Pointed out that there is a problem with the measurement method of some CPU benchmarks and performance cannot be evaluated correctly
CPU-Z’s Inadequate Benchmark – Chips and Cheese
https://chipsandcheese.com/2023/11/03/cpu-zs-inadequate-benchmark/
The information displayed on CPU-Z looks like this. It displays basic information about the hardware installed in your PC in a compact manner.
The 'Bench' tab allows you to measure benchmarks, and also has a function to send and compare results.
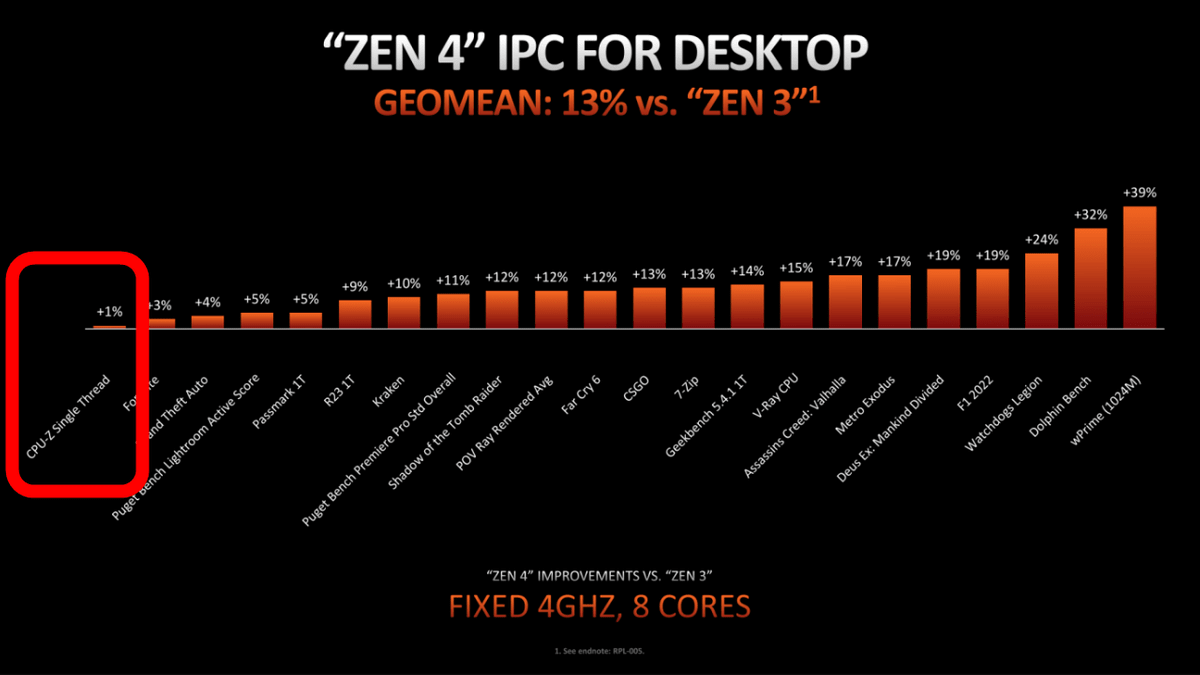
Benchmarks using CPU-Z also appeared in AMD's ZEN 4 and ZEN 3 comparison chart. According to the CPU-Z benchmark score, ZEN 4's performance has improved by only 1% from ZEN 3.
