




Samsungが1枚の写真や絵画からリアルな会話アニメーションを作成できる技術を開発

モスクワにあるSamsungの人工知能(AI)センターとロシア・スコルコヴォ科学技術研究所の技術者が、従来の3Dモデリングのような手法を使わずに、画像から人が話している様子のアニメーションを生成できるモデルを開発しました。この技術は将来的にゲームやビデオ会議で使われるデジタルアバターへの応用が期待されます。
[1905.08233v1] Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
https://arxiv.org/abs/1905.08233v1
Samsung's AI animates paintings and photos without 3D modeling | VentureBeat
https://venturebeat.com/2019/05/22/samsungs-ai-animates-paintings-and-photos-without-3d-modeling/
どんな技術なのかは、以下のムービーを見ると一発でわかります。
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models - YouTube
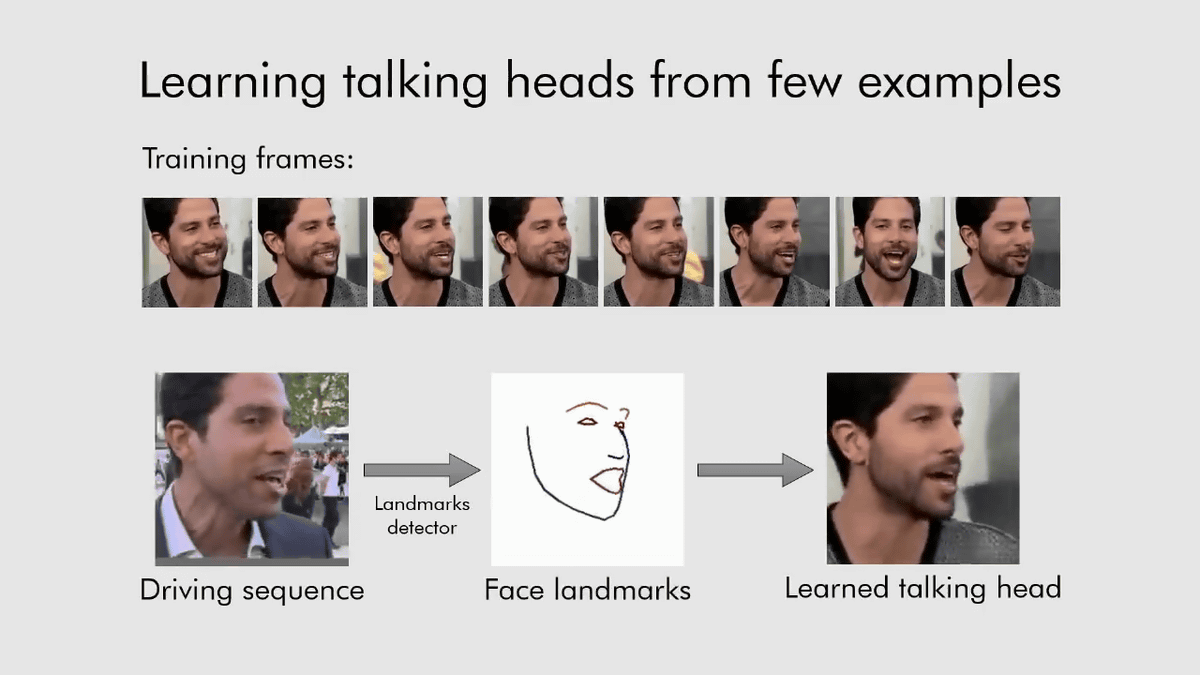
Samsungが開発した「画像から人が話している様子のアニメーションを生成できるモデル」は、数枚の画像を基に訓練を行うことで、全く新しい「人間が会話している映像」を生成することができるというもの。例えば以下の場合、8枚の画像(上)をモデルに学習させ、会話映像の元となるムービー(Driving