




無料で使えるApple IntelligenceのFoundation Modelsベースのローカル翻訳アプリ「Pre-Babel Lens」

Apple Intelligenceのデバイス内LLMであるFoundation Modelsを使う翻訳アプリケーション「Pre-Babel Lens(プレバベル)」が公開されました。Apple Intelligenceを有効にしたMacであれば無料で利用することが可能です。
ttrace/pre-babel-lens
https://github.com/ttrace/pre-babel-lens
Apple IntelligenceのFoundation Modelsを使うローカル翻訳アプリ #DeepL - Qiita
https://qiita.com/ttrace/items/38f363fa04e924dd97cb
リリースページから最新バージョンのDMGファイルをダウンロードして、インストールします。記事作成時点での最新バージョンは0.5.0でした。
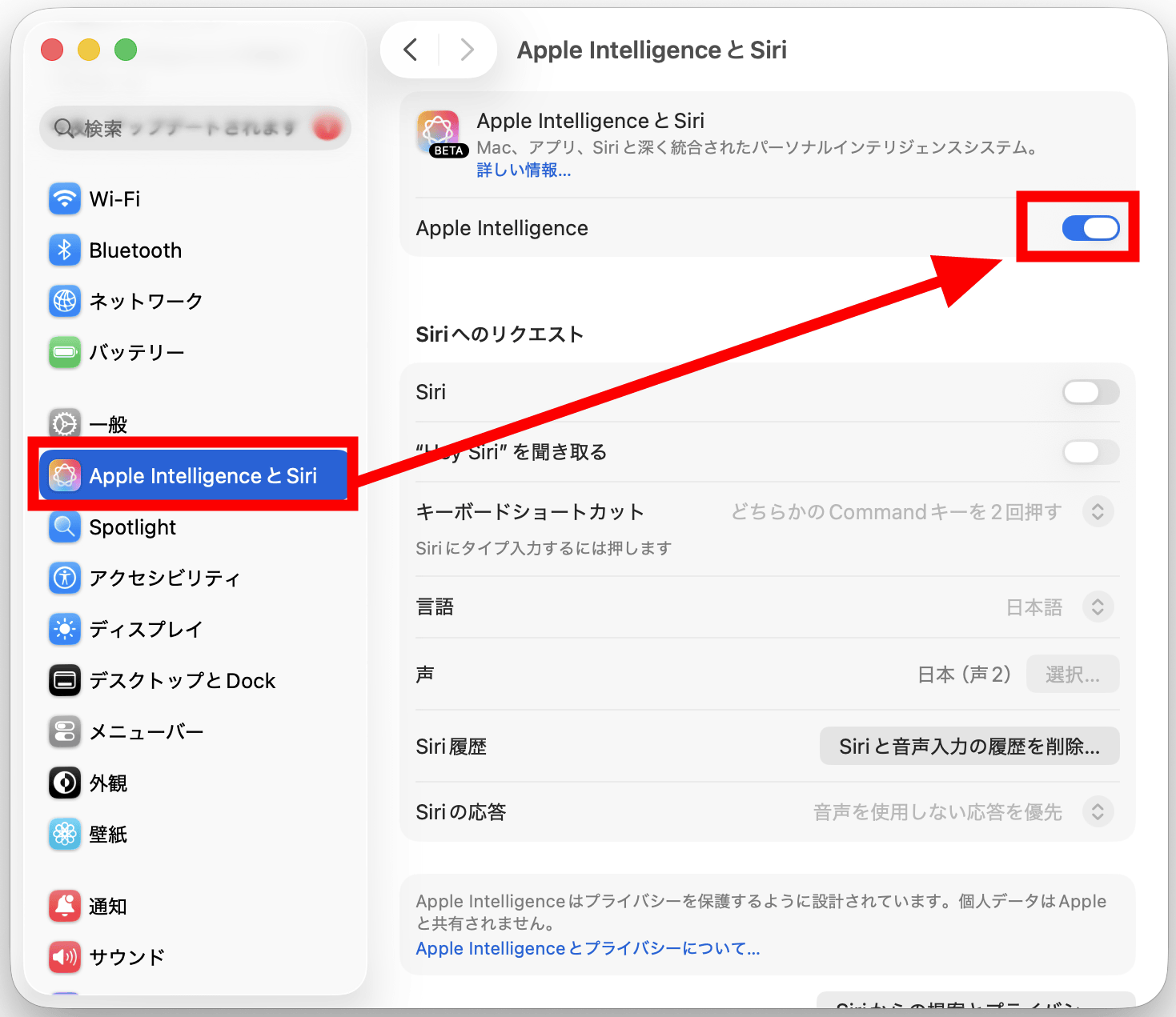
同時に、macOSの「設定」で「Apple IntelligenceとSiri」から、「Apple Intelligence」が有効になっていることを確認します。
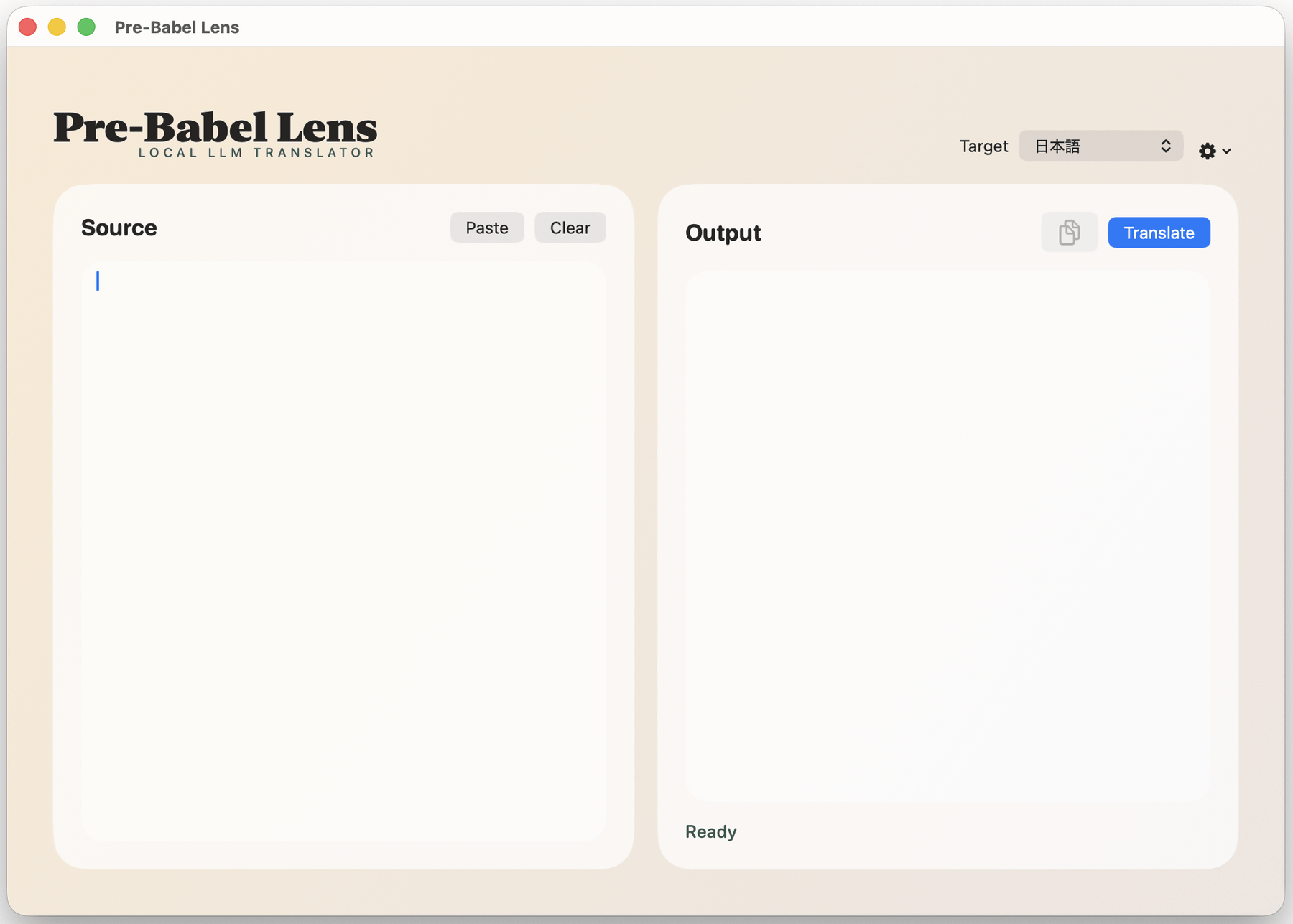
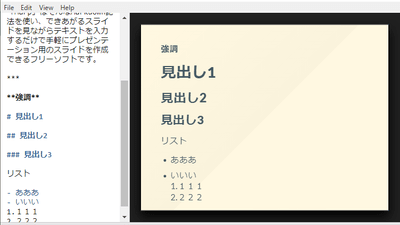
