




ムービー内の動きをたった1枚の写真に反映して写実的なムービーを作り出すAIが開発される

GPUやAIの開発で知られるNVIDIAの研究チームは、「ムービー内の動きをたった1枚の写真に反映し、写実的なムービーを作り出すAI」を開発したと発表しました。
Few-shot Video-to-Video Synthesis
https://nvlabs.github.io/few-shot-vid2vid/
近年ではAI技術の発達により、ムービーや写真などのデータセットから新たに架空のムービーや写真を作り出すなど、さまざまなことが可能となっています。しかし、既存のモデルでは、対象となる被写体に関する多くのデータセットが必要であり、学習したモデルが他の対象に広く一般化しにくいという問題もありました。そこでNVIDIAの研究チームは、「インプットされたムービー内の動きだけを抽出し、これまでモデルが学習していない1枚の写真と合成して写実的なムービーを作り出すAI」を開発したとのこと。
新たに開発されたAIがどのようなものになっているのかは、以下のムービーを見るとよくわかります。
Few-Shot Video-to-Video Synthesis (NeurIPS 2019) - YouTube

画面の左に表示されているのは、あらかじめモデルにインプットされた、抽象的な動きを表すムービーです。1番上のムービーでは棒人間がダンスを踊り、2番目では線で描かれた顔が何かを話しており、3番目では道路を進む車から見える風景が表されています。

