




AIを駆使する最先端で高収入な「データサイエンティスト」になるためには?ホンモノのデータサイエンティスト・齊藤秀氏に根掘り葉掘り聞いてみた
いつでもどこでも好きな時に好きな場所で、ビジネス・IT・デザインなどさまざまなテーマに関するスキルを学ぶことが可能なオンライン動画学習講座が「Udemy(ユーデミー)」です。世界で1700万人以上が利用しており、公開されている講座の数はなんと5万5000件以上もあるので、過去にはGIGAZINEでも最近流行りの機械学習についてUdemyで学習してみたこともあります。そんなUdemyに新しく「データサイエンティスト」のための入門講座が開設されるということで、そもそもデータサイエンティストとは何ぞや?ということを、日本のデータサイエンス分野の第一人者であり、新しく開設される入門講座の監修を務めた齊藤秀氏に直撃取材してきました。
世界最大級のオンライン教育プラットフォーム | Udemy
近年注目されているディープラーニングや人工知能(AI)などは、「データサイエンティスト」という職種に就く人々が膨大なデータを処理することで、自動運転車を開発することや高度な画像認識アルゴリズムを組み上げることなど、さまざまな分野に応用しています。世界的に注目を浴びる職種ではあるものの、日本では「一体どんな仕事してるの?」という人も多いはず。そんなわけでやってきたのは、東京某所にあるオプトのオフィス。

なぜオプトにやってきたのかというと、ここには日本のデータサイエンス分野の第一人者であり、オプトCAO(Chief Analytics Officer:最高分析責任者)というデータサイエンティストならではの職に就いている齊藤秀氏がいるから。そんなわけで、「データサイエンティストとは何ぞや?」という部分について、齊藤氏に根掘り葉掘り聞いてきました。

・目次
◆1:国内外のデータサイエンティスト事情
◆2:そもそもデータサイエンティストに向いている人材とは?
◆3:データサイエンティストに必要なスキルとは?
◆4:データサイエンスの活用事例
◆5:なぜデータサイエンティストは高給なのか?
◆6:データサイエンティストを目指す上で持っておくべき心構え
◆7:データサイエンティストを目指す人向けの入門講座
◆1:国内外のデータサイエンティスト事情
GIGAZINE(以下、G):
まず初めに、日本のデータサイエンス分野では人材育成などに様々な課題があると伺ったのですが、齊藤さんから見て、日本のデータサイエンスを取り巻く現状ってどのような感じなのでしょうか?
株式会社オプトCAO 齊藤秀(以下、齊):
そもそも、今ビッグデータが人気になり、AIが話題となっていて、これはアメリカでも日本でも変わりません。ただ、なかなかスピードが上がらないという問題は大企業も国もみんなが抱いていて、その中で一つ言い訳にしているのが「うまくいかないのはいい人がいないからだ」と言っているんです。なぜ「人がいない」のかというと、現時点ではビッグデータを扱ったりする人材である「データサイエンティスト」を教育するためのシステムが存在しないからです。もちろん、文部科学省から東京大学や京都大学といった有力校に向けて「データサイエンスの教育をしなさい」という指示がされるようにはなっていて、2017年もデータサイエンス教育は大きく進んだと思います。また、2018年からはさらに本格的にさまざまなプロジェクトが進行するという段階に入っています。ただ、アメリカではもっと進んでいて、民間団体などが積極的にデータサイエンスの教育ビジネスをスタートしていて、みんながお金を払って勉強しに行っています。その結果としてFacebookやGoogleといった有力企業に就職したり給料が急激に上がったりしています。例えば、「高速データ分析に適したScalaやSparkなどの技術が使えると、年収が170万円上がる」というような統計結果も出ているんです。
G:
すごく露骨ですね。
齊:
僕もアメリカへ行って見てきたのですがすごく露骨で、かつ具体的でした。20代から30代を中心に、今後のキャリアを考えたときの一つの選択肢としてデータサイエンティストがあるという感じで、銀行でずっと働いていたけど辞めて、統計の勉強をし直してシリコンバレーで活躍しようとしているという人なんかもいました。アメリカでは昇給率や人気職種の第1位がデータサイエンティストとなっているので、ただ漠然と「データサイエンティストって何ですか?」という話ではなく、具体的にスキルを得て仕事をすれば「今よりものすごく上がるよ」みたいなことが現実となっていて、そこにやっぱり夢があるわけです。
G:
そもそも論として、日本ではあまりそういった話を聞かないですね。
齊:
日本ではすごくぼやっと、「AIをやらなきゃいけない」みたいな話がいろんなニュースサイトや新聞などに書かれているので、企業の社長から「やれ」とは指示されるみたいです。ただ、具体的に何をすれば良いのか分からないので、「とりあえず組織を作ろう」だとか「人を雇おう」などといったこともなかなかない状況ですね。また、実際にデータサイエンティストという職種を募集すると応募が来るらしいのですが、来た人も「なんかこのままSEとかコンピューターでやっていていいんだろうか。データサイエンティストはセクシーらしいから、ちょっと波に乗ってやろうか」という感じです。