Pre-Babel Lensを起動するとこんな感じ。左側は翻訳したい文章の入力欄で、右側が翻訳された文章の出力欄。開発者の藤井太洋氏は「DeepL風の2ペインで翻訳を行う」と述べており、UIもDeepL翻訳を意識している模様。
翻訳したい文章を左の入力欄にペーストして、「Target」が「日本語」になっていることを確認し、「Translate」をクリック。なお、Pre-Babel Lensが起動している間は、翻訳したい文章を選択してCommand+Cを2回入力すると、自動でその文章がPre-Babel Lensの入力欄にペーストされるとのこと。
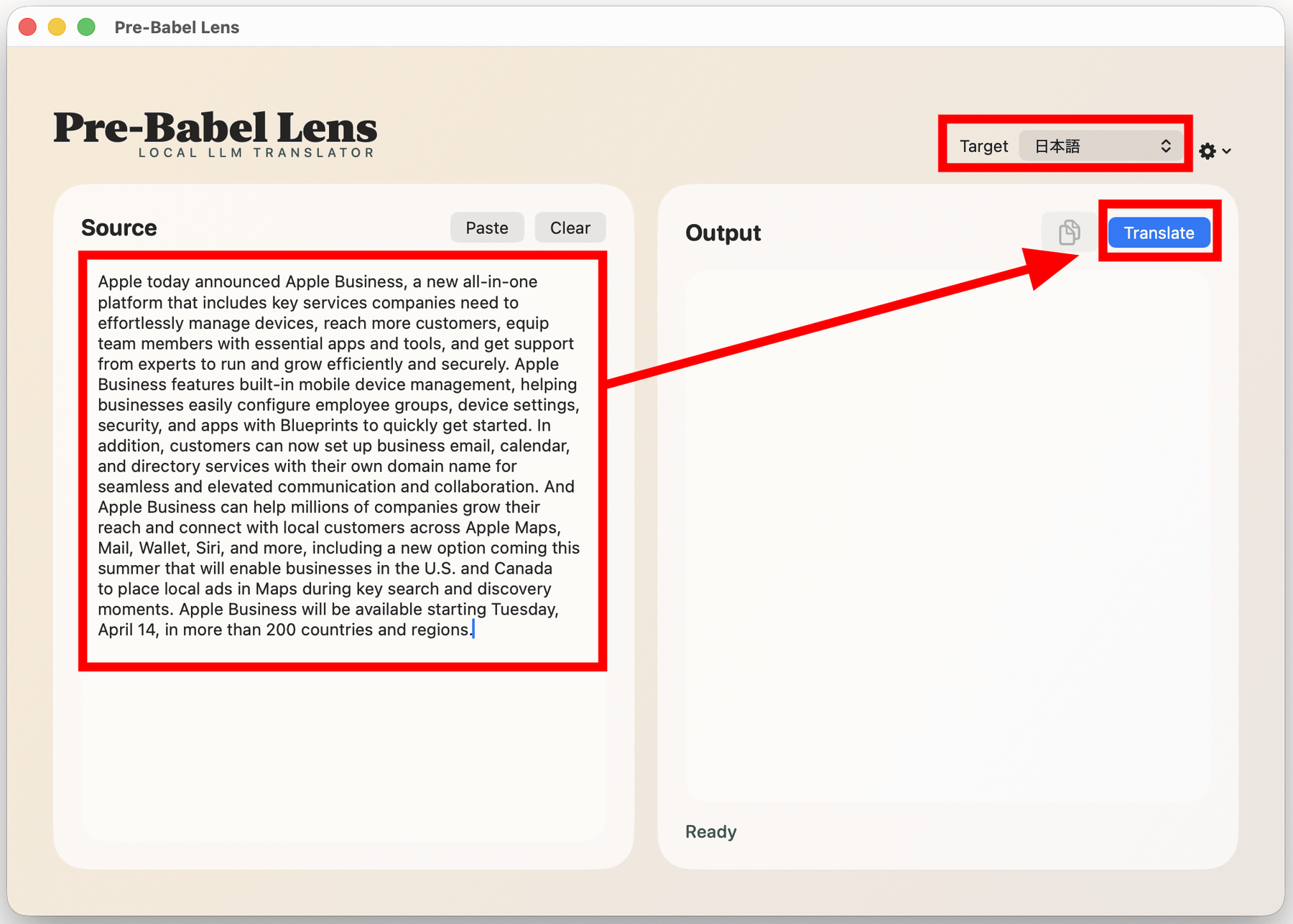
実際にM4搭載MacBook AirにPre-Babel Lensをインストールして、Appleのニュースリリースの一部を翻訳してみたところが以下。翻訳の処理速度はかなり速く、十分実用に耐えるスピードだと感じました。
