




大規模言語モデルを単一ファイルで配布・実行する「llamafile」のバージョン0.7で処理能力が最大10倍高速化

大規模言語モデル(LLM)をわずか4GBほどの実行ファイル1つで手軽に配布・実行できるようにしたパッケージ「llamafile v0.7」が公開されました。このバージョンではCPUとGPU両方の計算性能と計算精度が向上しており、命令セットアーキテクチャ「AVX-512」のサポートにより、AMDの「Zen4」アーキテクチャ採用CPUなどでプロンプト処理時間が10倍高速化されるとのことです。
Release llamafile v0.7 · Mozilla-Ocho/llamafile · GitHub
https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.7
Llamafile 0.7 Brings AVX-512 Support: 10x Faster Prompt Eval Times For AMD Zen 4 - Phoronix
https://www.phoronix.com/news/Llamafile-0.7
LLaMA Now Goes Faster on CPUs
https://justine.lol/matmul/
「llamafile」は、ほとんどのシステムで実行可能な単一ファイルでLLMを提供することで、開発者やエンドユーザーがLLMを簡単に配布・利用できるようにする仕組みです。
わずか4GBの実行ファイル1つで大規模言語モデルによるAIを超お手軽に配布・実行できる仕組み「llamafile」をWindowsとLinuxで簡単に実行してみる方法 - GIGAZINE

現地時間の2024年3月31日にリリースされた「llamafile v0.7」では、CPUでのプロンプト処理速度が大きく向上していることが報告されています。
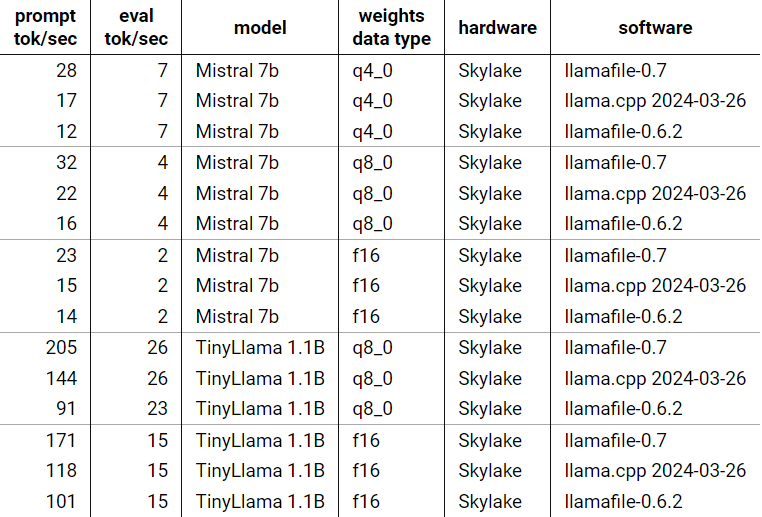
技術者のジャスティン・タニー氏は「llamafile v0.7」と「llamafile v0.6.2」およびllamafileにも含まれる高速化ツールである「llama.ccp 2024-03-26」を実行し、処理速度の違いを示しています。
タニー氏の手元にあったという2020年製のHP端末(Intel Core i9-9900搭載)の場合の実行結果が以下。さまざまなモデルやパラメータで実行した結果、llamafile v0.7が優れた結果を示したことがわかります。
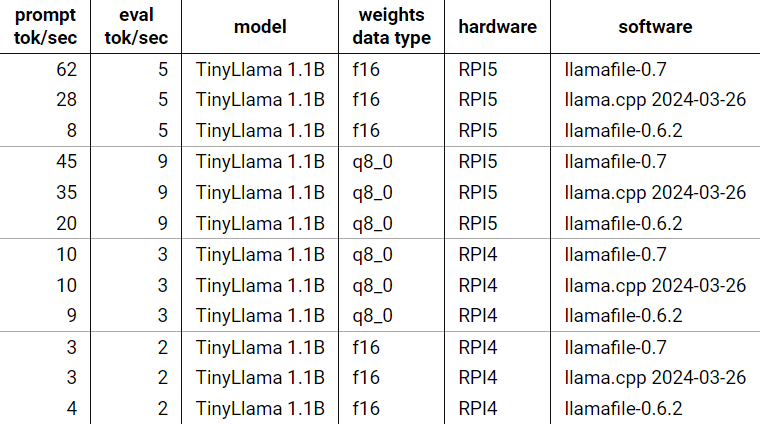
また、タニー氏はRaspberry Pi v5(ARMv8.2)とRaspberry Pi v4(ARMv8.0)での実行結果も示しています。Raspberry Pi v5では前バージョンと比較して、最大で8倍近い差がついています。
リリースによると、llamafile v0.7はIntelの命令アーキテクチャ「AVX-512」をサポートしたことにより、Zen4アーキテクチャなどの環境では、処理速度が10倍高速になるとのことです。
・関連記事
Metaが商用可能な大規模言語モデル「Llama 2」を無料公開、MicrosoftやQualcommと協力してスマホやPCへの最適化も - GIGAZINE
Metaが大規模言語モデル「LLaMA」を発表、GPT-3に匹敵する性能ながら単体のGPUでも動作可能 - GIGAZINE
コマンド不要でLLMのダウンロードから会話までを実行できる無料チャットAIアプリ「Jan」を使ってみた - GIGAZINE
・関連コンテンツ




in ソフトウェア, Posted by logc_nt
You can read the machine translated English article Version 0.7 of ``llamafile'', wh….