Moebius, an AI framework with 226 million parameters, demonstrates image interpolation performance comparable to that of 10 billion parameters, enabling the removal of unwanted objects and face replacement.

A joint research team from Huazhong University of Science and Technology in China and VIVO AI Lab has announced ' Moebius ,' a lightweight AI framework for '
Moebius Project Page
https://hustvl.github.io/Moebius/
[2606.19195] Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
https://arxiv.org/abs/2606.19195
GitHub - hustvl/Moebius: [ECCV 2026] Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance · GitHub
https://github.com/hustvl/Moebius
hustvl/Moebius · Hugging Face
https://huggingface.co/hustvl/Moebius
Inpainting is used to remove unwanted objects from photographs or to fill in areas specified by a mask in a way that blends seamlessly with the background. However, large-scale models that achieve high-quality interpolation require significant computation and memory usage, leading to challenges in processing time and implementation costs. Moebius is not simply a scaled-up general-purpose image generation model, but rather a 'specialist' model designed to be highly efficient specifically for the purpose of image interpolation.
The image on the left below shows the photo before processing, with a blue mask over the area to be removed. The image on the right shows the photo after processing with Moebius. You can compare the two by moving the slider bar left or right.
The image is effectively blurred, eliminating all crowds except for the couple walking down the street at night.
Unwanted objects were removed from the landscape photograph. No major flaws were observed.
This is what happens when you apply a large mask to a person's face and then perform image interpolation. While it's obviously a completely different face from the original, the photo itself is not flawed, and if you didn't know the original, it would look like a natural photograph.
Moebius's basic processing method involves first converting the input image and information about the missing regions into a compressed latent space, and then reconstructing the missing parts while removing noise in that space. Furthermore, it utilizes semantic clues from the entire image obtained from the intact regions to ensure that the generated result is consistent with the content of the scene.
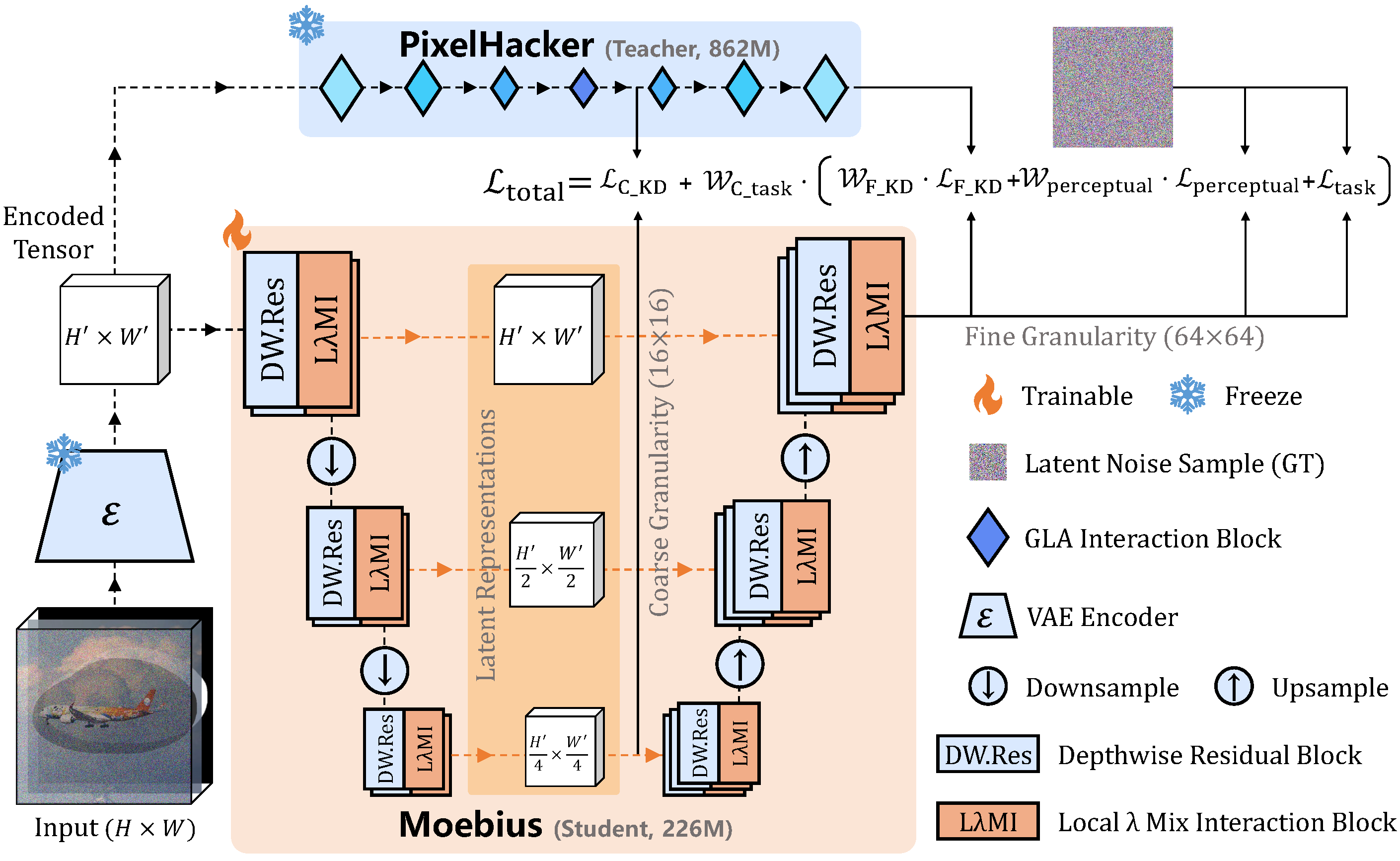
The central LλMI block is a mechanism that uses nearby information and semantic cues from the entire image together to naturally fill in missing parts of an image. LλMI consists of Local-λ, which reads the surrounding environment; Interactive-λ, which incorporates semantic information related to the entire image; and Mix-FFN, which efficiently transforms features.
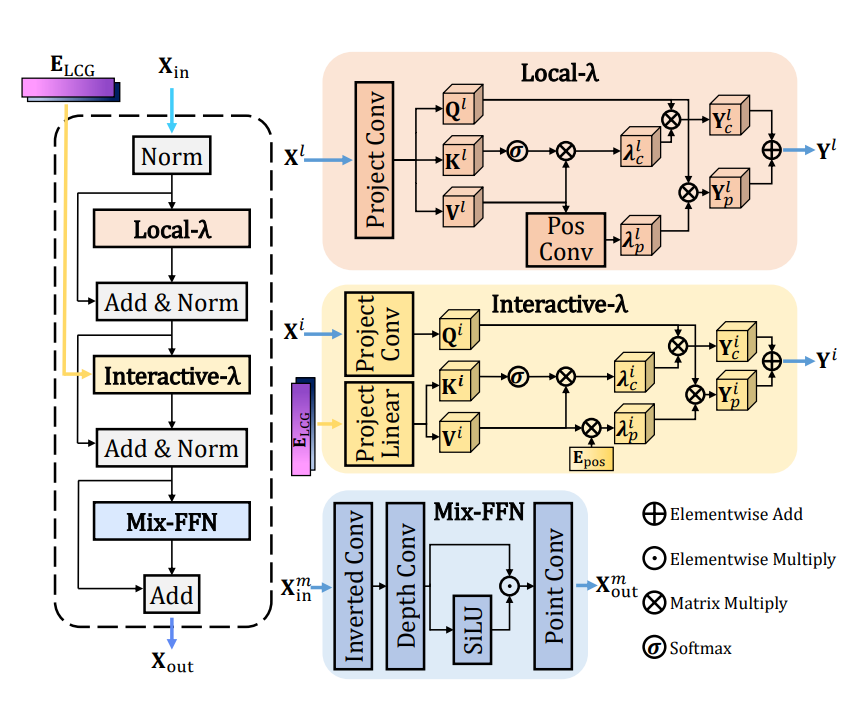
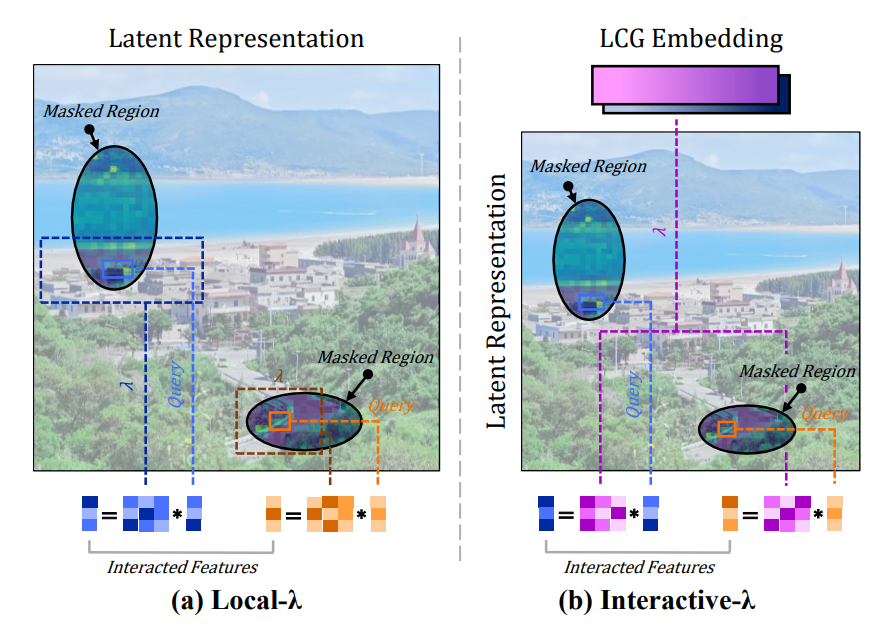
Local-λ interprets the surrounding environment by looking at the colors, patterns, and positions of objects around the missing area. Interactive-λ also refers to clues about what the entire image depicts, allowing it to naturally fill in details that would be difficult to determine from the surroundings alone.
Moebius was evaluated on the natural image dataset Places2 under multiple conditions with varying sizes and shapes of missing regions. When processing 512x512 pixel images on a single GPU (
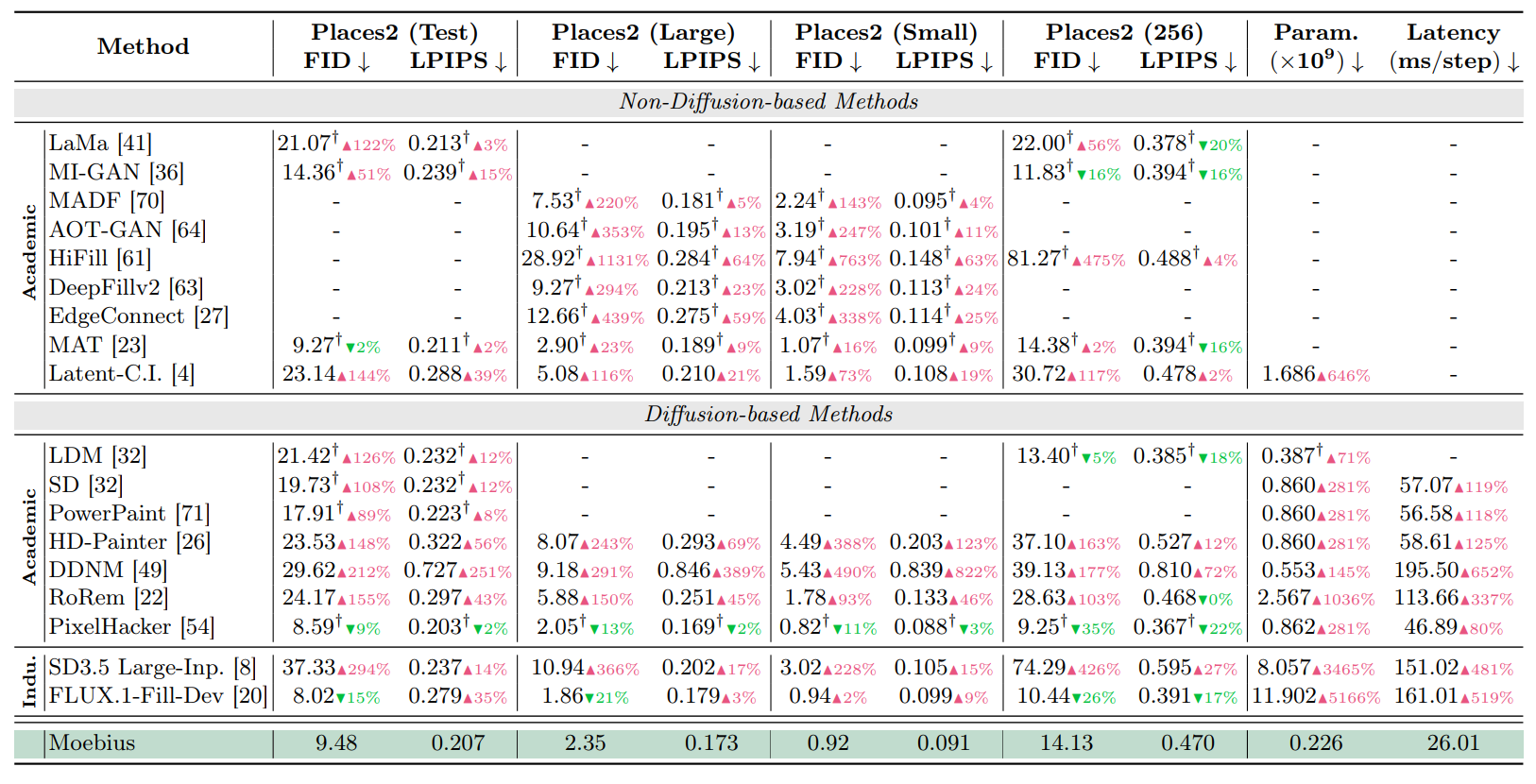
The paper also compares the effects of LλMI blocks and optimization processing in the Places2 test configuration. The conventional configuration had approximately 526 million parameters and 314 GFLOPs, but the configuration incorporating Local-λ and Interactive-λ reduced this to approximately 485 million parameters while maintaining almost the same image quality metrics. Furthermore, the final configuration combining Depthwise Convolution and Mix-FFN reduced the number of parameters to approximately 226 million and the computational load to approximately 154 GFLOPs. The evaluation values at that time were approximately 26 for FID and 0.26 for LPIPS, indicating that the quality of the interpolated images remained at a certain level even after optimization.