Sequence)を入力すると、元ムービーから眉・目・鼻・口・顎のラインだけで構成されたフレームを抽出し、学習した画像にフレームの動きを合わせることで「全く新しい会話映像」を生成しています。
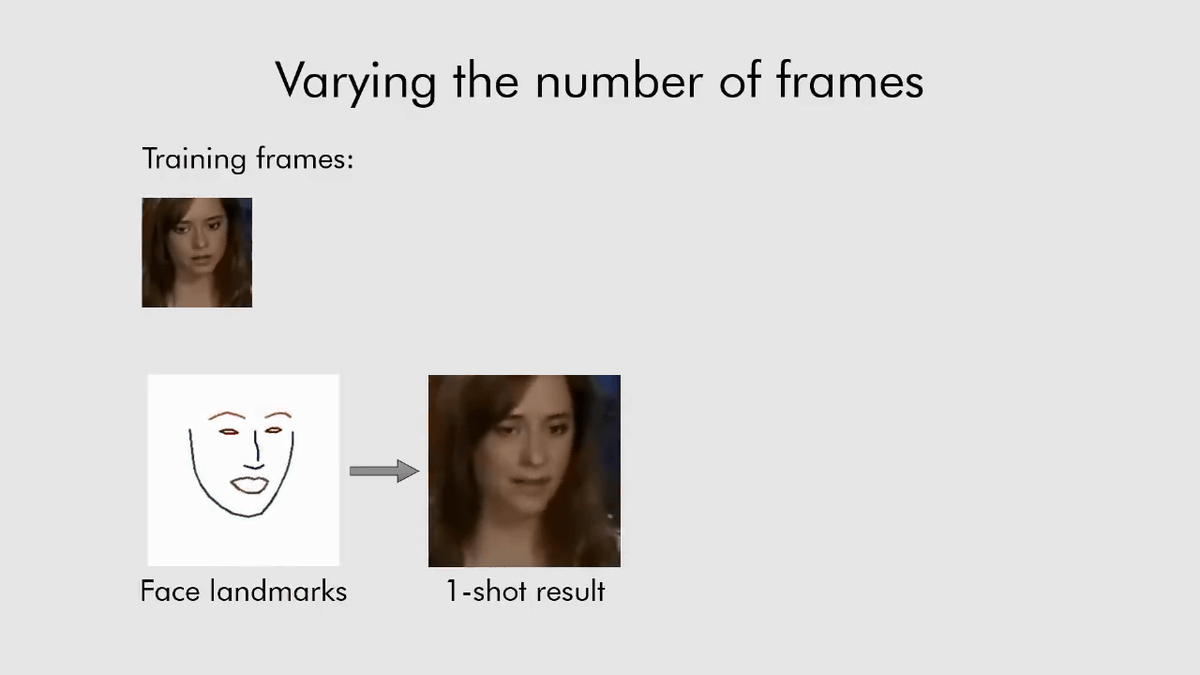
従来のモデルであれば、膨大な画像データを訓練に必要としますが、Samsungとスコルコヴォ科学技術研究所が開発したモデルはたった1枚の写真からでもアニメーションを生成することが可能。
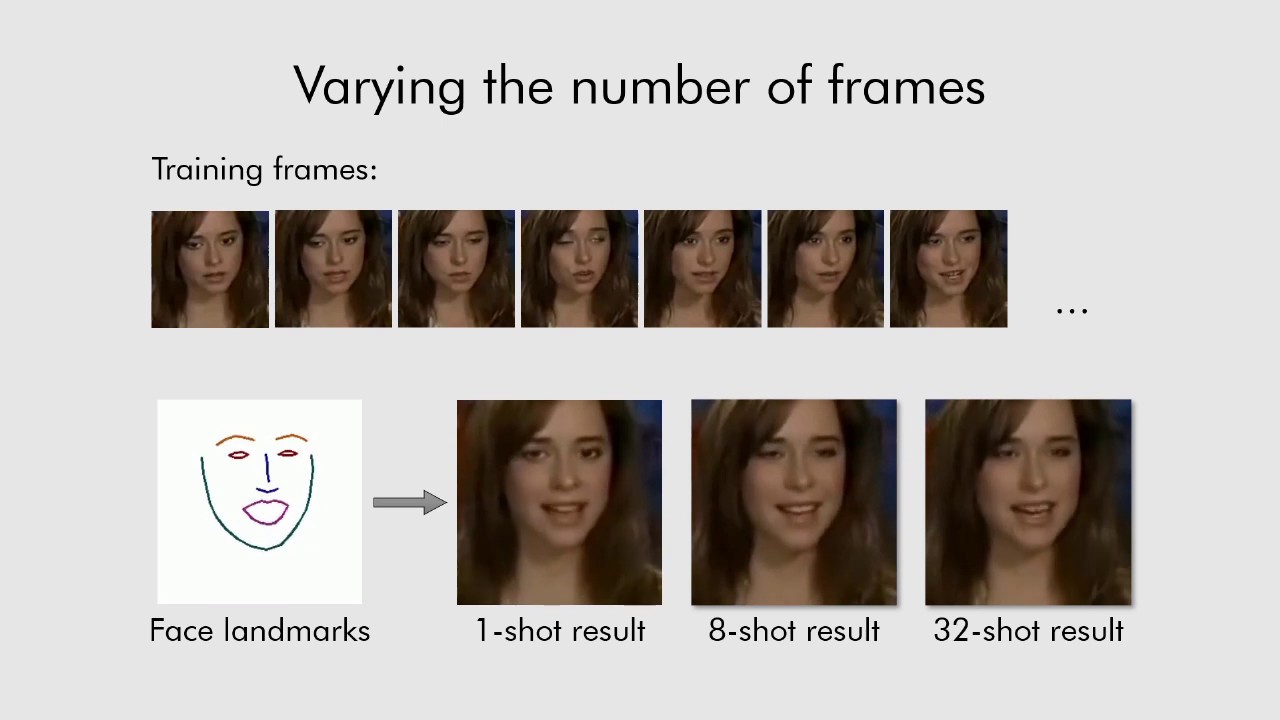
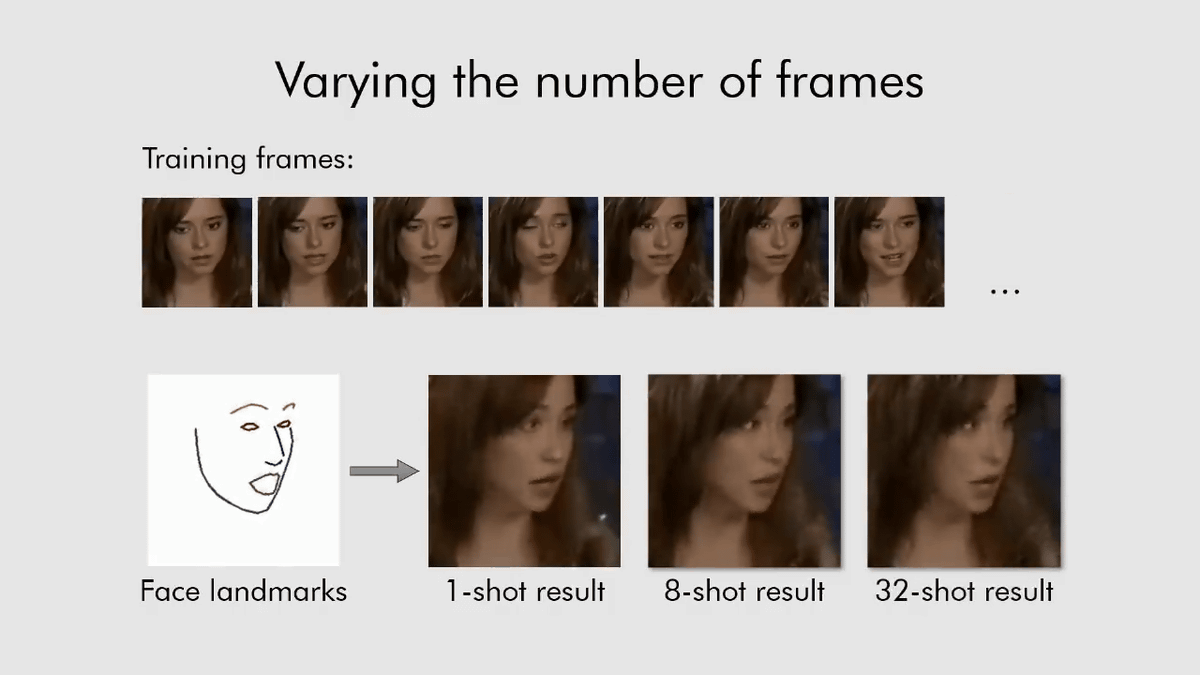
もちろん、8枚、32枚と訓練データを増やせば増やすほど、アニメーションの動きは細かくなるといえますが、ムービーを見ていると、その動きに大きな違いはなく、1枚からでもかなり自然な会話アニメーションを生成できているのがわかります。