The CPU-Z benchmark is
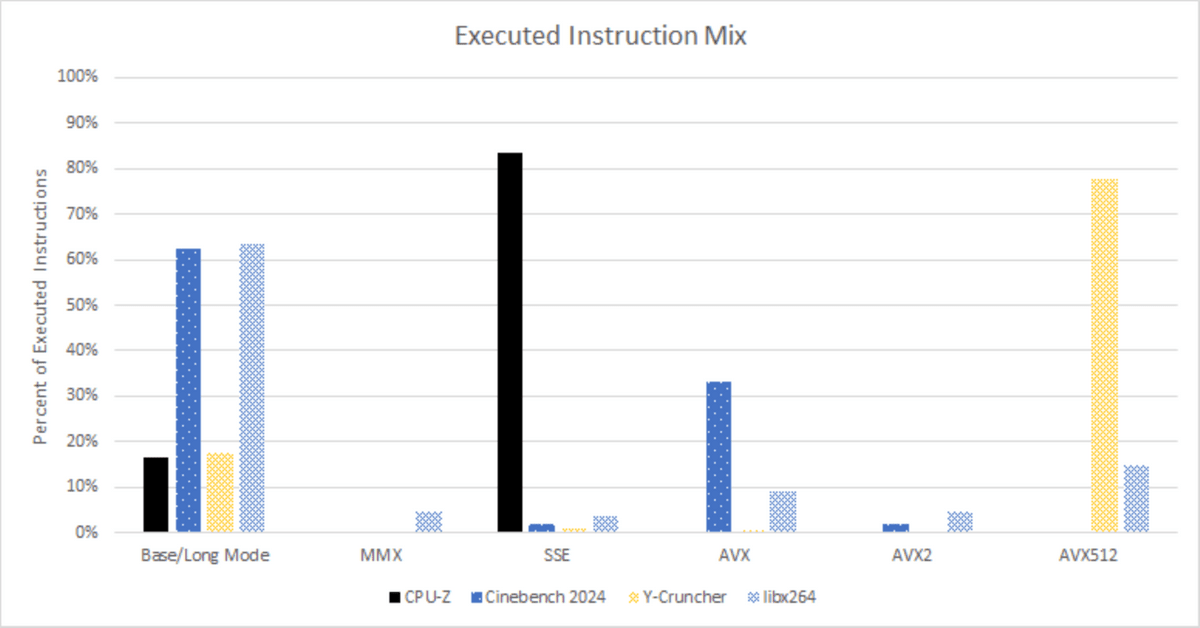
The average instruction length is 4.85 bytes due to SSE instructions and memory operands with large displacements . Due to the long average instruction length, front-end throughput on older Intel CPUs can be limited by the L1 instruction cache bandwidth of 16 bytes per cycle, but this limitation can be alleviated by the instruction (Op) cache, which allows the execution engine is only a problem if you can reach high enough IPCs that front-end throughput becomes an issue.