そもそもどうやったらデータサイエンティストになれるのかが分からないという状況なので、とりあえず言った者勝ちで「自分はデータサイエンティストです」と言っているような感じです。また、データサイエンティストという職種に応募してみても、たいていは成約しないんです。応募する人は「ディープラーニングなんかをやってみたいので応募しました」とか言うらしいのですが、企業側の期待からすると、そんな勉強しに来た興味本位の人は取らない。仕事があって、金を稼いでくれないと困るので。
G:
入った途端に働けないといけないということですね。
齊:
募集している側も何をやらせればいいかよく分かっていないので、仕事をアサインできないわけです。そこは結構課題だったりしたんですが、産業的には国が「第四次産業革命」と言ってものすごく大事なテーマにしています。ただし、結局人材がいないので、人材を育成するためのキャリアパスがないというのが現状ですね。それが課題になっています。
G:
海外だとGoogleやFacebookで山のようにデータがリアルタイムで精製されるので、そのデータを処理する人材が不足して大変だというのがあるじゃないですか。また、向こうのデータサイエンス関連サイトのKaggleなんかは登録者が60万人ぐらいいるじゃないですか。それに対して日本だと、ああいったプラットフォームで会員数が60万人級というのは見たことも聞いたこともありません。そもそも母数がメチャクチャ少ないですよね。なぜ海外だとデータサイエンティストの規模が大きくて、日本は小さいイメージになるのでしょうか?
齊:
僕が代表を務めるデータサイエンスラボでも、Kaggleと同じようなオンラインデータ分析コンテスト開催サイトの「DeepAnalytics」を運営しています。会員数は6000人を超えていて日本では最大のプラットフォームになっているのですが、Kaggleと比べると全然少ないじゃないですか。日本のサービスなのでしかたがない部分もありますが、アジアにはたくさん人がいるので、サービスエリアを拡張していきたいと考えています。
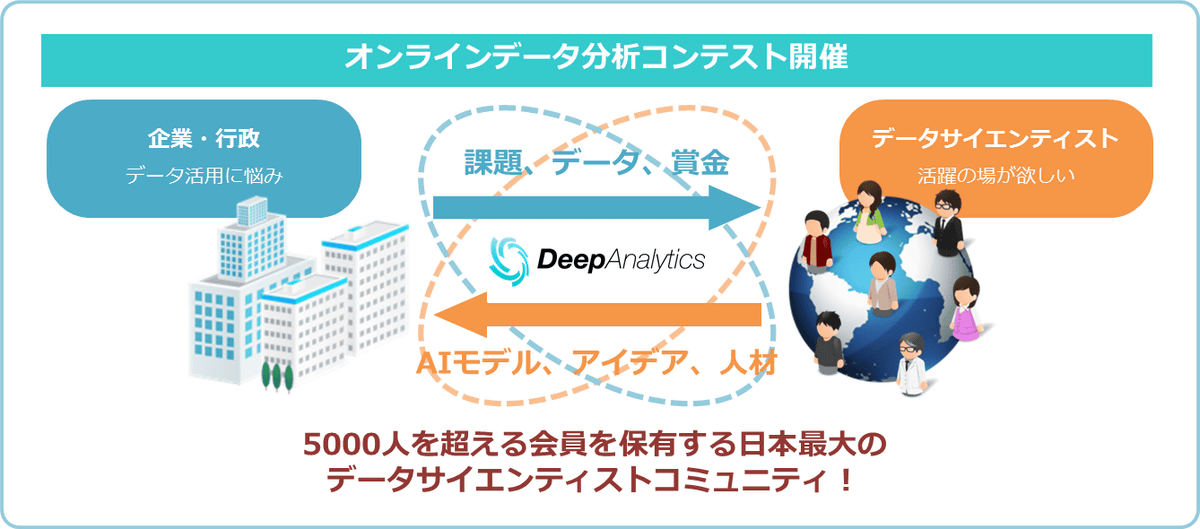
それで、なぜ日本ではデータサイエンティストの規模が小さい、あるいは小さいイメージがあるのかというと、その答えのひとつはやはり企業側のリテラシーになると思います。DeepAnalyticsやKaggleでは、いろいろな企業がコンテストを開いてくれるのですが、大きな企業が大きなテーマ、大きな賞金でコンテストを開くので、やればやるほど人が集まってくる。アメリカでは大企業が結構バンバンコンテストを開催するわけですが、そうすると、普段は一個人では触れられないようなデータに触れられるので、勉強にもなるし「俺が勝ったぞ」みたいなセルフプロモーションにもなるしで、いろいろな動機付けからたくさんの人が集まってくれるんです。そういった流れが早くも到来しているというのがアメリカで。データを公開することにためらいがないというか、ためらうけれど、日本よりも積極的なんです。
G:
日本の方がためらうと。海外の企業は「ためらっても出す」と。この差はどの辺りの差になってくるのでしょうか?上の判断だとは思うのですが。
齊:
そこはいくつかあると思っていて、ひとつはちゃんとリターンがあるんだから、リスクというか、ある程度こういうことをしてもいいだろうと腹落ちしてやっている、腹落ちできる能力があるという点。日本の場合は、データを出したことによる損失というか、リスクみたいなものが何かしらあるのではないかと身構えてしまうという。それも具体的ではなくて、「何かヤバいんじゃないか」みたいな。それでいて「リターンはどれくらいあるんだっけ」ということもボンヤリとしているんです。あとは国民性で、日本やヨーロッパは個人情報ひとつ取ってもオプトイン式で、事前に同意を取っていますよね。なるべくリスクが起きないように考えるのがこの辺りの国民・民族ですね。アメリカの場合はオプトアウト式なので、何かをやって、問題があったら何とかするという風に社会構造ができあがっているので、「先にチャレンジして失敗したら何とかすればいいじゃん」という。この辺りのマインドセットはかなり影響していると思います。
G:
なるほど。日本の企業がデータセットを出した方がメリットが大きいと判断するには何を考えれば良いのでしょうか。
齊:
ひとつは、戦略的に設計図が描けるデータサイエンティストを内部に持つということです。もうひとつは、日本人は事例が好きなので、「過去にこういうことがあった。どこどこの企業がやっている。これだけリターンがある」という事例を増やすこと。そうなれば「じゃあうちもやろう!」となるわけです。データ分析はノウハウもあるので世の中に出ないケースが結構多いので、ビッグデータやAIというのは具体的に何なんだというのがいまだによく分からないじゃないですか。それは公開事例が少ないからです。データ分析の企業はいろいろなことをやっているかもしれないですけど、公開事例がとにかく少ない。
G:
確かにあまり見ないですね。
齊:
そうすると、どの会社も永遠に何ができるか分からないんですよ。公開される事例が増えてくれば「うちでもそういうことをやりたい」という話が出てくるじゃないですか。そういう形で増えていき、それを回すための体制とかも作られていき、段々成熟していく。なので、日本の企業がデータセットを出した方がメリットが大きいと判断するようになるのも時間の問題だとは思います。
G:
実際に今まで見ていて、海外の方では公開されたデータの事例があって、「日本でもどこかの該当する企業が公開出来るんじゃないか?」というのを見たことはありますか。
齊:
それはもうたくさんあります。ただ、究極の問題がひとつあって。これはKaggleを見ていて1番衝撃的だったコンテストなのですが、健康診断や処方箋のデータを使って「次の年入院する日数を当てる」という内容でした。これをアメリカはできるんです。元々の規模がすごくて、「アメリカの不要な医療費は3兆円です。これを削減するには症状を早期発見し、より早い段階で適切な治療を受け、入院しないようにする必要があります。つきましては、皆さんの今までの健康診断情報を用い、機械学習や数学を駆使して入院する日数を当てます」と。それができるのがアメリカで、僕が言いたいのは社会意義はものすごく良いんですが、何しろデータがデータじゃないですか。個人の処方箋や健康診断のデータですよ。それをネットに開放してみんなに解かせると。公開する時に暗号化したり秘匿化したりはしているんですけど、そのためだけに研究者が論文を数本書いたりと。確か最初は全体で3億円を賞金にしたんですけど、そのぐらいかけてもアメリカにとってはものすごく大事な問題だと。結局アメリカでもアルゴリズムが難しすぎて解けずにある程度の精度までしかいかなかったんですけど、それにチャレンジするのがすごいなと。

G:
ものすごく明確ですよね。保険料は下がるわ、一個人で言うと入院するリスクを回避出来る可能性が上がるわ、その問題設計は確かに秀逸ですね。今のはすごく大きな例ですが、逆にすごく小さな例などはありますか。
齊:
例えば個別のプロダクトなどで、ほうじ茶の売上を分析したりですね。適切に売上が読めれば生産計画で初期ロットはどれくらい作ろうかというのが読めるので、大量の在庫を抱えてしまうことも、予想外に売れたものの在庫がなくて機会損失になってしまうということもない。そういう個別の話もいっぱいあるわけです。
◆2:データサイエンティストに向いている人材とは?
G:
そもそも多くの人が「自分にデータサイエンティストという職業が向いているのかどうかが分からない」という状況かと思うのですが、齊藤さんがCAOを務めるオプトの公式ブログで公開されているインタビューの中で「データ分析に必要な能力ってなんでしょうか・・?」というまさにこの疑問に対する答えになるような質問がされています。このインタビューの際、齊藤さんは「まずは、分析スピード。仮説を考えて、データで確認するというプロセスをいかに高速に回せるか。短い時間でたくさんのアイデアを思いつき、データで検証することができれば、発見の確率が上がります。データをスピーディーに分析するためには、コンピューターの基本的な知識と、プログラミングスキル、数学的なスキル、データ解釈スキルが必要」と回答されているんですが……。
齊:
事前のリサーチがすばらしい(笑)