Apple IntelligenceのFoundation Modelsを使う無料のローカル翻訳アプリ「Pre-Babel Lens」をM4搭載MacBook Airで使ってみた - YouTube
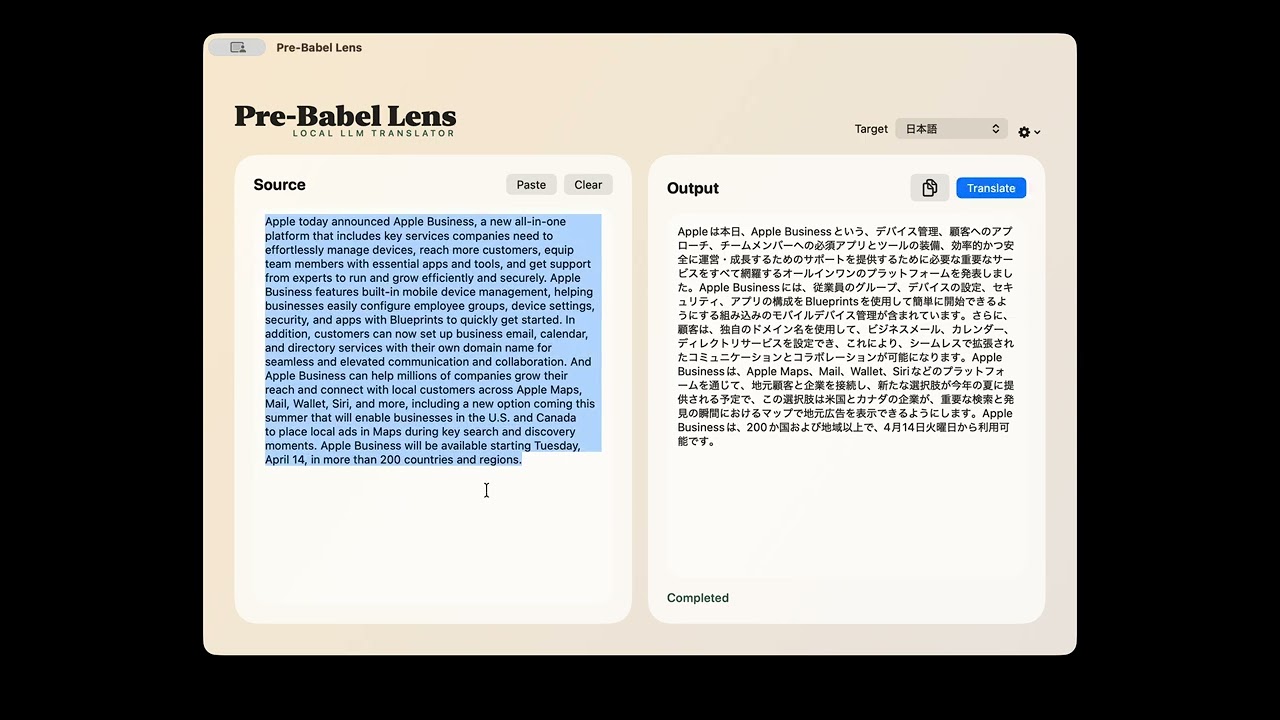
左側に出力された文章はこんな感じ。元がニュースリリースの堅めの文章だということもありますが、翻訳後の文章に破綻はほとんどありません。Apple IntelligenceのFoundamental Modelsはローカルで動作するAIなので、Pre-Babel Lensはインターネットに接続できない状況でも翻訳できるというのが大きな特徴。翻訳するテキストが外部に流出する恐れもありません。