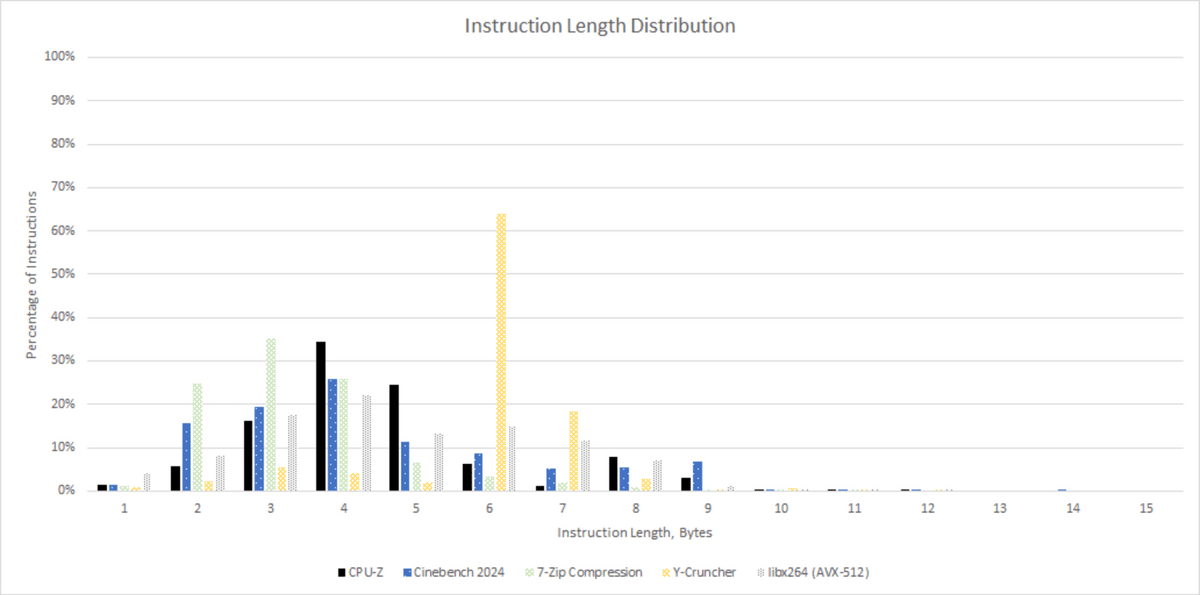
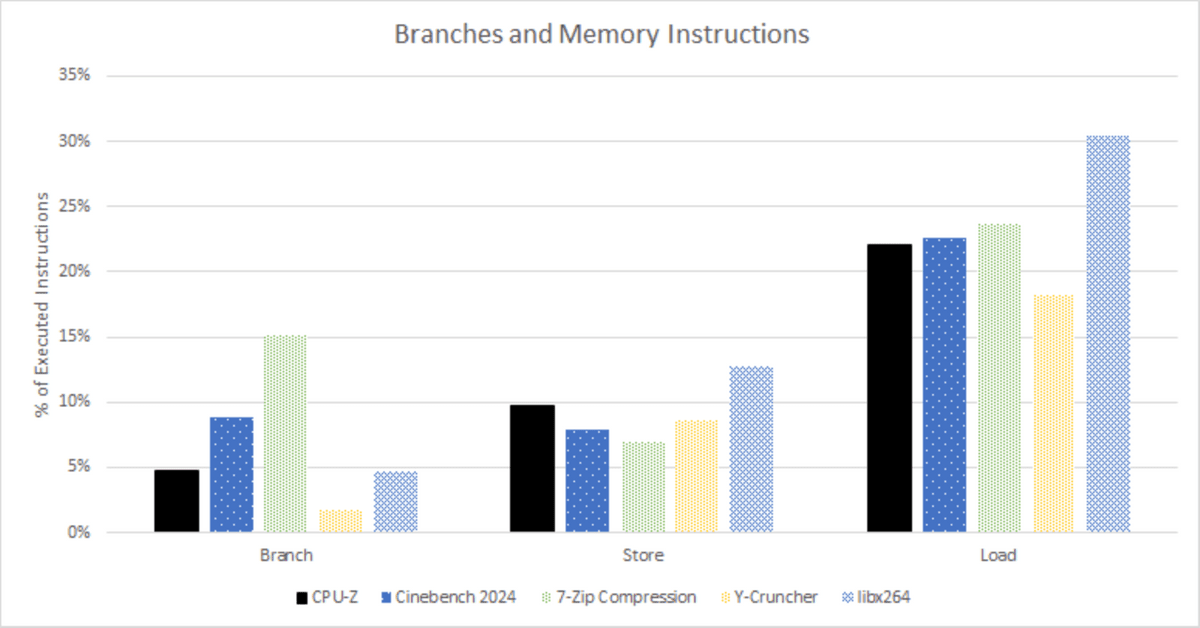
The CPU-Z benchmark also has a typical mix of memory accesses, but less gaming, compression, and branching compared to Cinebench 2024.
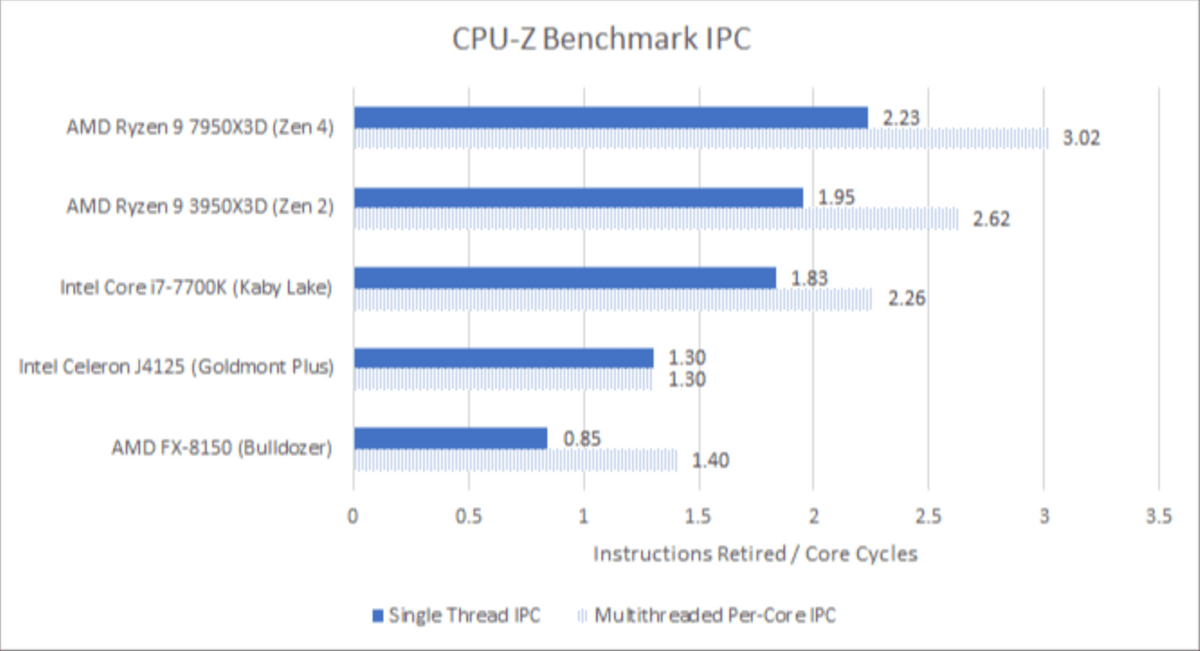
CPU-Z is an IPC benchmark, and when tested on five architectures: ``Zen 4'', ``Zen 2'', ``Kaby Lake'', ``
