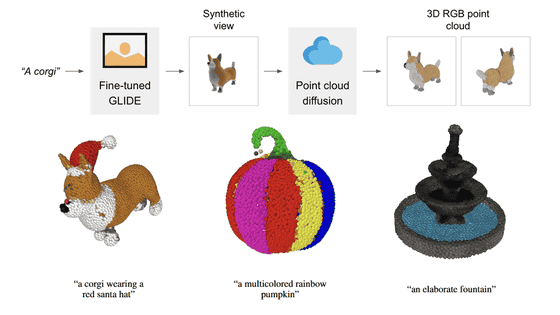
NVIDIA announces high-precision image generation AI 'eDiffi', enabling image generation that is more faithful to text than conventional 'Stable diffusion' and 'DALL E2'

[2211.01324] eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
https://arxiv.org/abs/2211.01324
eDiff-I: Text-to-Image Diffusion Models with Ensemble of Expert Denoisers
https://deepimagination.cc/eDiffi/
Nvidia's eDiffi is an impressive alternative to DALL-E 2 or Stable Diffusion
https://the-decoder.com/nvidias-ediffi-is-an-impressive-alternative-to-dall-e-or-stable-diffusion/
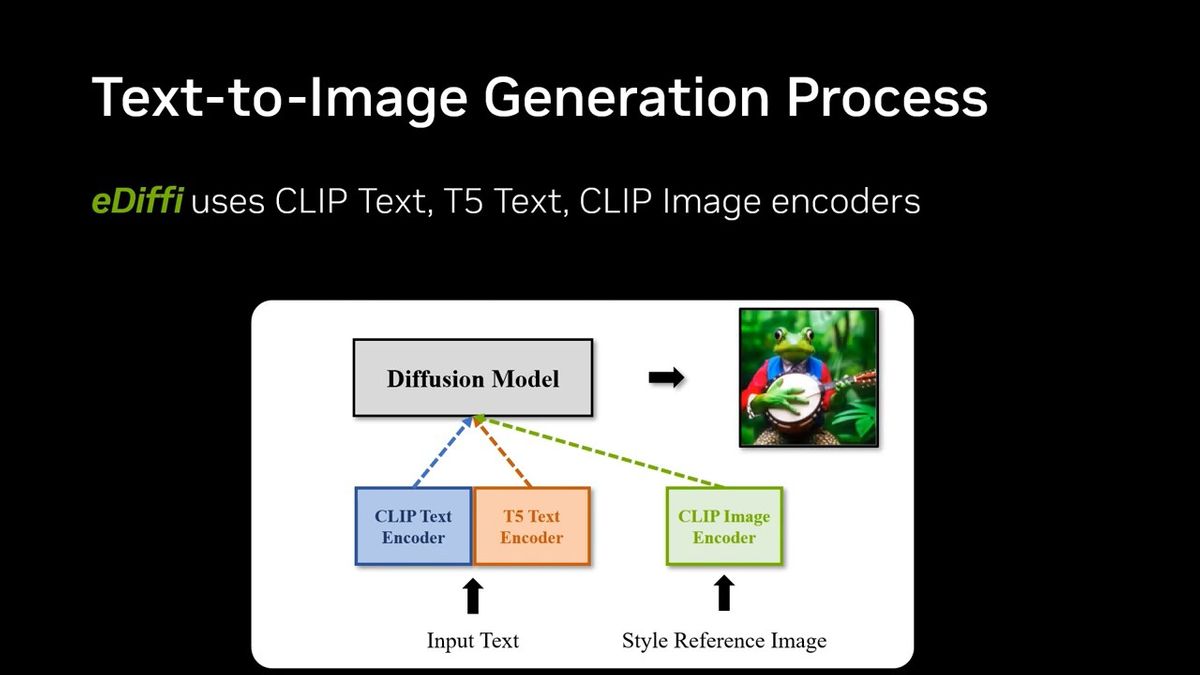
eDiffi, which generates images based on input text, uses an image generation process called ' diffusion model ' that is also used in Stable Diffusion and DALL E2. Diffusion models generate images by repeating the process of removing noise from a noise-only image and finally producing a clean image.