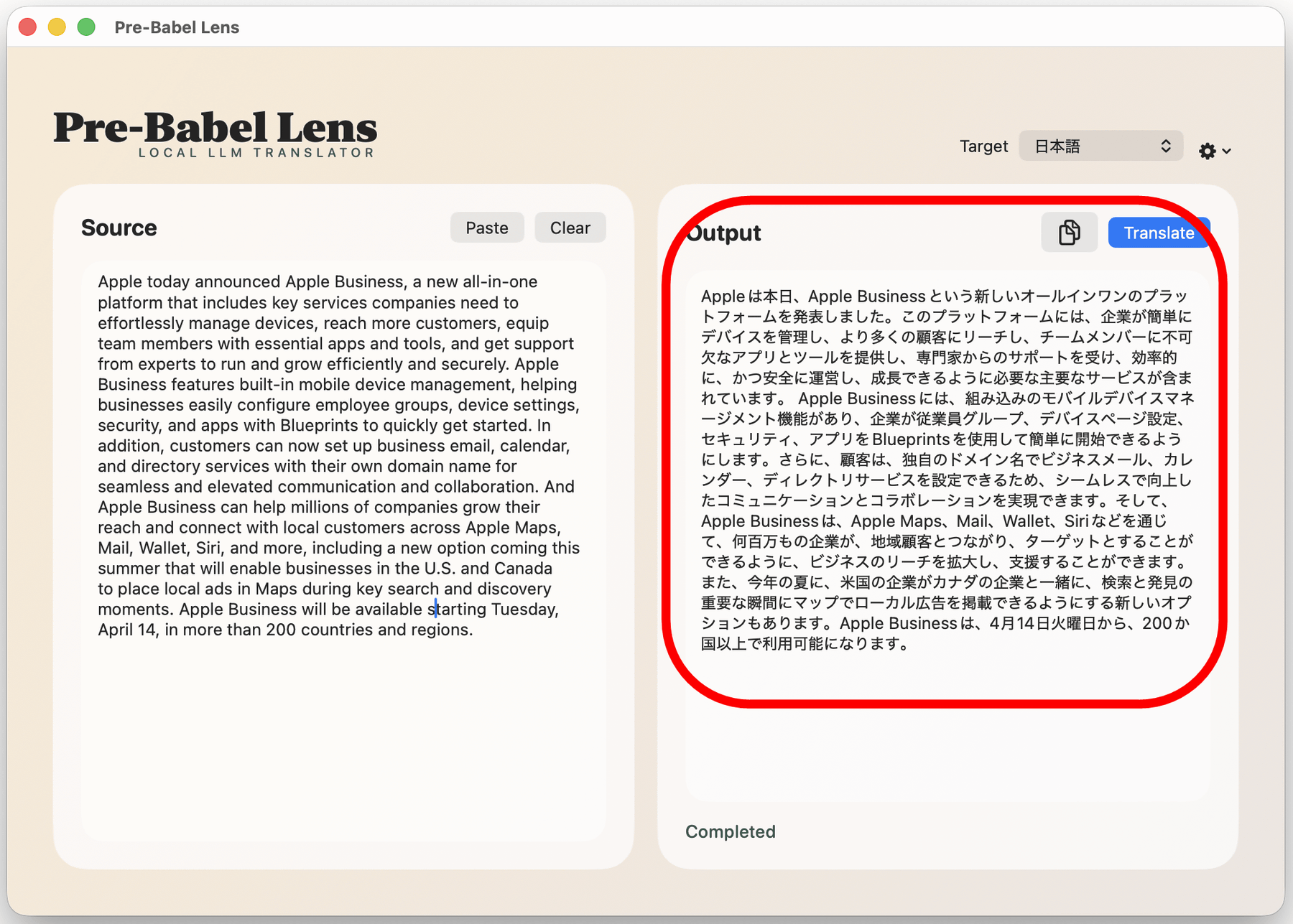
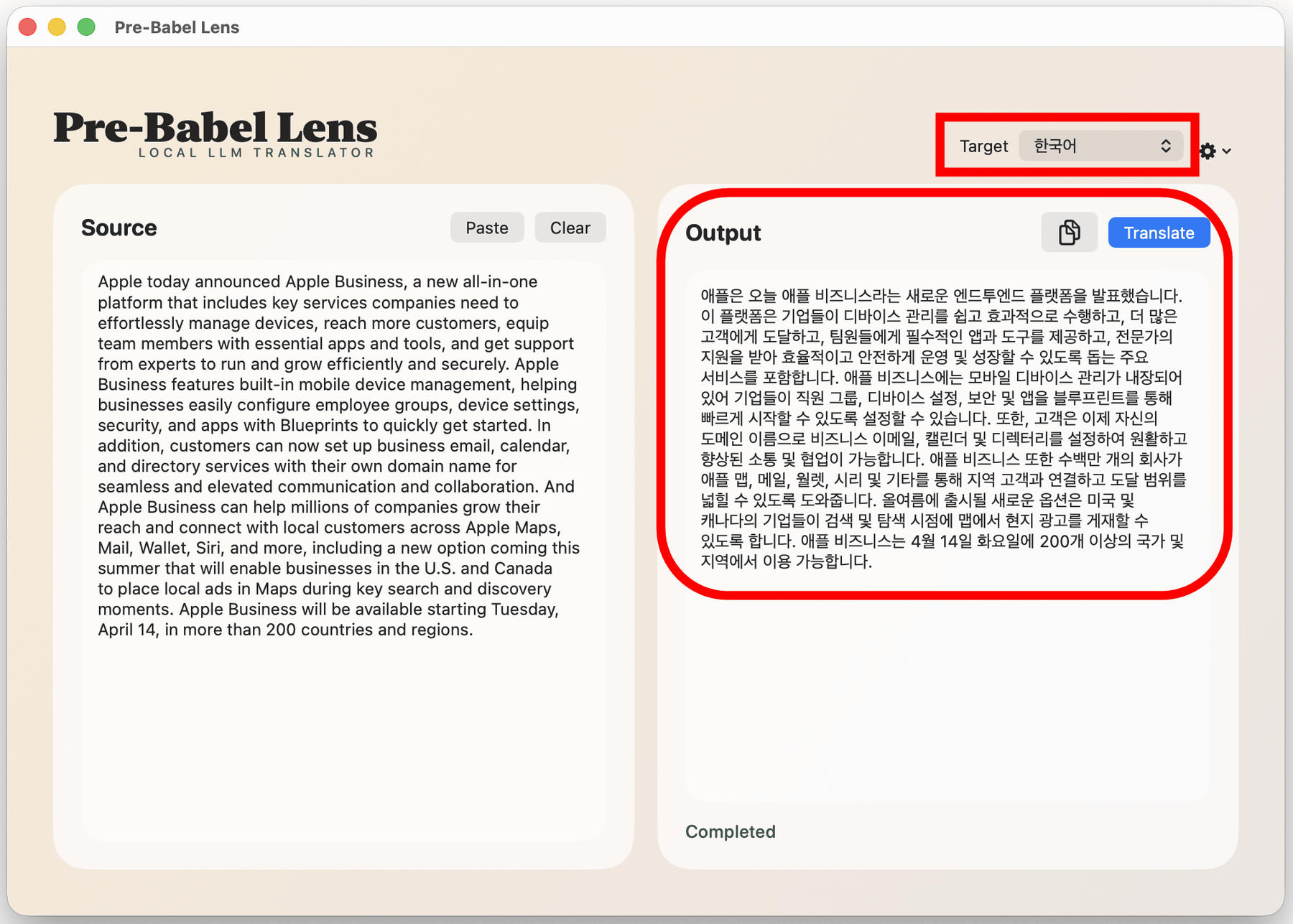
もちろん「Target」を切り替えると他の言語に翻訳することも可能です。以下は韓国語に翻訳してみたところ。
ただし、入力する文章が長いと翻訳結果がおかしなことになってしまうことがありました。

なお、開発者の藤井さんによると、Foundamental Modelsを使っている都合上、Pre-Babel Lensには以下の制限があるそうです。
・トークン量:4096。ショートカット起動するデスクトップ翻訳なら十分なトークン量ですが、DeepLやGPT、Geminiなどを使った翻訳に慣れていると、制限があることを感じます