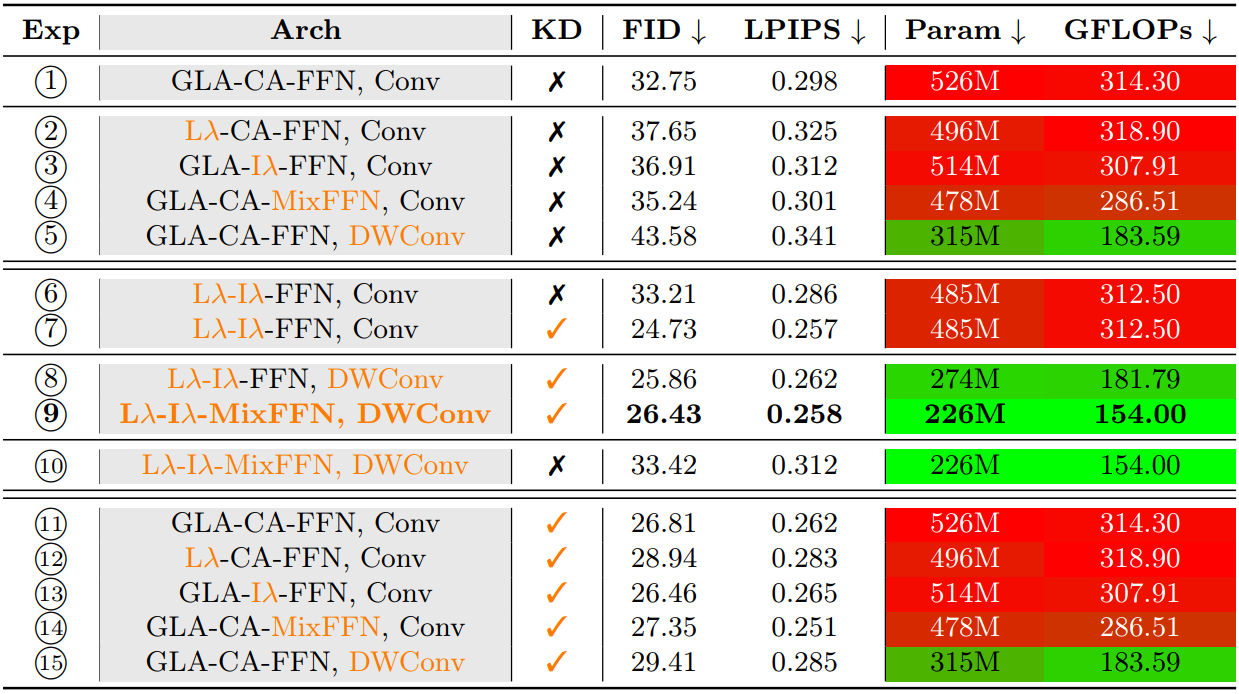
However, the paper also confirms that simply reducing the model size weakens its ability to understand images and lowers the quality of interpolation. Moebius compensates for the lack of expressive power in small models by combining efficiency improvements using LλMI blocks with knowledge distillation that learns features at multiple granularities.
The research team reported that Moebius, with approximately 226 million parameters, achieved a more than 15-fold speedup in total inference time while demonstrating image interpolation quality close to that of a 10B-class general-purpose model. At the same time, they argued that this result suggests that for applications with clear objectives, such as image interpolation and object removal, it may be possible to achieve both high quality and practical processing speed through task-specific, lightweight designs rather than simply increasing the size of the model.
Related Posts:





in AI, Posted by log1i_yk