メタ学習の段階では、「埋め込みネットワーク」「生成ネットワーク」「弁別ネットワーク」の3つのニューラルネットワークを、大規模なビデオデータセットに基づいて訓練します。
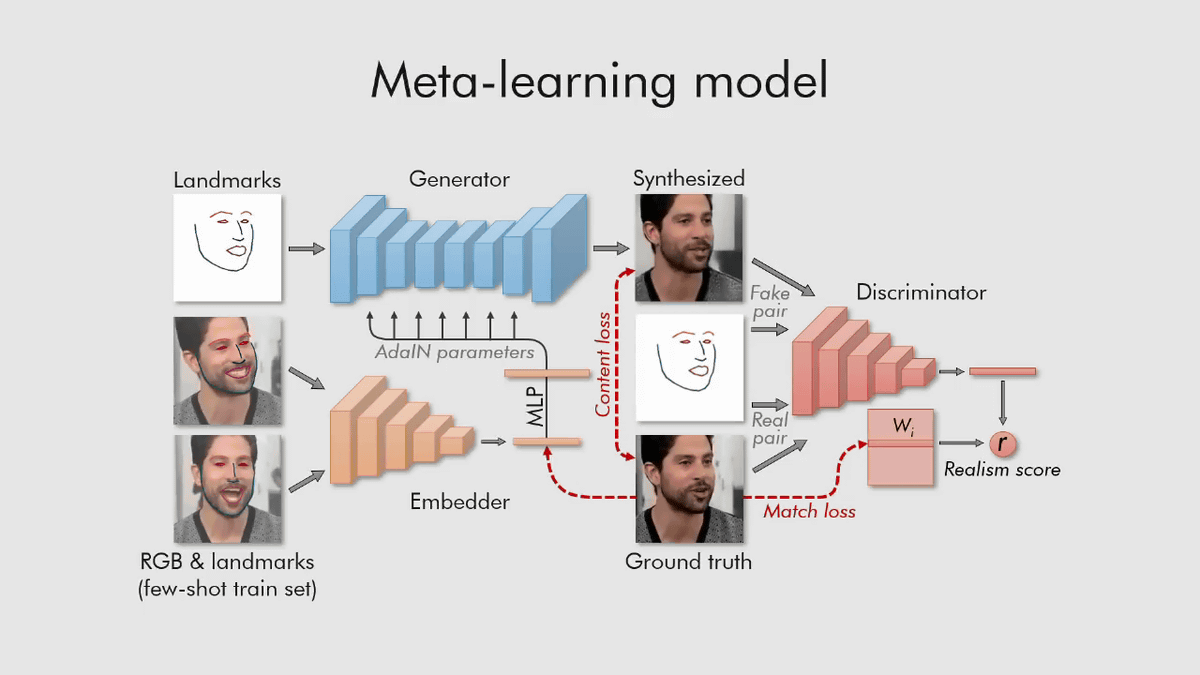
そして、少数ショット学習では、生成ネットワークと弁別ネットワークのパラメータを固有の方法で初期化することによって、ほんの数枚、あるいはたった1枚の画像に基づいて数千万のパラメータを調整し、スピーディーに敵対的訓練を行うことができるとのこと。
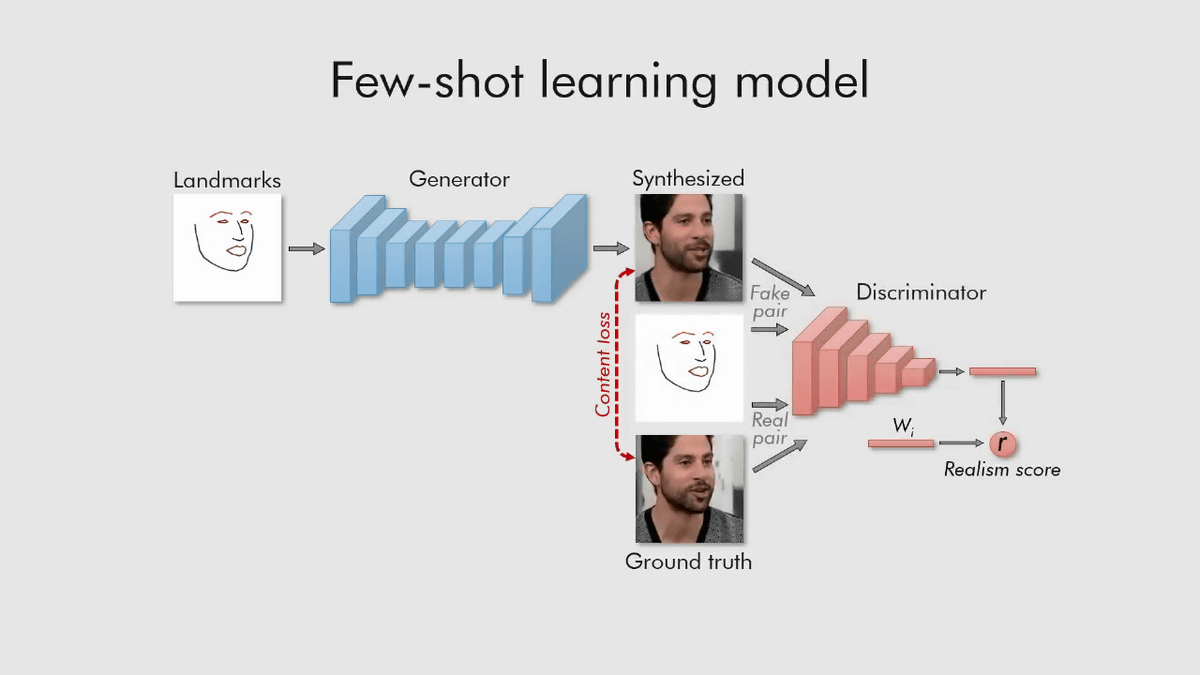
数枚の画像さえあれば、顔パーツのフレームに合わせたスムーズな会話アニメーションが生成できるので、自撮りから取得したフレームを元に新しい会話アニメーションを生成するということも可能になります。

また、1枚の画像データからでもアニメーションの生成が可能なので、例えばマリリン・モンローや……

サルバトール・ダリ

フョードル・ドストエフスキー

アルバート・アインシュタインなど、偉人の肖像写真から自由に会話アニメーションを生成することも可能です。

さらにムービーでは、イワン・クラムスコイの「見知らぬ女」や……

レオナルド・ダ=ヴィンチの「モナ・リザ」など、写真だけではなく人物画からもアニメーションを生成していました。

・関連記事
30年前に死んだ画家のダリがAI技術を使って驚異の復活、「ダリは生きていた」と言えそうな完成度のムービーが公開中 - GIGAZINE
若きハン・ソロにハリソン・フォードをAIが割り当てたディープ・フェイク・ムービーが登場 - GIGAZINE
蒸留所がMicrosoftと提携して世界初の「AIウイスキー」が爆誕、人工知能がフレーバーなどのレシピを考案 - GIGAZINE
無料で「ディズニー風ゴッドファーザーのテーマ」などAIに曲の雰囲気を指示して簡単に作曲できる「MuseNet」を使ってみた - GIGAZINE
MicrosoftがAIで非実在のアート画像を無料で生成できるウェブサイトを公開 - GIGAZINE
・関連コンテンツ






in 動画, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article Develops technology that enables Samsung….