Among the above, the results of analyzing the operation of three CPUs, AMD Ryzen 7950X3D with Zen 4 architecture, Intel Core i7-7700K with Kaby Lake, and Intel Celeron J4125 with Goldmont Plus, using a top-down analysis method are shown in the figure below. This analysis allows you to investigate which factors are causing bottlenecks by displaying the work done by the CPU
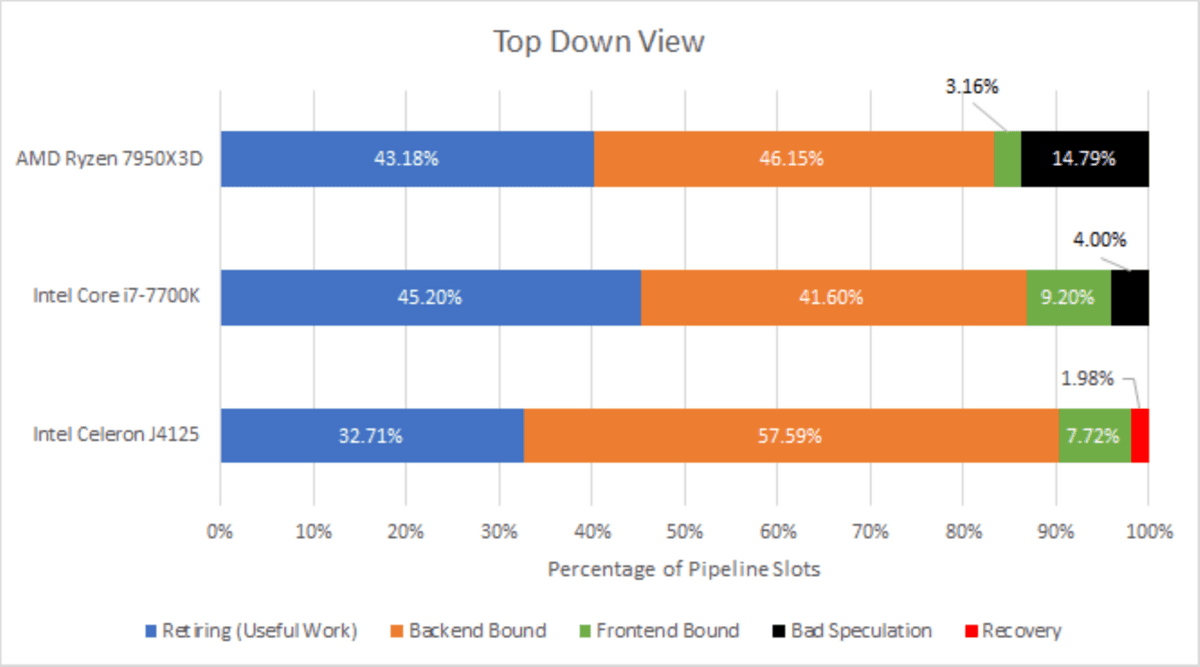
Each pattern represents the following meaning.
・Retiring
Cycles spent on successfully executed tasks.
