How does GPT-4o encode and tokenize images?

GPT-4o, one of the models of the AI chat service 'ChatGPT,' first processes text received from humans into 'tokens,' then converts them into numerical vectors that are easy for AI to handle and performs calculations. It also performs similar processing on images, but programmer Oran Looney has speculated on what kind of processing it does at that time.
A Picture is Worth 170 Tokens: How Does GPT-4o Encode Images? - OranLooney.com
https://www.oranlooney.com/post/gpt-cnn/
When GPT-4o processes a high-resolution image, it cuts the image into tiles of 512x512 pixels and processes them, consuming 170 tokens per tile. Focusing on this number '170 tokens', Mr. Looney pointed out that 'it is too half-baked for the number used by OpenAI' and investigated why the number 170 came out.
The hypothesis is that each tile is converted into a vector of 170 features, which are then arranged in a contiguous fashion, because it is more efficient for deep learning models like GPT-4o to map images into a high-dimensional vector space rather than processing the pixel information directly.
A simple way to map an image into vector space is to first split a 512x512 image into 64 'mini-tiles'. Each mini-tile is 64x64 pixels, each with three color channels, RGB. If we lay these pixels flat out, they convert to 64x64x3, or 12,288 dimensions. We can think of this as converting the 512x512 image into 64 contiguous 12,288-dimensional vectors (one for each mini-tile), which requires only 64 tokens to process.
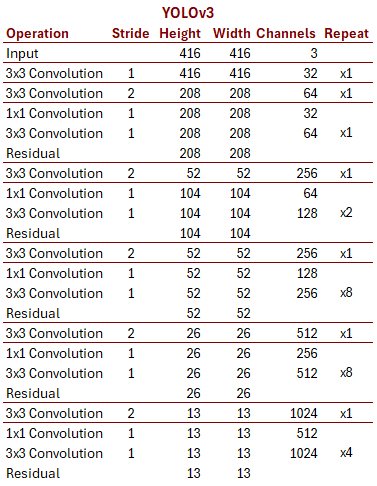
However, the above processing method is inefficient. Rooney also assumes that the number of dimensions processed by GPT-4o is 12,288, but the above method results in 64 mini-tiles, which does not match GPT-4o, which should process 170 mini-tiles. Rooney introduced YOLO, a type of convolutional neural network architecture, as a processing method to obtain an approximate value.
YOLO is characterized by arranging pixels on a flat grid, rather than arranging them on a minimum of 13x13, and then completing the processing. 13x13 is 169. However, when Rooney experimented based on the YOLO architecture, he found that while GPT-4o performed perfectly on 5x5 or less, its performance began to drop when it exceeded that size, and it could barely process embedding vectors on 13x13.
As for what GPT-4o actually does, Looney hypothesized:
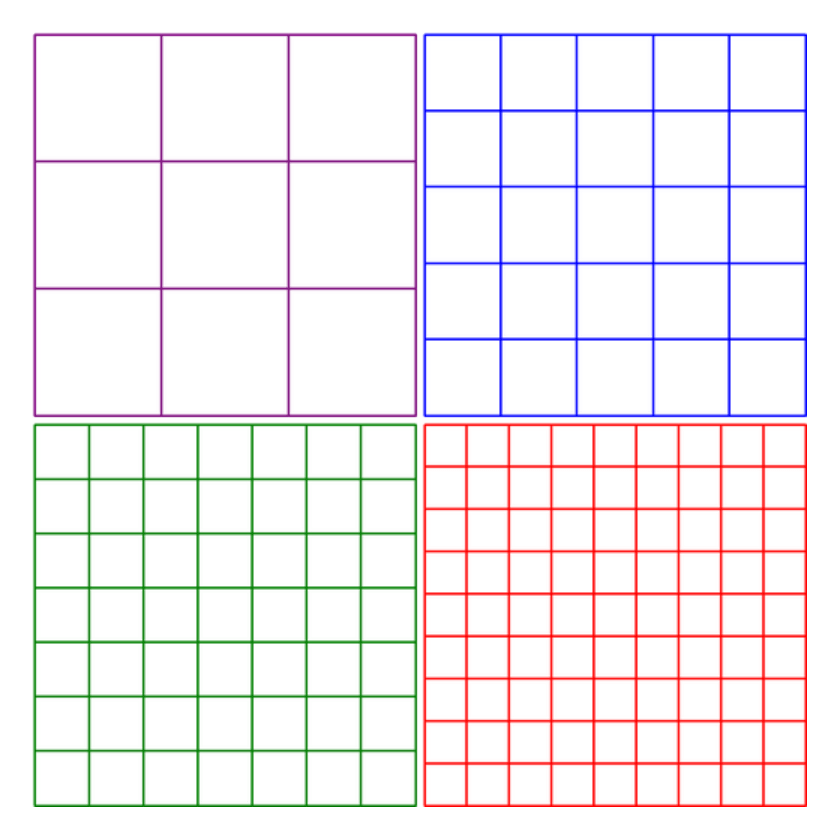
Rooney's hypothesis is that GPT-4o processes images by dividing them into several grids. First, it processes the entire image once, then divides the image into 3x3 and processes it, then divides it into 5x5 and processes it, and so on. This can be expressed as a formula: 1 + 3^2 + 5^2 + 7^2 + 9^2 = 1 + 9 + 25 + 49 + 81 = 165, which is close to the premise of 170. Adding a 2x2 grid and another '1' to this gives 170, which matches the premise, Rooney claims.
Considering that GPT-4o can only perfectly process up to a 5x5 grid, it is possible that it divides the grid into a maximum of 5x5 grids for processing as shown below. In this case, if we consider that 3 tokens are consumed for each tile and 1 token is consumed for each division process, the result is 3 × (1^2 + 2^2 + 3^2 + 4^2 + 5^2) + 5 = 170, which matches.

However, Looney points out that 'the numbers are not satisfactory,' and further states that he cannot explain why GPT-4o is so good at OCR (text generation in images).
Finally, Rooney concluded by saying, 'The mapping to the embedding vector seems to have an approach very similar to architectures like YOLO. I think the 170 tokens is not an approximation of the amount of computation required to process the image, but rather an accurate calculation, but the truth is unclear. The hypothesis of dividing the image into a grid and processing it is the best I could come up with, but it's not a simple one, so I'd love to hear from anyone who has a theory that fits better.'
Related Posts:







in Software, Posted by log1p_kr