLM, works by using a GPU to analyze a prompt and make a series of predictions about what words will come before and after it.
In contrast, the LPU being developed by Groq is a chip designed to run existing LLMs at lightning speed, and is designed to process a series of data (DNA, music, code, natural language, etc.). Because it is specially designed, it can deliver much better performance than GPUs.
Wow, that's a lot of tweets tonight! FAQs responses.
— Groq Inc (@GroqInc) February 19, 2024
• We're faster because we designed our chip & systems
• It's an LPU, Language Processing Unit (not a GPU)
• We use open-source models, but we don't train them
• We are increasing access capacity weekly, stay tuned pic.twitter.com/nFlFXETKUP
Although Groq is not developing its own LLM, it has released an alpha demonstration that uses existing LLMs to run LLMs up to 10 times faster than GPU-based processing.
Groq
https://groq.com/
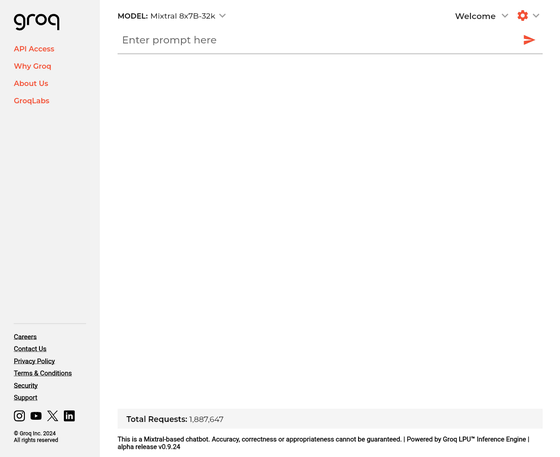
It's easy to use, just enter your text in 'Enter prompt here' at the top of the screen and click the paper airplane icon.

Then, the answer and the time taken to output the answer (285.52T/s) will be displayed.

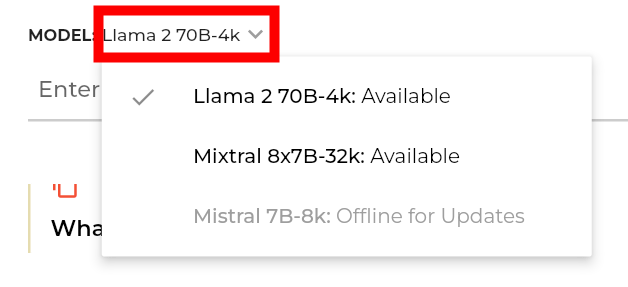
In addition, in the Groq demonstration, you can use either 'Llama 2 70B' developed by Meta or 'Mixtral 8x7B' developed by Mistral AI, and you can switch the model from the top left of the screen.
Related Posts:







in Web Service, Hardware, Posted by logu_ii