・Backend Bound and Frontend Bound
Cycles in which the slot is empty for some reason and no task is performed, that is, stalled cycles, are counted as these two items. If the slot was empty because the front end was not supplying instructions, it would be Frontend Bound, while if the backend was unable to process the instructions due to lack of resources such as load buffers, it would be Backend Bound.
・Bad Speculation and Recovery
A Bad Speculation label is applied when the CPU speculatively executes an instruction by predicting the branch result, but the branch result is incorrect and the calculation is wasted. Goldmont Plus cannot recover from prediction mistakes immediately, and like AMD's Athlon, it must wait for the incorrectly predicted branch to retire, and the cycles spent on it are called 'Recovery'.
Although all three CPUs have good throughput, we can see that the backend is the bottleneck. If we take a closer look at the contents of the backend, we can break it down into stalls caused by memory, such as waiting for a load, and stalls caused by waiting for calculations to complete. In CPU-Z, the core is the bottleneck.
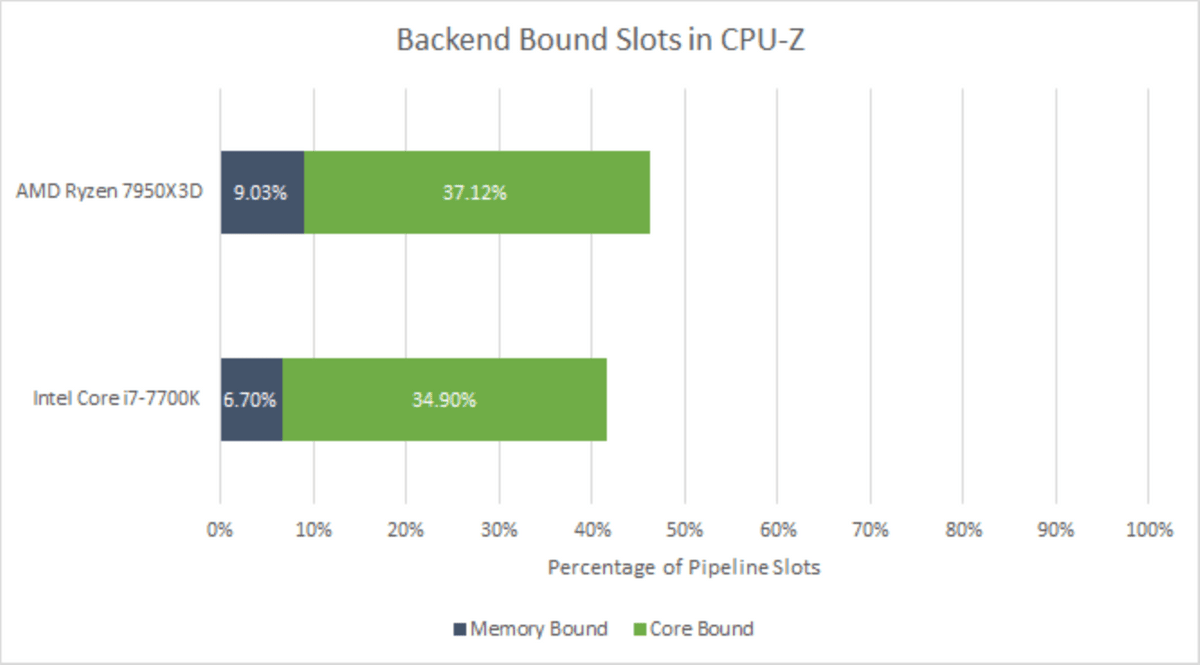
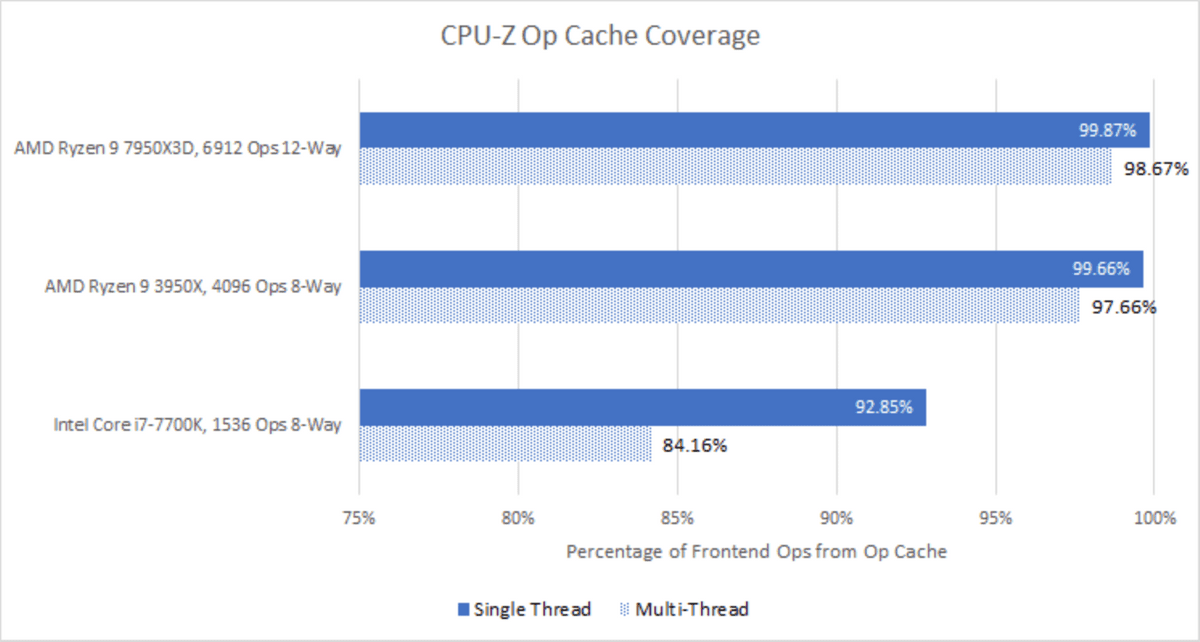
Many other workloads, such as games and Cinebench 2024, tend to be bottlenecked by memory, but CPU-Z operates with very small amounts of data that fit within the 32KB L1 data cache, so the cache hit rate is low as shown below. becomes high at a level close to 100%.

This high cache hit rate can also be confirmed in the front-end instruction cache. Since the area occupied by CPU-Z instructions is small, the entire instruction can be stored in the cache, and the element of ``supply of instructions to the core'' cannot be measured.
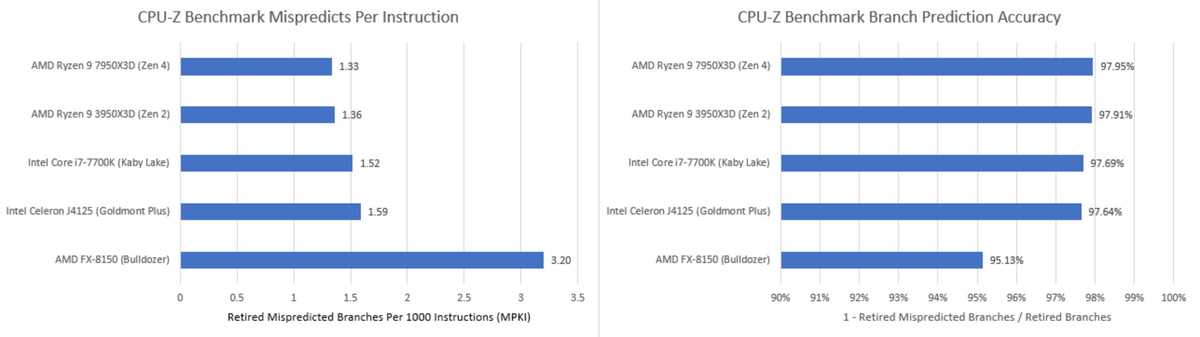
Additionally, CPU-Z's branch prediction was easy, with all CPUs able to accurately predict branches with accuracy in the low 90% range. AMD has used a lot of die area to improve the accuracy of the branch predictor, but it is hardly reflected in the CPU-Z score.
Benchmarking is difficult and cannot accurately reflect the various applications that users run. However, as Jim Keller , a microprocessor engineer who was involved in the design of AMD's Zen and Apple's A4 to A7, said in an interview , the bottlenecks of today's CPUs tend to be memory access and branch prediction. Many benchmarks try to measure the performance of the two. CPU-Z benchmarks are far removed from real-world challenges, making them useless for both CPU designers and end users.
There is a more detailed analysis in the original blog post , so please check it out if you are interested.
Related Posts:







