Google DeepMind open-sources 'SynthID Text' for identifying AI-generated text
SynthID - Google DeepMind
https://deepmind.google/technologies/synthid/
SynthID: Tools for watermarking and detecting LLM-generated Text | Responsible Generative AI Toolkit | Google AI for Developers
https://ai.google.dev/responsible/docs/safeguards/synthid
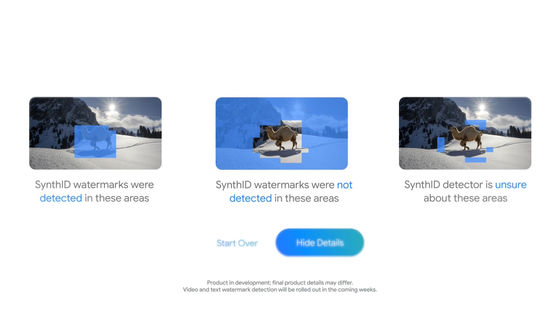
SynthID is a tool that identifies AI-generated content by adding a digital watermark to the content. The digital watermark added to an image by SynthID is not discernible to the human eye, so the image remains unchanged. In addition, because the digital watermark is embedded in the pixels of the image, it can be maintained even if the image is filtered, color-changed, cropped, or compressed.
Google launches 'SynthID,' a tool that uses digital watermarks on 'images generated by image generation AI' to prevent the spread of fakes - GIGAZINE

SynthID was initially a digital watermark that could only be used on images, but in May 2024 it will also be applicable to text and video.
Google extends 'SynthID', which puts digital watermarks on AI-generated content to prevent the spread of fake content, to text and video, how on earth do you put watermarks on text? - GIGAZINE

Google DeepMind has announced that it will open source SynthID's AI-generated text identification tool, 'SynthID Text,' so that anyone can identify AI-generated text for free.
Today, we're open-sourcing our SynthID text watermarking tool through an updated Responsible Generative AI Toolkit.
— Google DeepMind (@GoogleDeepMind) October 23, 2024
Available freely to developers and businesses, it will help them identify their AI-generated content. 🔍
Find out more → https://t.co/n2aYoeJXqn pic.twitter.com/4uRKYaz57Y
SynthID uses a variety of deep learning models and algorithms to watermark AI-generated content, embedding watermarks directly into the original content without compromising it. To identify AI-generated content, SynthID scans images, audio, text and video for watermarks, allowing users to determine if the content was generated in whole or in part by Google's AI tools.
For images and videos, it adds a digital watermark that is invisible to the human eye to the pixels, while for text, it is the words in the text that act as the watermark.
A 'token', the information processing unit of a large-scale language model (LLM), represents a single character, a word, or part of a phrase. To create a coherent sequence of text, an LLM predicts which token is most likely to be generated next, and this prediction is assigned a 'probability score' to the previous word and each potential token.
For example, for the phrase 'My favorite tropical fruit is ____', LLM completes the sentence by assigning tokens such as 'mango', 'lychee', 'papaya', 'durian', etc. Each token is given a probability score, and if there are multiple tokens to choose from, SynthID can adjust the probability score of each predicted token as long as it does not compromise the quality, accuracy, or creativity of the output.
This process is repeated throughout the entire generated text, so a single sentence may contain more than 10 adjusted probability scores, and a single page may contain hundreds of adjusted probability scores. Therefore, SynthID considers the final score pattern, which combines the model's word selection and adjusted probability scores, as a watermark in the AI-generated text. The longer the text, the more robust and accurate this method becomes.
The part highlighted in blue below functions as the SynthID watermark.

SynthID's text watermarking technology will be published as a research paper in Nature on October 23, 2024, and will be made available as an open source tool via the Responsible Generative AI Toolkit, guidance and essential tools for creating safer AI applications.
The SynthID text is also available on Hugging Face.
Synthid Text - a Hugging Face Space by google
https://huggingface.co/spaces/google/synthid-text

Related Posts:




in Software, Posted by logu_ii