これらのムービーと「example」というキャプションの下にある写真を、研究チームが開発したモデルを利用して組み合わせると……
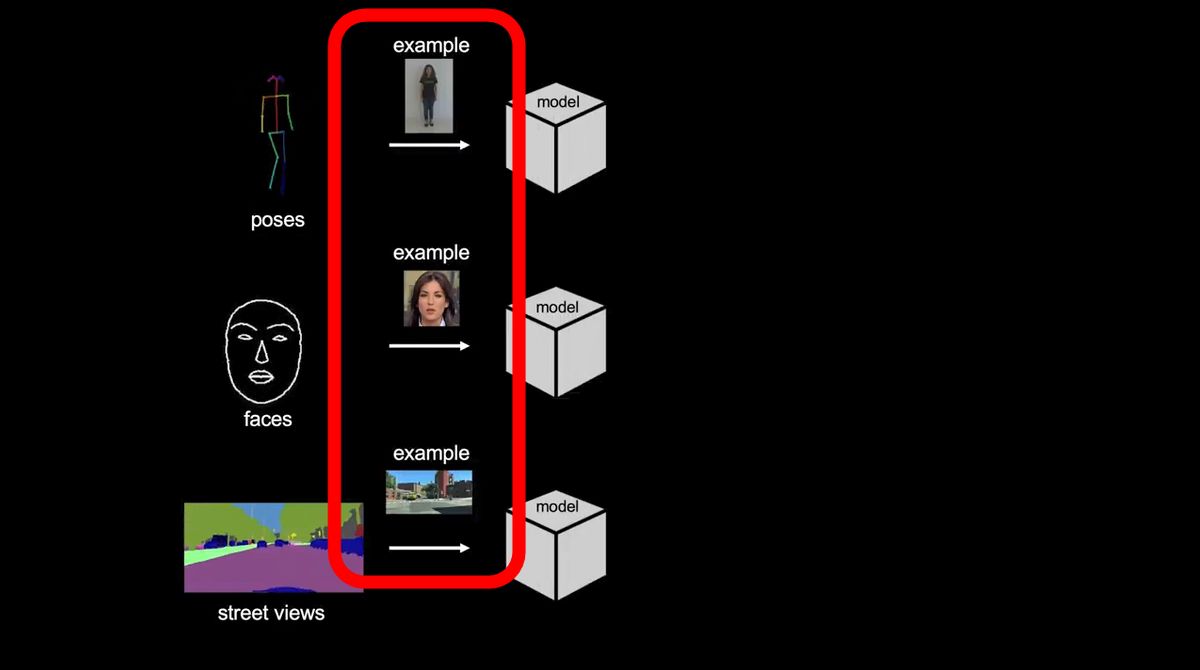
写真の中の人物や風景が抽象的なムービーで表された動きと合成されて、写実的なムービーとなりました。
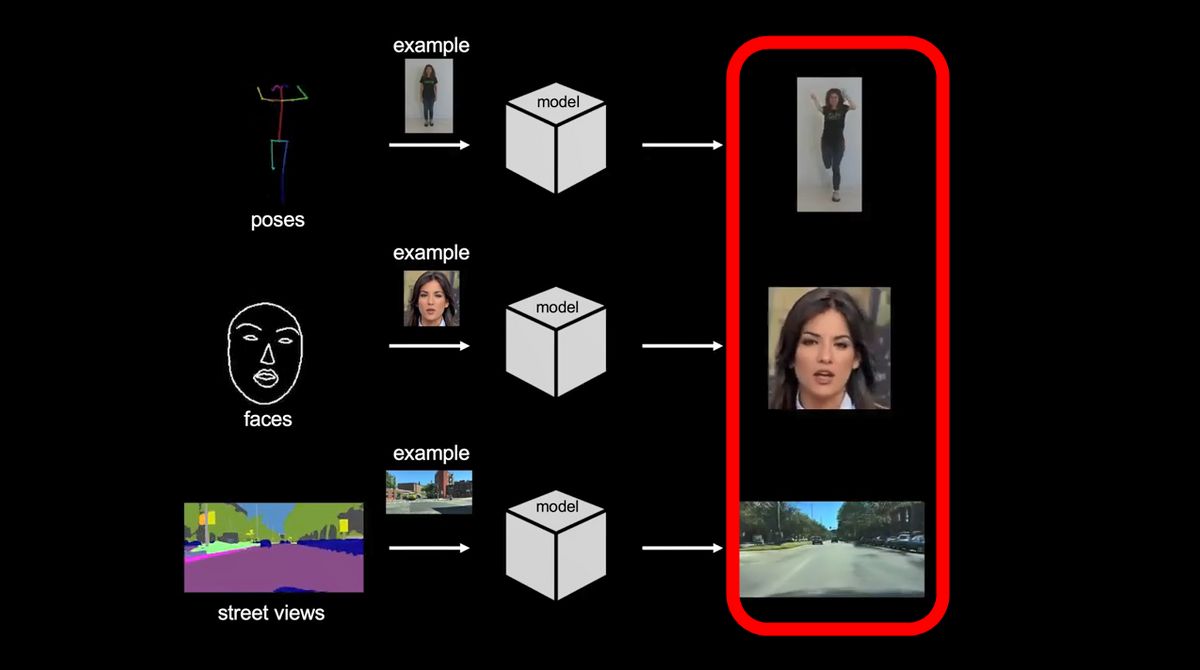
出力されたムービー内の人物はほとんど違和感なく踊ったり喋ったりしており、元データがたった1枚の写真しかないとは思えません。
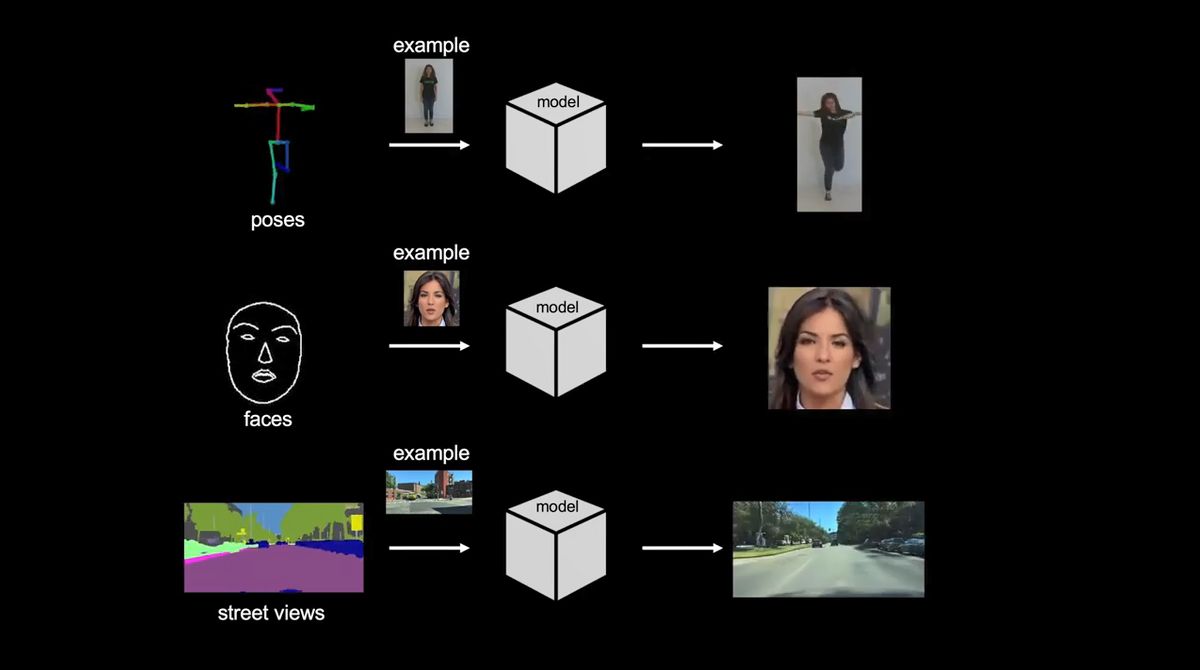
また、入力する画像を別のものに差し替えると……
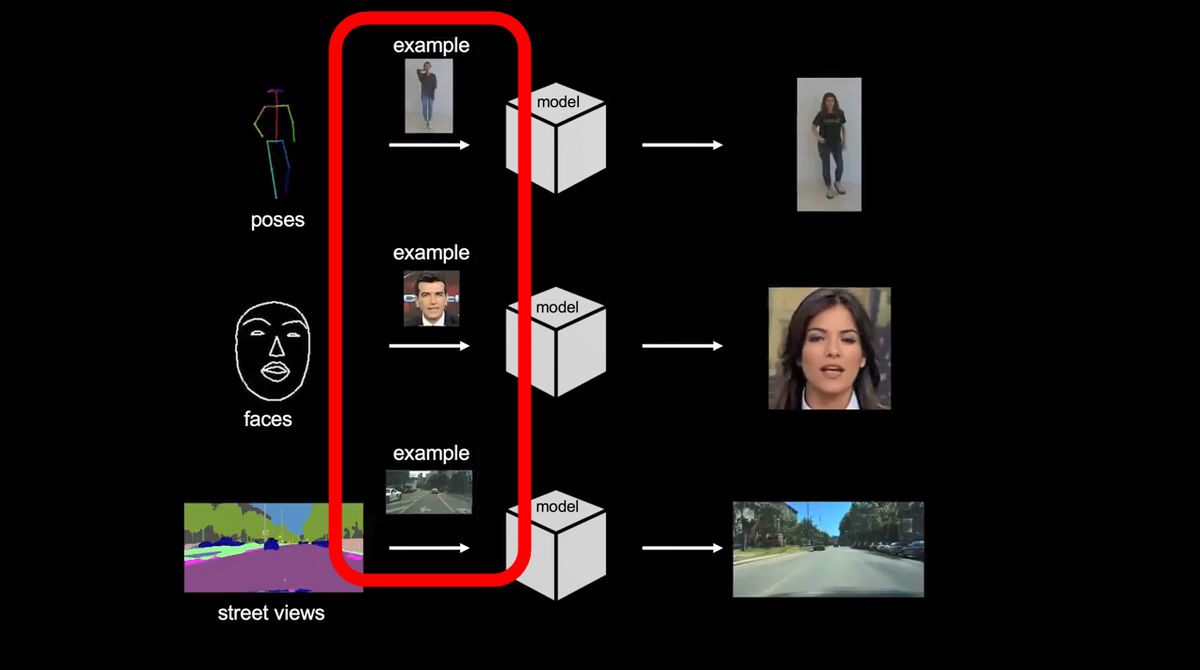
出力されるムービーも、違う人物や風景になりました。このモデルでは、インプットした単純なムービーを元にして、多くの別の写真と合成して新たなムービーを作ることができるというわけ。

入力する画像がそれぞれ違うポーズや人であっても……

インプットしたムービーと同じように滑らかなダンスを踊ります。

また、動きをインプットするムービーは必ずしも抽象的なものである必要はなく、実写のダンスムービーをミケランジェロのダビデ像の画像と組み合わせることもできます。彫刻がくねくねとダンスを踊ったり跳ねたりする様子はかなりシュールです。

また、人の顔写真をニュースリポーターのムービーと合成し……

顔写真の人物が滑らかに話すムービーを作ることも可能。

入力する画像をモナ・リザなどの絵画にして、絵画の人物が話すムービーを作ることもできます。

また、抽象的なムービーを現実世界の風景写真と組みあわせることもできます。1番左のインプットしたムービーには、それぞれの物体や建物に関する具体的な情報が何もありませんが、exampleの画像から推測して実写のようなムービーを出力することができるとのことです。

・関連記事
「動物の表情を別の動物に当てはめるAI」をNVIDIAが開発、デモ用のウェブサイトも公開中 - GIGAZINE
NVIDIAが深層学習でX線写真の分析をサポートする医療用AIキット「Clara」を開発 - GIGAZINE
落書きをリアルな風景写真にリアルタイムで変換できる驚異的なお絵かき技術「GauGAN」をNVIDIAが発表 - GIGAZINE
AIでリアル映像から3DCGのバーチャル世界を生成する方法をNVIDIAが公開、3D環境構築のコストが大幅カット可能に - GIGAZINE
リアル写真と判別不能なレベルの偽画像をAIが生成可能になるGANs向けアーキテクチャをNVIDIAが作成 - GIGAZINE
AIが人間の行動を観察するだけで同じ行動を模倣する技術をNVIDIAが公開 - GIGAZINE
「ディープラーニングを用いて通話時のノイズを抑える」という試みにNVIDIAが挑戦している - GIGAZINE
ディープフェイクで人造したFacebookのザッカーバーグCEOが「データの支配」について語るムービーが話題に - GIGAZINE
・関連コンテンツ








in 動画, ソフトウェア, Posted by log1h_ik
You can read the machine translated English article AI will be developed that reflects the m….