The difference between conventional image generation AI and eDiffi is that normal image generation AI trains with a single denoising model (denoiser), while eDiffi trains with different denoisers for each stage of denoising. It's a point. As a result, it is possible to generate images with higher accuracy than conventional image generation AI.
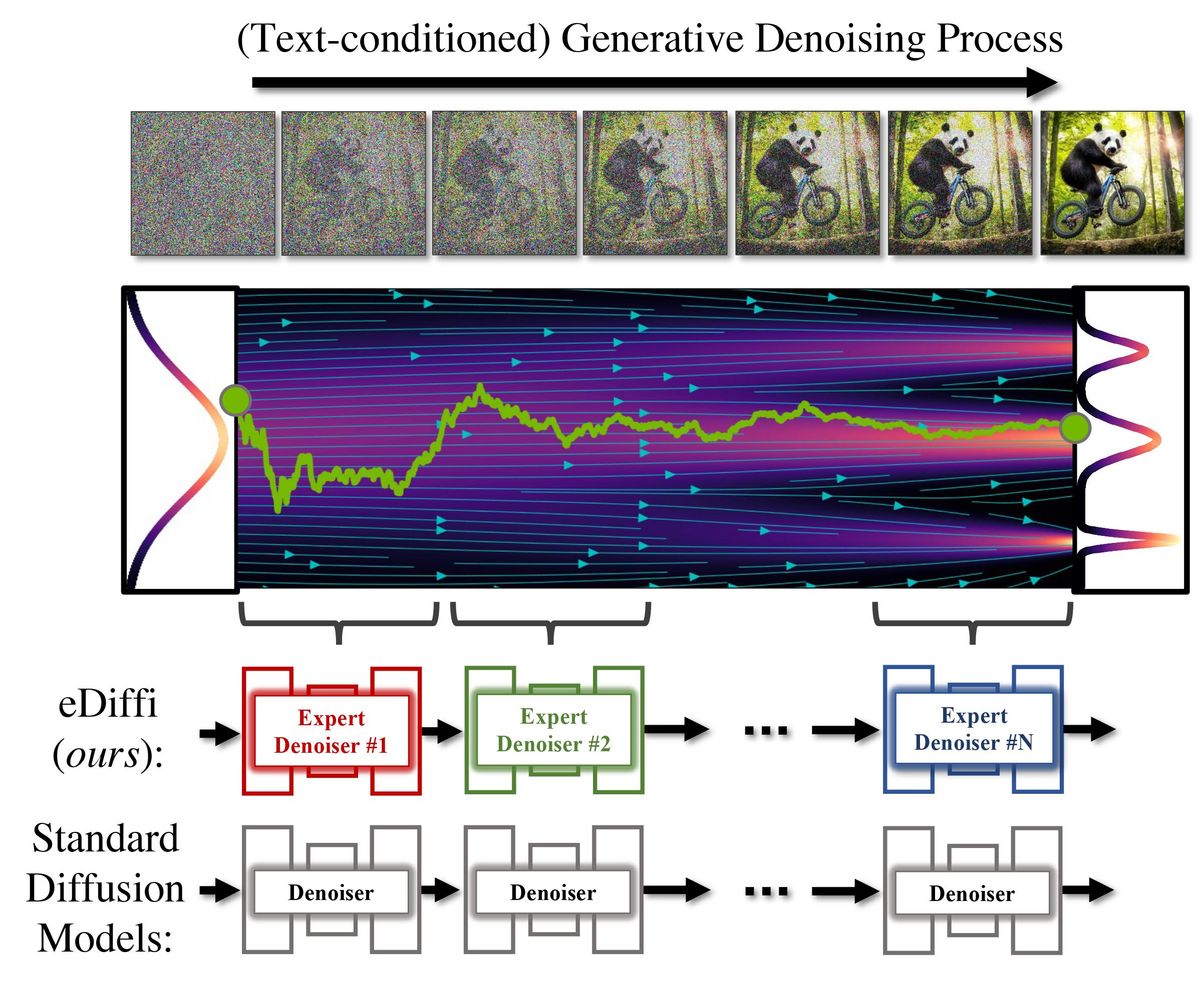
You can see how accurate eDiffi's image generation is by watching the following video.
Below, from the left, ``Digital painting of a very detailed portal in a mysterious forest with beautiful trees.A person is standing in front of the portal.''``A cat wearing a witch's hat at a haunted house. A high-definition zoomed digital painting of a woman dressed as a witch. Image generated by eDiffi based on the text 'Sinking'. All images are of high quality and faithfully reflect the text instructions.