G:
全体的にすごくわかりやすいのですが、一番最後の「データ解釈スキル」というのが分かりにくいというか、これはどういう能力を想定すればいいのでしょうか?
齊:
なるほど。これは職責によっても違ってくるところです。そもそもデータサイエンスと言ってもいろいろな仕事があって、僕みたいに「会社全体でどうやって経済効果を出すか?」というグランドデザインをする人もいれば、「あなたはメディア担当だから、ここのPVを増やすために、KPI目標に頑張って」みたいな仕事を担当する人も出てきます。データサイエンティストはその中でやれることをやるわけですが、データ解釈スキルというのは、例えばメディアであればユーザーの動きから「こうなっているんじゃないか?」という仮説を立てて、データで検証し、仮説が正しいかどうかを証明するという感じです。仮説が証明されたなら、次はこういう施策を打とう、打ってみたらその通りになったかどうかをデータで確認しよう、検証しよう、といった具合に回していく感じです。
G:
要するに、ただの勘ではなくということですね。
齊:
そうです。事実ベースでどんどん回していくわけです。仮説を証明していくという作業がそこに相当します。あるいはもっと上位概念で言うと、そもそもAIやデータサイエンスにはまだない顕在化されていない価値もあるので、本当にアイデアが大事なんです。「こんなことをやったらものすごく新しいんじゃないか」とか「ユーザーがとても喜ぶんじゃないか」というものをクリエイターのように作って、そういうものに機械学習やデータを絡めて分析していくという感じです。アイデアマンであり、ちゃんとそれを証明する科学的スキルがあるか、というイメージです。

サイエンティストは建築に例えることが多いのですが、国はデータサイエンスのスキルを「見習い」「独り立ち」「棟梁」といった具合に大工さんのように例えています。これがなぜかというと、建築の場合は建築物のスケールが違っていても、材料はコンクリートや木材など同じなので、それをどういうテクニックでどのぐらいのグランドデザインで描くかが重要というわけですよね。AIやデータサイエンスにおいても、「最終的に何を作るのか?」という発想能力がものすごく大事なんです。
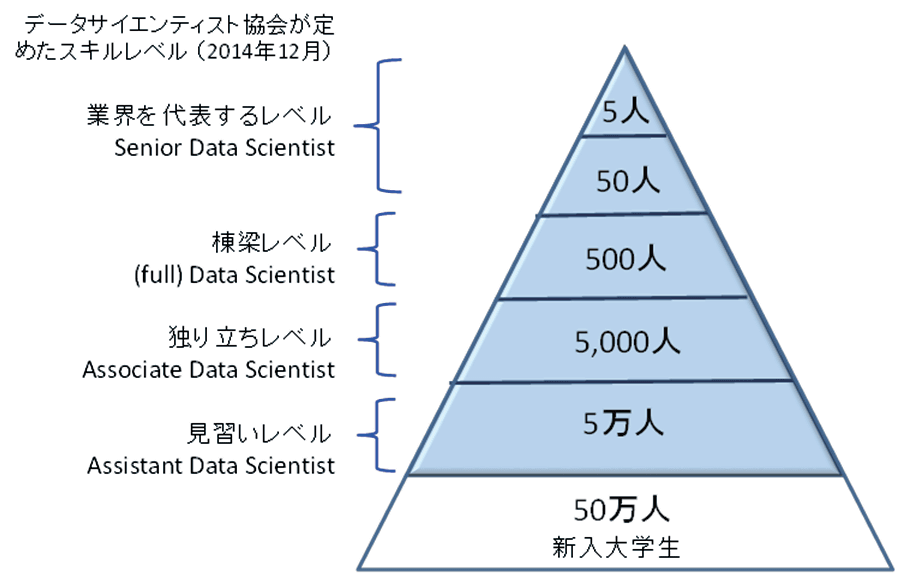
(データサイエンティスト協会 PDFファイル3ページ目より)
例えば「ディープラーニングができる」とか「数学がものすごく得意」という人は、この建築でデータサイエンティストを例える話でいうと、「かんなで削るのがすごくうまい」といったような職人に近い人です。優れた研究者やエンジニアなんかがそういうタイプですね。それとは少し違って、僕のような全体を設計するプロデューサーみたいな人も必要で、そういう立場のデータサイエンティストがそもそもの「何を作るのか」という部分を決めるんです。そういう立場の人が社内にたくさんいれば、「うちの会社でどういうデータを使えばどんな風に結果が出せるんだろう」という部分をより進められるはずです。
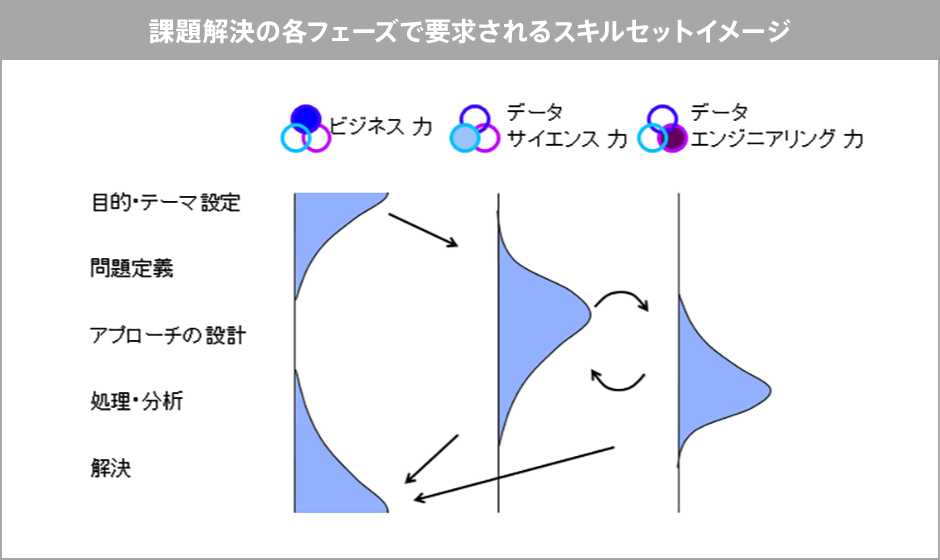
(第4次産業革命 人材育成推進会議 PDFファイル9ページ目より)
そう考えると、「手元にデータが足りないからもっと取りましょう」だとか「その辺に垂れ流しているけど、このデータ使えるじゃん」ということが始まるんですけどね。でもすべてのデータをお金に還元できるわけではなくて、何かを行った時にたまたま出てきた二次的生成物というか、結構ゴミみたいなデータも多くなります。それをうまく使えばお金になるというのは楽観的すぎで、もう少し戦略的にどういうデータを整理していこうだとか集めていこうという部分を決めるために、やっぱり全体を設計するプロデューサー的役割のデータサイエンティストが必要なんですね。
G:
なるほど。お話を聞いていると、その辺りに手を付けようと思うと基本的にいろいろなことを知っておく必要性があると感じます。
齊:
やはり経験が大事なので、アメリカでもデータサイエンティストのトップを務めるような人物は、今は分からないですけど、数年前まではアラフォー世代の脂がのった人がやっていました。20年選手ぐらいじゃないと年収2000万円とか3000万円とかにはいかない状態でしたね。スキルだけあってもダメで、バックグラウンドみたいなものも必要になってきます。いろいろなものが全部噛み合ってきて成熟していくという感じです。
G:
総合的な能力が必要になってくるので、経験も技術も何もかも必要という感じでしょうか。実際に経験などが伴っていない場合はどうなるのでしょうか?
齊:
ストレートに言うと、「結果が出ない」わけです。あるあるとしては、分析するんですが、「それ知ってるよ」と言われてしまうんです。「でも知っていることが改めて分かったからいいじゃないですか」と言い返さないといけないんですが、大体は言われたままシュンとしてしまう。まずその事実を確認できただけでいいでしょ、さらに気付きとかも出てくるかもしれないし、というマインドセットが必要なんです。営業やビジネスサイドからデータサイエンティストになるとか、エンジニアサイドからデータサイエンティストになるとか、いろいろなキャリアパスがあると思うんですが、どうしてもデータサイエンティストになりたての頃はそれぞれ「数理」だったり「エンジニア」だったりの知識が足りなくて、誤解していたり間違った方法を取ってしまったりということが起きます。そういうリスクを言っていると思っていて、都合のいい結果が出たら出たと喜んでいるような感じです。
G:
GIGAZINEでも機械学習や人工知能関連の話題をたくさん記事にしていく中で、「この技術で関連記事を作れるよね」となって、GensimのDoc2Vecの機能を使って関連記事を生成するという工程を、fastTextを使った方がいいのか、それともDoc2Vecでできるのかといろいろ試行錯誤したことがあります。実際に行ってみた時に、「実装するために何をやればいいのか」など最初は理論ベースで言っているだけだったのですが、「関連記事の表示サーバーと機械学習サーバーの最低2台が必要じゃん」などと、実際にやってみると言われているよりも山のように壁があることが分かったので、最終的にアウトプットするのがかなり難しいということはよくわかります。
齊:
今のはすごくいい例で、最終的なアウトプットが出ない一つの理由がそういうことなんです。「それをやってどのくらい良いことがあるのか?」という話で、それに見合う投資なのかがデータやAIでは書きにくくて、やってみないと分からないんです。そこをうまくコントロールできるかどうかが大事で、一部のアメリカ企業はそういった部分が本当に上手。「これぐらい稼げるからこれぐらい投資する」ということがうまくできているわけです。
G:
GIGAZINEの場合は投資がどれぐらい割に合うのかということで、GoogleさんがAdSenseの方で関連記事を表示する関連コンテンツを実装したときに公開してもらった情報から、平均的なオススメの関連コンテンツでPV数が9%、滞在時間が10%向上するというデータが出ていたので、それ以外にやりようがなかったのもありますが、それを信じて計算しましたね。そういうことができるようになったらひとつ壁を超えるという感じなんですかね?
齊:
そうですね。今この瞬間多くの企業が悩んでいるのが予算取りの部分で、「これ、どれだけリターンあるの?」みたいな予算確保のロジックを作るのに苦戦しています。「R&Dだからテキトーに予算使わせてよ!」というのはなかなか通らないので。
G:
データサイエンティストには「ビジネスサイドから目指すデータサイエンティスト」と「機械学習エンジニアとして希少人材に」というキャリアパスがあると伺いました。ひとつ目の「ビジネスサイドから目指すデータサイエンティスト」というのは分からなくもないのですが、もうひとつの「機械学習エンジニアとして希少人材に」というのはどういうイメージでしょうか?
齊:
データサイエンティストという定義を「データを用いてビジネスにインパクトを与える人物」として見た時、ビジネスサイドから見ると、いわゆる僕たちがイメージするようなデータサイエンティストになると思うのですが、エンジニア側から見ると機械学習などを学んで行く先としてのイメージは「機械学習エンジニア」みたいな存在なんです。アメリカでは「データエンジニア」など、データサイエンティストからフォークしていく職業があって、「数学やサイエンティスト的な要素に寄ったスキルセット」であったり、「プログラミングにめちゃくちゃ強い」などで職種が分かれるんですよ。どちらも大枠ではデータサイエンティストと言え、どちらも高給です。その中でもアメリカではエンジニア方面の要請が強くて、FacebookやGoogleなどの膨大なビッグデータを持っている企業は、データ処理にひたすら困っているので、そこをうまくさばいてくれるエンジニアを求めています。こういった人材は、今までのシステムエンジニアやデータベースなどを扱っている人よりもさらにもうひとつ上のスキルが求められるようになっていて、まずは「大量のデータをさばける技術」が必要ですが、そこにプラスで「機械学習などの要素を学んでいる」といった具合で、そっち方面にシフトするキャリアパスもあります。
◆3:データサイエンティストに必要なスキルとは?
G:
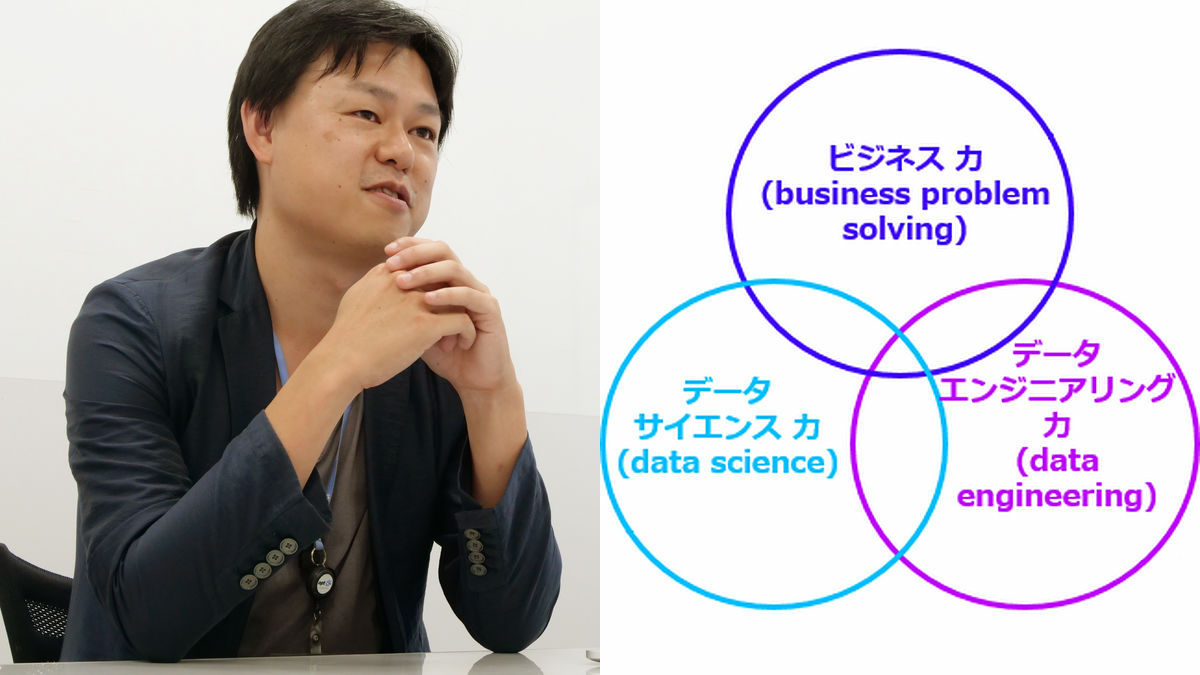
データサイエンティストに必要なスキルなどについて調べると、データサイエンティスト協会が出しているPDFデータに「データサイエンティストに求められるスキルセット」として「ビジネス力」「データサイエンス力」「データエンジニアリング力」の3つが挙げられています。ビジネス力は「課題背景を理解した上で、ビジネス課題を整理し、解決する力」、データサイエンス力は「情報処理、人工知能、統計学などの情報科学系の知恵を理解し、使う力」、データエンジニアリング力は「データサイエンスを意味のある形に使えるようにし、実装、運用できるようにする力」と定義されています。
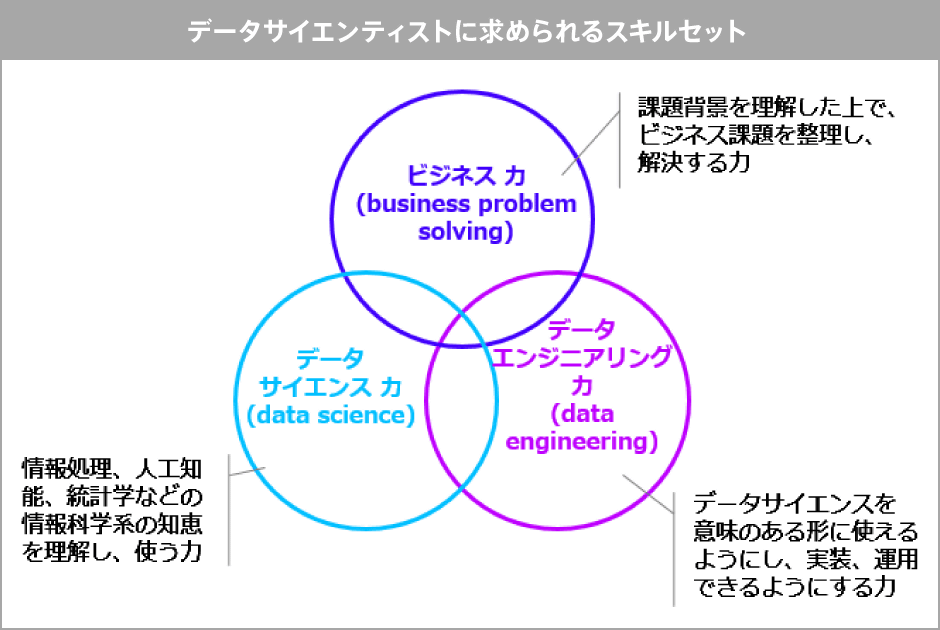
(データサイエンティスト協会 PDFファイル2ページ目より)
さらに、同じPDFを見ていくと、データサイエンティストのスキルレベルについてかなり詳細に定義されています。「データサイエンティスト以前の方」のスキルレベルについては、「ビジネスは勘と経験だけで回すものだと思っている」だとか「課題を解決する際に、そもそも定量化する意識がない」などすごいことが書いてあるのですが、これをデータサイエンティストの見習いレベルにまで上げるには「ビジネスにおける論理とデータの重要性を認識している」「仮説や既知の問題が与えられた中で、必要なデータに当たりをつけて、データを用いて改善することができる」などと書かれていて、一段階レベルを上げるだけで突然ドカンと難易度が上がっているように思えます。

(データサイエンティスト協会 PDFファイル4ページ目より)
これはもう少し易しくというか、もう一段階、階段の一段目のように考えた場合はどういうスキルや心構えが必要なのでしょうか?
齊:
結局、経験と勘のような見えない世界で人間の直感力で意志決定する、というのは間違っていないと思うんです。ただ、それが合理的に証明されているかというとされていなくて、それをやる技がない。統計学などはいわゆる科学の証明法じゃないですか。例えば2つの実験を行い、比較し、仮説が正しいかどうかを証明するのが「科学」で、その手法をビジネスに持ち込みましょうというのが「データサイエンス」。ビジネスで普段直感的に決めていたことが「本当にそうだった!」という風にテクニックとしてわかるようになるのが「数学」や「統計学」。さらに、計算したりする時に、実際にデータを集めてきてプログラミングして数値をはじき出さないといけないじゃないですか、そういったコンピューターを使いこなす技術が「エンジニア力」ということです。なので、数理統計などのテクニックと、それを実現するためのエンジニア力をビジネスをテーマにアプリケーションすれば、それはもうデータサイエンティストになっているんです。そういった方法を無視してただ「俺が言うから」と主張しているのが、「経験と勘だけで言っている」ということに相当するわけです。作法をしっかりそろえて何か小さいテーマでも統計学などを用いて科学的に証明できたなら、それはもう見習いというかデータサイエンティストに入っていると思いますよ。
G:
なるほど。具体的に最初の入り口としては、大学などで習う統計学とプログラミングのいずれかかと思うのですが、どちらから始めた方がいいとかはあるのでしょうか?
齊:
どうですかね。データサイエンティストのスキルセットに3つの丸があるということは、理論的には3つの方向があるはずだと思うんです。ざっくり言うと、「元々ビジネス力を持っている人がデータサイエンス力とエンジニア力を広げるパターン」「元々数学が得意な人がビジネス力とプログラミング能力を上げるパターン」「元々プログラマーだった人がビジネス力とデータサイエンス力を上げるパターンという」があると思います。
G:
自分が3つのどのスキルが高いかによってスタートラインが異なると。
齊:
そうです。3つのどれかが強いはずなのですが、もしかしたら2つが得意とか、いろんなパターンの人がいると思います。そんな中で今ある課題のひとつが、自分がどうなっているのかよく分からないということです。どこが得意なのかよく分からないのでどちらへ進めばいいのか、何を勉強したらいいのか、どのスキルを伸ばせるのかがクリアじゃないと。それが結構な問題で、プログラミングの教育本などは売っていますが、自分の立ち位置がわからないので何をどういう風に体系立ってやっていけばいいのかがわからない。
G:
RPGのスキルツリーではないですけど、自分の場合はそもそも何ができていて、そこからあとどれを育てていけばいいのかわからないと。
齊:
そうですそうです。全体がよく分からないので、自分のいる場所もよく分からない。やった結果どうなっていくのかも読めないという。
G:
合っているのかどうか五里霧中では学習する気も起きないですもんね。
齊:
今はテクニックサイドがディープラーニングとかで熱いので、言ってしまえばデータサイエンティストが使うようなプログラミングツールや言語がすごく便利になって、簡単にすぐ試せるようになっています。そんな具合にチャレンジするためのハードルは下がっているのですが、「なぜそれが動いているのか」だとか「どういう仕組みなのか」という理解の部分はほとんどの人がおざなりにしたままなので、「間違った使い方をしている」という危惧につながっています。
G:
なるほど。元が分かっていなかったらなぜそうなっているのかの解釈を間違えてしまうという感じですね。
齊:
そうです。営業サイドから言うと、「このぐらいの簡単なツールさえ使えればもう十分だ」という人もいるので、それは合っているところもあるけど、間違っているところもあって。それで十分かどうかは分からない話なんです。そういう単純な問題ではないんですよね。
G:
ビジネス力・データサイエンス力・エンジニア力を「ビジネス」「数理」「プログラミング」と捉えるとするなら、それぞれのスタートラインはどうなんですかね。Udemyで開講されるデータサイエンティスト入門講座からすると、どのタイプの人を想定しているんでしょうか?
齊:
結論から言うと、僕らが作ったデータサイエンティスト入門講座は、ひとつひとつの要素を深く教えることはしないで、全体を浅くなめましょうという講座なんです。そもそもデータ分析の始めから終わりまでを一気通貫で経験してみましょうという講座は少ないので、そこにフォーカスを当てたものになっています。「そもそもなぜこんな分析をしなくちゃいけないの?」という背景があるわけじゃないですか。例えばビジネス面で言えば、「こういうものを解けばすぐ売り上げに跳ね返っていくんですよ」「そのためにはこういう数学の知識が必要ですよ」という簡単なものを、いくつか見せるんです。実は必要な知識や技術はもっと何種類も何十種類もあるわけですけど、それは自分で勉強してくださいと。いくらでも、本や教材はあるので。
G:
なるほど。まずは一通り全体を経験してみて、「何を言っているのか」を理解してもらうイメージですね。
齊:
だからいわゆる実践教育です。実践の意味は、ひとつストーリーがあるということで、ストーリーがないまま要素で教えると形式的な基礎教育みたいな感じになってしまう。数学でいうと、まず線形代数を学んで……みたいに1個ずつやるんですけど、「最終的に何に使えるの?」というのが見えないまま勉強すると苦しいじゃないですか。ビジネスにおいては「何の役に立つの?」が先に来るので、役立つような話の中で「どの局面で何の記述を使うんだろう」というのを見せます。そのテーマがたとえば小売りの売上予測であったり、製造業の機械の話であったり、テーマは変わるとしても、使っている考え方自体は似ているんですよ。それでも具体的なテーマを与えることによって、より身近に感じられるようになって興味関心が違ってくると思うんです。
齊:
なので、「何から入ればいいんですか?」という問いに対する答えは、「プログラミングをやれ」とか「数理から入れ」という話ではなく、「ストーリーから入る」ということで、「分析の実際の業務フローを感じるところから入りましょう」ということになります。
というわけで、データサイエンティストを目指す人が最初にやっておくべき、という齊藤氏監修の入門講座は以下の通りです。
【ゼロから始めるデータ分析】 ビジネスケースで学ぶPythonデータサイエンス入門 | Udemy(GIGAZINE読者 特別価格 19,800円→1,600円)
講座の内容としては、銀行の顧客属性データを使い、実際に機械学習を用いた予測モデルを作成するというもの。
内容はストーリー仕立てなので初めてデータ分析に挑戦する、という人でもわかりやすい内容になっています。

また、Pythonを使ったプログラミングでは初心者でもわかるように、実際の記述をムービー中で解説してくれます。さらに、わからない点については質問掲示板から講師に直接質問することも可能です。

◆4:データサイエンスの活用事例
G:
データサイエンティストによるデータ分析の実績例として「豆腐の需要予測」というのを見かけたのですが。
齊:
いわゆる「食品ロス」廃棄ロスの問題に取り組んだ事例ですね。豆腐は日本の代表的な日配品ですが、日持ちしないのでほとんどのメーカーさんが天気などから、それこそ勘と経験で工場長が「明日100万丁作るぞ」みたいなことを決めているわけですよ。工場なのでかなりたくさん作るじゃないですか。それでもし売れなかったらその分は廃棄するしかないわけですよ。もったいないですよね。これが少し問題になっていて、国も食品ロスを減らそうといろんなプロジェクトを行っていて。始めた頃は「ビッグデータなんか使ってもうまくいくわけない。俺らが何年やってると思ってるんだ」などと言われました。実際、彼らの経験値でかなりうまくやっているわけなので。けれども気象データなどをもとに予測を立ててみると、最大15%も食品ロスを改善することができるとシミュレーションから明らかになって。実際に工場で稼働しても削減することに成功したので、それを目の当たりにしてようやく現場の人たちも「結構役に立つな」と。

G:
あと、これもすごいですね。「健康菓子の売上予測、新商品開発」というのがありますが、新商品開発でどういう風にデータを使うんでしょうか?
齊:
それは僕も本当にやりたい話で、データ系のプロジェクトの多くはコスト削減、無駄をなくそうという使われ方が多いんです。それだと効率化にはなるんですが、新しい市場を開拓したり、新しい価値を生み出すことにはつながらないんです。僕はクリエイティブや新しいものを生み出すことにビッグデータを使うのが好きなんです。この「健康菓子の売上予測、新商品開発」では、僕がローソンさんに「売上の予測をするだけではつまらないから、新しいお菓子を作っちゃいませんか?」と提案したんです。データからお菓子を作るので「データパティシエ」みたいな。ここで使ったのはローソンさんの全国1万5千店舗から集められたPOSデータで、ナチュラルローソンさんの健康菓子の売り上げを見ると、場所によって売れるものが違うんです。OLだったり学生だったり、買っている人も違うんですよ。そこで、傾向を分析したデータから、「こういうお菓子をここで売ったら売れるはずだ」という仮説を出してください、とコンテストを行ったわけです。普段はマーケティングの人たちが勘や経験から「今健康食品が流行しているから、こういうのを作ろう」みたいな感じで提案して、後付けでリサーチをかけたりしながらデータをポジティブに押していくわけですが、そうではなくて、逆にデータを見てそこから発想して新しい商品を作るわけです。実際にコンテストを行ったところ、学生や社会人など、全然お菓子とは関係のない理工系の企業の人などが、データを分析して「食物繊維豊富な素材を使ったチョコレート菓子を、健康志向のOLが多いこの場所で販売すると売れるんじゃないか」みたいな提案を、グラフなどを使いながら提案してくれるわけですよ。
このようなデータを用いた新しいお菓子の開発を「データパティシエ」と呼んでおり、齊藤氏が運営するDeepAnalyticsでは経済産業省などをスポンサーにコンテストを実施しました。
データパティシエが「ナチュラルローソン菓子」の売上予測・新商品開発に挑む - DeepAnalytics

G:
なるほど。
齊:
ただ、その提案に答えはないので、そこはやっぱりプロの目としてローソンさんの商品部の部長さんなどに全部見てもらって判断してもらいました。中には即お菓子として売れるレベルのものもあると言われました。プロ目線で基準をクリアしており、かつ、データの裏付けもしっかりしているわけなので、「あともうちょっとこれを加えたらさらに良くなる」みたいな議論になるわけですよ。僕の中では「ビッグデータから作ったお菓子がバカ売れ!」でシナリオが完結しています。みんなのアイデアで、もの作りや新しい価値にデータを使うという。
G:
ただの改善だけではなくて、新しくものを作ることにも使えるということですね。これは確かにすごいです。今言われて初めて「確かに言われてみればできるかもしれない」と思ったんですが、データを集めていったら新しいものも作れるはずだという発想は、どこから思いついたのでしょうか?
齊:
先ほどの話のように、発想があってデータで裏付けるという今までのものを逆転しただけですね。データの分析方法には2種類あって、元々強力な仮説があってそれをデータで裏付けるスタイルと、データだけを見てヒントを見つけて探していくというデータマイニングというスタイルの2つがあります。今言ったのは後者の「データマイニング」的なスタイルです。別に今に始まった考え方ではなくて、元々そういう考え方があるのでそれを応用しただけです。僕はそっちのスタイルが好きなんです。人口が減って労働生産性や働き方を変えようと言っている中で、有限のリソースの中で新しいものを作っていかなければいけないわけで、そういう時にデータは非常に大事で役に立つわけです。データを効率的に組み合わせたり掛け合わせたりして、そこから見つけることでうまい具合に新しい価値が出てくると考えています。こういったことを仕掛けることこそがデータサイエンティストの仕事だと思います。
G:
少し話がズレるのですが、齊藤さんのインタビューを読んでいると、齊藤さんが不整脈があった時期に病院で「手術が必要」と診断されたエピソードが語られているのですが、手術が必要と診断された後にご自身で心電図を分析して別の病院に行き、「僕は手術が必要とは思わないんですけど」と話をしたら「そうだね。君が正しい」と言われたと。GIGAZINEでも「心臓の不整脈をApple Watchと機械学習で特定することに成功」という記事を掲載しており、データサイエンスというものは単純に仕事以外でも命を助けることなどにもつながるのかなという印象を受けました。プライベートな話だとは思うのですが、実際にこのとき不整脈があったりすると心電図を見て、どうして「手術は不要なのでは?」と分かったのでしょうか。
齊:
まずは調べるじゃないですか。24時間ずっとデータをとるのですごいデータ量ですよね。その検査結果を患者に報告する時に、医師がほぼ見ていないんですよ。
G:
ほぼ見ていない!?
齊:
ほぼ見ないで医師が診断しているんです。その段階で、分析するまでもなくその決定は信用できないじゃないですか。それだけのデータを取っているのに、手術するしないの決定を即決するのか、という。分析するまでもなく。
G:
なるほど……。
齊:
手術する必要があるかないかというのは難しい問題なので、僕はデータを奪ってセカンドオピニオンを取りに行きました。インタビューに書いてある通り、僕はそんなにしっかり分析をしたわけではないんですよ。当時まだ20代でかなり若くて、いろいろストレスがある中で不整脈が出てしまったんですけど、慢性的な疾患でもなかったのでもしかするとまた収まるかもしれない。僕がセカンドオピニオンを取りに行った際に医師にまず聞いたのは、「どっちのリスクが高いか」です。「手術をして失敗するリスクが高いか、このまま放置したときのリスクが高いのか、どう思いますか?」と。すると、「確かに割とこなれた手術ではあるけど、ミスはないこともないので、その若さならしばらく薬などで様子を見ておけば、回復する可能性もある」と言われたんです。リスクについては医療臨床的に統計的な数字が出ていたので、そういったデータを見ながら議論しました。それを聞いただけで「こっちの方がいい」と僕は直感的に思いました。だから、本気でシグナルを分析したわけではないんですけれども。
G:
それでも、「いくらなんでも医者の言うことはメチャクチャだろう」というような直感のようなものを働かせることはできる、という感じですね。言われてみると確かにそんな感じがします。
齊:
この話で言いたいのは、データサイエンティストはニュートラルなポジションであって、決めつけで「こうするべきだ」とか「こうなる」とかがない、ということです。直感的にデータを見ているので、「こういう傾向があるんじゃないか」とかそういうことはいろいろと考えるわけですけど、割とフラットに考えます。
◆5:なぜデータサイエンティストは高給なのか?
G:
海外の事例と日本の事例をいろいろ見ている齊藤さんの目から見て、今後のデータサイエンティストの未来はどんな風に変わっていくと予想していますか?
齊:
僕が思っているのは、基本的に非常に重要な仕事であるのは間違いないと。ただし、それが今のデータサイエンティストと言われる人物像と同じかどうかは分からないですが。社会インフラは自動運転車など、あらゆるものがAIと呼ばれるコンポーネントにつながっていて、そこに従事する仕事が増えるのは間違いないですよね。そこをエキスパートとする仕事は花形だと思っているので、今はAIを作る人が注目されているという。ただ、僕はその次にそういったAIから生まれたものを「社会でどのように運用するのか?」という部分が大事だと思っていて、できたものをどうやって持続させるかが重要だと感じているわけです。なので、AIをちゃんとコントロールする仕事だとか、セキュリティリスクを減らすための仕事だとか、そういった専門の技術者がどんどん増えてくるはずだし、幅が広がっていくと思います。なので、ハッキリ言うと、このデータサイエンスという領域はかなり熱く、今後も食いっぱぐれない分野であることは間違いないですね。
G:
食いっぱぐれのない分野とのことですが、どうして海外のデータサイエンティストはあんなに給料が高いんでしょうか?
齊:
それは先ほどの話題と同じように、メインのビジネスに対してどれくらいコストをかけても大丈夫か、という計算がうまくできているからです。Netflixの事例が有名で、トップページのオススメ機能のコンバージョンレートが75%もある。そのレコメンドシステムを誰が作っているのかというと、データサイエンティストが作っているんです。あらゆるコンテンツにタグを付けて整理し、どのユーザーに何を見せれば効果的に視聴してもらえるのかという部分をチューニングしまくっているわけですよ。そんなレコメンデーション機能の開発に、Netflixは約185億円もかけていて、それだけの予算があるので何百人もの専門家を雇うことができるんです。そして75%のコンバージョンレートをさらに上げたり、UXを向上させたりすれば、もっと売上を増加させることもできますよね。そこにフォーカスする設計ができているので、Netflixのデータサイエンティストはシリコンバレーでもトップクラスの給料をもらっていて、それだけの価値があるということになります。

一方で、ぶっ飛んだ領域でのR&Dに没頭するデータサイエンティストもいて、そういう分野の例で言うとGoogleのAlphaGoを開発だとかが当てはまります。他にも、AIを使って自動運転車を開発して既存の社会インフラを一掃してやろう、みたいなプロジェクトもたくさんありますよね。こういった分野ではとにかく惜しみなく給料を払って、「優秀な人たちに社会を変えてもらおう」という感じになっています。スーパーコンピューターの京の18倍のスペックを無料で研究者に開放したり、どんどんフリーでみんなにばらまきまくることで、天才たちを自分たちの土俵へ引き入れるというか。物理空間からインターネット空間に全部の世界を持って行ってしまおうみたいなことをやっているので、そういう分野に人生をささげて良しと認められた人は、とにかくものすごいお金をもらっていますね。
G:
要するに、収益を生み出す絵図が描けているからという話になってくるんですね。それだけの年収をバーンと払ってもなおリターンがあるというのが分かっているからと。
齊:
分かりきっているんです。あとは、産業を変えてしまうというところに投資しているわけです。
G:
そうすることがこれから先の未来のために、会社自身のためになるという話ですよね。つまり、データサイエンティストがいると、一挙両得でできるという話ですね。
齊:
そういうことです。なので争奪戦が起きるわけですね。
G:
なぜ日本では争奪戦にならない……いや、日本でも実は争奪戦になっているんですかね?
齊:
なってる……まぁ、アメリカほどではないと思いますけど。
G:
それでいくと、逆に海外ほど争奪戦になっているのが目に見えないということは、今からやってもまだ十分間に合うという感じですかね。
齊:
間に合うし、外国の方が日本に来る可能性も十分高いと言われています。トランプ政権の話もあるし、単純にサンフランシスコは物価が高いじゃないですか。全部倍ぐらいなので、冷静に給与水準で考えるとあまり変わらないですね。むしろ東京で同じ額をもらえるなら、もっと良い。アメリカではデータサイエンティストの年収が平均2000万円~3000万円ぐらいなので、日本でもあり得なくはないです。やればみんな来るんじゃないかとも思います。日本の企業はそれだけの資金を持っていますし。ただ、実際問題そこにもいろいろなやつがいるので、「生めてないじゃん」みたいになっちゃうかもしれなくて難しいところです。ただし、流れ的にはそういう方向に行くはずです。
◆6:データサイエンティストを目指す上で持っておくべき心構え
G:
最後の質問になるかと思うのですが、先ほどの話に出ていた「文系ビジネスマン」という人がいるじゃないですか。文系ビジネスマンみたいな人が、ビジネスについてはある程度分かっているけど、それでももう少し自分の部署なり製品なり、もしくは会社なりの利益を上げたい、その元データになるものは会社にたくさんあるっぽい。それでも誰もそれに手を付けていない、このデータを勘ではなくて有効活用したい……という情熱を持った人の場合、何を心構えとして最初に持っておくべきでしょうか。
齊:
個人的にまずどうするかというと、自分が「やるぞ」と。自分はデータサイエンティストであると信じて、周りにも「俺はサイエンティストだから」と言ってひよらないことです。「ちょっとやってみました、素人なんですけど……」みたいな感じで下手下手にならないで、「俺はやるから、覚悟決めたから」と言う感じで取り組むことが大事で、組織内で反発が出ることもあるでしょうし、分かってくれないこともあるかもしれませんが、頑張れば企業の中で第一人者になることは可能だと思います。だってそんなことをやる人はいないじゃないですか。実際に数値で良い結果でも出した日には、もう完璧にデータサイエンティストですよね。そしたら、「それ○○君に頼めば良いよね」という風になるに違いないんです。結果を見せたら人間は変わるので。やる側は最初に恐怖があって、「俺違うから、できないから、無理」みたいな感じになってしまいがちなので、言っちゃえばいいんじゃないかと思います。
G:
勇気を出して「自分はデータサイエンティストだ」と。
齊:
僕も最初の方は「データサイエンティスト」とか「チーフアナリティクスオフィサー」とか勝手に名乗っていただけですから。誰かに「お前それでいいよ」みたいに言われたことはないです。それでも背景やキャリアなど、やっていることで許されているだけなので。それっぽいキャリアですよね。サイエンス・データをやっていて、みたいな。だけどやっぱり有言実行というか、やることじゃないですかね。そこのメンタリティーがもしかしたら最初かもしれないです。技術だとかやり方は我流であれなんであれ、身につければいいわけですから。

G:
なるほど。むしろ文系ビジネスマンだからこそ、その辺りは正々堂々宣言しろ、というぐらいの勢いなんですね。
齊:
スタンスですね。ちょっとやるぐらいだったらそれでいいし、本気でそっちに行くとか、自分の武器にして伸ばしていくんだという意志があるなら、なんちゃってではなくてそれなりに勉強しないといけないし、実践で格闘しないとたぶん成長しないですから。理論と教材だけでは少し足りないと思います。
G:
実際のところ、データサイエンティストに向いている人というか、性格的なものはあるんでしょうか?
齊:
やっぱり必要なスキルセットをそれなりに取らないといけないので、そこで生理的に抵抗感があると無理じゃないですか。「プログラミング絶対無理!」とか、吐いちゃうとか。
G:
なるほど(笑)
齊:
それはさすがにキツいじゃないですか。無理にやっても仕方がないので、ある程度プログラミングを抽象化する数学的思考に抵抗感がないというのは必要で、そこを自分で伸ばしていけるのであれば向いていますよね。あと、そういう意味でよく言われるのは、中立的思考で「疑う力」を持つこと。分析すると割とすぐに良い結果が出たりもするのですが、即座に「やったぜ」と喜ぶのではなく、「まぁ待て」と落ち着いてみると、大抵間違っているんです。データのミスをしていたり、ちょっと変なことになっていたり。それを今回の講座でもやっているんですけれど、作法があって、まず始める時に愚直に1個ずつデータを確認したり、基礎的なことをやるんです。それをスキップして一気にやる、みたいなものが多いんですよ。そうすると、結果が出たんだけど「あれ?」となってします。ここでミスしていたみたいなことがある。なので「疑う力」が必要になります。まずは冷静になり、「本当にこの結果で正しいのか?」をいろいろな角度から確認する、というスタンスは昔から言われています。

一方で、背反するスキルとして持っていないといけないのが、「想像力」あるいは「アイデア」です。冷静に処理して分析はするんですが、それだけやっていてはただの処理技術者になってしまうので、クリエイティブなセンスも必要になります。こういった結果が出るんじゃないか、という部分を想像する力ですね。あと、巻き込んだ人たちが納得する筋や、社会が求めている課題を自分で設定する力が必要で、そういう直感的な能力と、冷静で定量的な能力を同時に持たないといけないです。もしくは、それらが持てるようなセンスです。なので、芸術家タイプと学者タイプをハイブリッドしたような人が理想です。
G:
最終的にレオナルド・ダ・ビンチみたいになってきますね。実際にデータサイエンティストとしての仕事に取り組んでいく中で、それらの能力は磨かれていくものですか?
齊:
分析結果を話すと初めは「そんなこと知ってるよ」などと言われることもあります。その後に「もっと良い結果はどうやって考えられるかな」「期待を裏切るような結果はどうしたら出せるのかな」と考えることが重要で、あるいは「こういう最新技術ができたから、これをアプリケーションしたら何か見つかるんじゃないか」とトライしたりする中で、データサイエンティストとしての能力を磨いていくわけです。そうすると引き出しが増えていき、相談を受けても「うん、こんな分析をこうしたらこんなオチで、いけるかな」というのが読めるようになるわけです。そういう設計ができないベンダーや技術者は多くて、炎上するんですよね。依頼されて最初から無理ゲーなのに受けてしまうわけです。
G:
その辺りの予測がつかないから。
齊:
予測がつかない、経験値が足りないからですね。「ディープラーニングがあればできるでしょ?」みたいなことを言われるんですが、「データが全然なくて、見るまでもなく絶対無理だから」という話も、データサイエンティストとしての能力が高ければ当たりがつけられるようになるはずです。
G:
そのデータサイエンティストの能力というのも基本から順番に積み上げていったからですよね。
齊:
そうです。そうすると、新しいお菓子を作ってみて最終的には売れるんだ、みたいなものの道筋が立てられるようになるんです。そして、それが社会価値になって、みんなが面白いね、そうなったら良いねと思うじゃないですか。その設計ができるかというところにかかってきます。
G:
なるほど。今のはかなり示唆に富む話ですね、非常に面白いです。ありがとうございました。
◆7:データサイエンティストを目指す人向けの入門講座
そんなわけで、データサイエンティストとは一体どんな仕事で、どういう人が目指し、今後の社会でどういった役割を担っていくことになるのかを質問攻めにより解き明かしてきたわけですが、結局のところは「何から始めればいいのかわからない」という人も多いはず。そんな時に役立つのがUdemyに新しく登場したデータサイエンティスト入門講座で、データサイエンティストの仕事がどのようなものなのかを一通り経験して身に着けられるものになっておりオススメです。
【ゼロから始めるデータ分析】 ビジネスケースで学ぶPythonデータサイエンス入門 | Udemy(GIGAZINE読者 特別価格 19,800円→1,600円)
講座ではプログラミング初心者でもついて行けるように、一問一答形式の教材でプログラミングを少しずつ身につけながら、データサイエンスの実際の流れを体験できるようになっています。リアルなデータを題材として用いることでより実践的な能力が身につくようになっており、わからない点については質問掲示板から講師に直接質問することも可能なので安心です。
また、データサイエンティスト向けの入門講座を提供するUdemyは、齊藤氏の運営するDeepAnalyticsと連携しており、リアルなデータを用いて分析手法を学習できるようになっています。
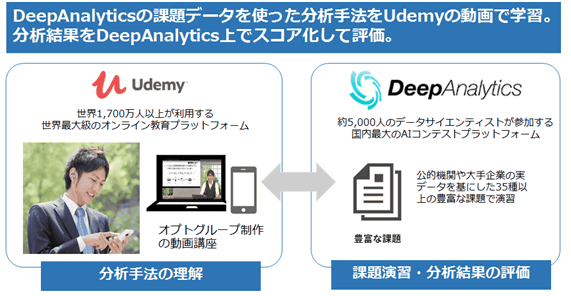
さらに、入門講座でデータサイエンティストとしての基礎を学んだあとは、Udemyで提供されているその他のデータサイエンティスト向け講座を通してビジネス力やサイエンス力、エンジニアリング力など各方面の能力を強化していくことができます。以下のほとんどの講座が特別価格として1600円で提供されているので、この機会にデータサイエンスに必要な能力を習得してみるのも大いにアリです。
【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 初級編 - | Udemy(特別価格 15000円→1600円)
【世界で5万人が受講】実践 Python データサイエンス | Udemy(特別価格 12600円→1600円)
みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習 | Udemy(特別価格 15000円→1600円)
Pythonで機械学習:scikit-learnで学ぶ識別入門 | Udemy(特別価格 15000円→1600円)
【R言語でらくらく解析】ビジネスマンのためのデータ分析入門 | Udemy(特別価格 10200円→1600円)
【ゼロからおさらい】統計学の基礎 | Udemy(特別価格 10200円→1600円)
Power BI を使用したデータ分析入門講座 | Udemy(特別価格 6000円→1600円)
Tableau(タブロー)で実践!ビジネスユーザのためのデータ集計・視覚化・分析 基礎編 | Udemy
【4日で体験しよう!】 TensorFlow x Python 3 で学ぶディープラーニング入門 | Udemy(特別価格 14400円→1600円)
※本企画は株式会社ベネッセコーポレーションの提供で、GIGAZINEがお送りします。
▼ GIGAZINE
運営会社:株式会社OSA
住所 :大阪府茨木市別院町2-7
電話番号:072-621-1541
▼Udemy メディア
運営会社 :株式会社ベネッセコーポレーション
住所 :岡山市北区南方3-7-17
サイトURL:https://udemy.benesse.co.jp/
・関連コンテンツ



in 取材, インタビュー, 広告, Posted by logu_ii
You can read the machine translated English article How to become a cutting edge, high-incom….