・翻訳言語制限:制限のないLLMと違い、Apple Intelligenceが対応している15言語に制限されます
・CSAMセーフガード:未成年の行為を翻訳できません
・プライバシーセーフガード:個人名と日時が入った文書をプライバシー行為であると判断し、翻訳を止めることがあります
・政治的セーフガード:特定の国、主張に関わる文書の翻訳を拒否することがあります
・関連記事
無料であらゆる動画の字幕を自動で文字起こし・修正・編集・翻訳ができるオープンソースの字幕エディター「Subtitle Edit」を使ってみた - GIGAZINE
OpenAIが日本語対応の翻訳サイト「ChatGPT Translate」をひっそりリリース - GIGAZINE
無料で使えるChromeの内蔵AI翻訳機能で投稿を自動翻訳できるWordPressプラグイン「Multilingual AI Translator」 - GIGAZINE
無料&広告なしで音声をテキストに変換できるアプリ「Notely Voice」レビュー、ネット接続不要でスマホのみでWhisperを実行して長文メモを簡単に作れる - GIGAZINE
自分の声をAIで再現して通話時に日本語から英語へ自動翻訳するPixel 10シリーズの「マイボイス通訳」がすごい - GIGAZINE
・関連コンテンツ




in AI, 動画, ソフトウェア, レビュー, Posted by log1i_yk
You can read the machine translated English article Pre-Babel Lens is a free local translati….