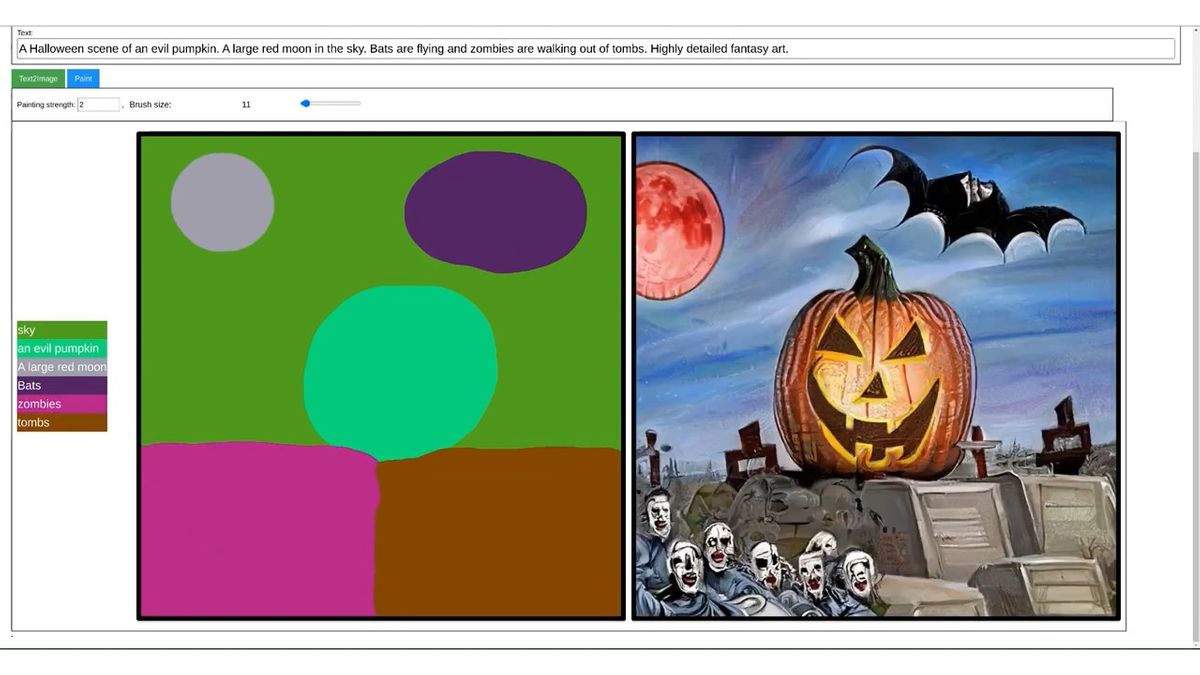
You can also combine text instructions with simple paint instructions to generate images with the exact composition you envisioned.
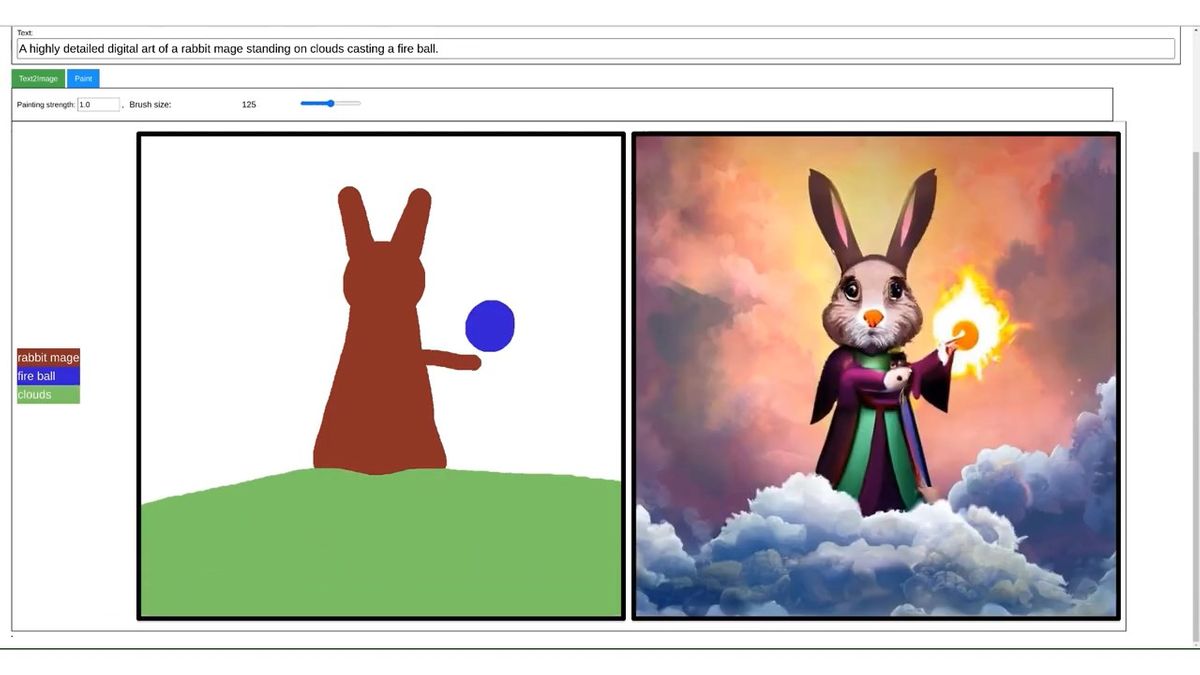
You can also generate images in your favorite style by specifying an image to refer to in style separately from the text.


Compared to existing image generation AI, eDiffi can generate images that are more faithful to text instructions. Below is a photo of a golden retriever puppy in a green shirt. The shirt has the text NVIDIA rocks.The background is an office.4K, DSLR camera. A sequence of images generated by Stable Diffusion, DALL E2, and eDiffi. Both can reproduce up to the point where the golden retriever puppy is wearing a green shirt, but only eDiffi has the word 'NVIDIA rocks' accurately written.

The image generated with the text ``There are two Chinese teapots on the table. One pot has a dragon picture and the other has a panda picture.'' The image is as follows. Again, only eDiffi can recognize the panda drawing.

When I tried it with the text 'Photo of a dog in a blue shirt and a cat in a red shirt sitting in a park, photo-realistic, SLR camera', only eDiffi could reproduce the dog in the blue shirt It seems that I was able to do it.

eDiffi combines Google's natural language processing model '
Related Posts: