NVIDIA's image generation AI 'eDiffi' realizes 'paint with words' that generates images with words and paint with image generation AI 'Stable Diffusion'

'
GitHub - cloneofsimo/paint-with-words-sd: Implementation of Paint-with-words with Stable Diffusion : method from eDiffi that let you generate image from text-labeled segmentation map.
https://github.com/cloneofsimo/paint-with-words-sd
You can understand what kind of model eDiffi is by reading the following article.
NVIDIA announces high-precision image generation AI 'eDiffi', enabling image generation that is more faithful to text than conventional 'Stable diffusion' and 'DALL E2'-GIGAZINE

Stable Diffusion is an AI model called 'diffusion model' as its name suggests, and generates images by repeating the process of removing noise from images with only noise. Stable Diffusion performs this noise removal with a single model, but eDiffi features noise removal with different models at each stage.
eDiffi's paper and method are not open source, and the model is not open to the public, so it cannot be used as it is, but the part called 'Cross-attension' that interrupts the simple combination of noise removal from the contents of the prompt is common with Stable Diffusion Since it is doing, paint-with-words was able to be implemented.
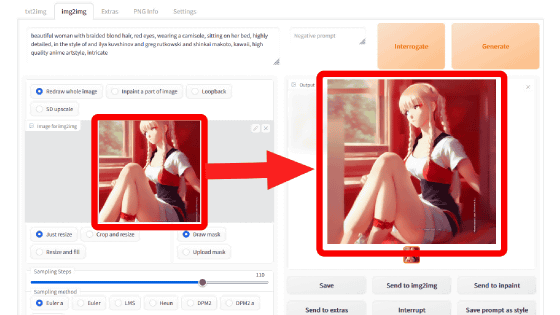
Below, on the left of the image is the prompt 'A highly detailed digital art of a rabbit image standing on clouds casting a fire ball'. The leftmost of the three images is the paint that dictates the composition of the image. The image in the middle is an image generated only by Stable Diffusion by sending instructions with this prompt and paint image. And the image on the far right introduces the same processing as eDiffi, which adjusts the weight of 'Attension' that directs noise removal by prompt.

'A dramatic oil painting of a road from a magical portal to an abandoned city with purple trees and grass in a starry night. The following is the case generated by 'dramatic oil painting)'.

Below is an array of images (right) generated with the same prompt with only the paint image (left) changed. The only difference in the painted image is the position of the moon. The aurora displayed in the background is slightly different from the moon, but the mountain range and the boat underneath are almost the same.

The stronger the attention weighting adjustment, the more faithful the image is produced to the original prompt and composition. However, the image quality will be reduced accordingly. In the image below, the weight adjustment is stronger as it goes to the right, and the composition is faithful to that of the painted image, but the generated rabbit noise has increased.

The following is the same prompt paint image as the image above, generated by changing the function of weight adjustment and the variable corresponding to strength.

Mr. Simo Ryu , the owner of paint-with-words-sd, is also interested in developing it as an extension of the AUTOMATIC 1111 version of Stable Diffusion web UI.
Extensions for Automatic1111 version? Issue #1 cloneofsimo/paint-with-words-sd GitHub
https://github.com/cloneofsimo/paint-with-words-sd/issues/1
Related Posts:





in AI, Software, Creation, Web Application, Posted by log1i_yk