The functions, adoption examples, and demos of the lightweight and open source library ``BudouX'', which separates Japanese words at appropriate positions and makes them easier to read, are like this, and are expected to be implemented easily in Chrome 119.

When viewing Japanese pages in a browser, line breaks often occur at strange positions, but unlike English, which puts spaces between words, Japanese does not have
Google Developers Japan: BudouX: A lightweight separator for easy-to-read line breaks
https://developers-jp.googleblog.com/2023/09/budoux-adobe.html
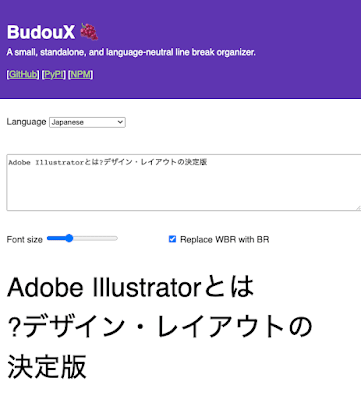
The image of using BudouX is shown below. Previously, depending on the screen width, a line break could occur in the middle of words such as 'cutting edge' or 'technology,' but by using BudouX, you can insert a line break before and after the word, making it easier to read. Ease of use can be improved.

BudouX uses
The model was trained using a blog corpus that had been analyzed by a joint research unit between Kyoto University Graduate School of Informatics and NTT Communication Science Laboratories . Detailed learning methods are explained in scripts/README in the repository.
In addition, adobe.com is an example of an actual use of BudouX. Adobe traditionally enforced proper line breaks by manually inserting delimiters, but when migrating the content management system ( CMS ) used to build adobe.com from Adobe Experience Manager to AEM Franklin . BudouX was introduced because the Japanese line break processing function was no longer available.
However, it was stated that three issues remained during implementation.
1: Accuracy issue
Among the words often used on Adobe's site, BudouX's standard model had a problem with low accuracy for words such as 'honorific words such as o, go,' and 'long katakana compound nouns such as digital experience platform.' . This problem was solved by developing an appropriate machine learning model by learning with Adobe.com data.
2: Problem with Kinsoku processing
Kinsoku processing is the process of adjusting the arrangement of characters so that certain characters do not appear at the beginning or end of a line. Normally, the browser automatically handles the prohibition process, but when using BudouX, problems occurred such as the BudouX delimiter being given priority and a question mark being placed at the beginning of the line.
Adobe solved this problem by adding rule-based Kinsoku processing.
3: Detailed customization issues
In some cases, you may want to manually insert a break at a specific position instead of BudouX's automatic processing. Adobe allows you to make adjustments for each page, such as ``manually adding line break rules,'' ``preventing BudouX from being applied to parts of the page,'' and ``adjusting the parameters passed to BudouX.'' While benefiting from BudouX's automatic processing in this part, it is now possible to make line breaks in small parts as desired.
A comparison image was posted that shows the difference between 'with' and 'without' line break processing at a glance. If there is no line break processing, a line break will be inserted in the middle of words such as 'tools', 'add', and 'access'.
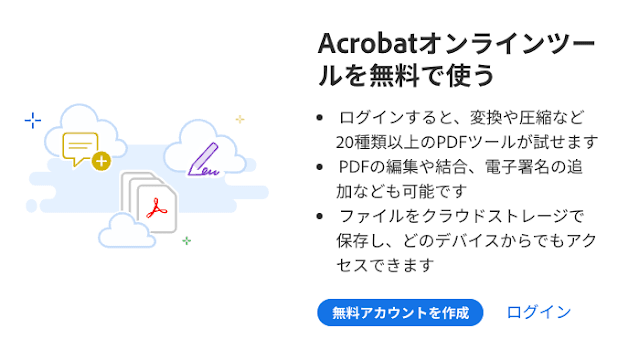
By adding line break processing using BudouX, it is possible to make the display easier to read as shown below.

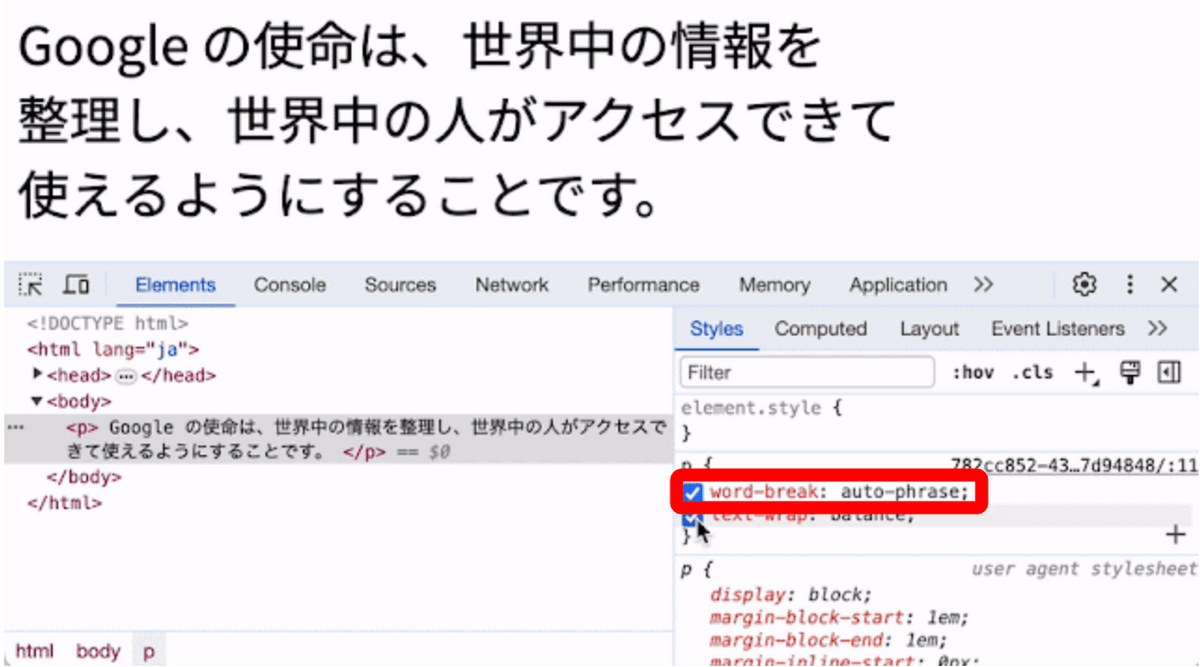
BudouX is part of the International Components for Unicode (ICU) , a library related to Unicode, internationalization, and localization, and is beginning to be used on various platforms, not just the web. In addition, BudouX is expected to be adopted in Android 14, which is scheduled to be released within 2023, and Chrome 119, which is scheduled to be released on October 31, 2023. Just set 'word-break: auto-phrase' to use BudouX's automatic line break function.
BudouX has JavaScript, Python, and Java libraries, and usage examples for each are also provided.
◆JavaScript
If you use the package management tool NPM, you can install BudouX with ' npm i budoux '. After installation, you can use the code below.
[code]import { loadDefaultJapaneseParser } from 'budoux' ;
const parser = loadDefaultJapaneseParser();
console.log(parser.parse('It's the weather today.')); // ['It's the weather today', 'It's the weather.' '][/code]
If you want to load it as an ES Module without using NPM, you can use the code below.
[code]<script type='module'> import {loadDefaultJapaneseParser} from
'https://unpkg.com/budoux/module/index.js';
const parser = loadDefaultJapaneseParser();
console.log(parser.parse('It's the weather today.')); // ['It's the weather today', 'It's the weather.' ']
</script>[/code]
Furthermore, a Web Components version is also available, and you can load BudouX with the code below.
[code]<script
src='https://unpkg.com/budoux/bundle/budoux-ja.min.js'> [/code]
After that, when you set text in the 'budoux-ja' element, markup to adjust text wrapping will be automatically inserted in the Shadow Root.
[code]<budoux-ja>What is the weather today? </budoux-ja>
<!-- Shadow Root -->
<span style='word-break: keep-all; overflow-wrap:
anywhere;'>Today is the <wbr>weather.</span>[/code]
◆Python
In Python, you can use the package management system pip to install BudouX with the command 'pip install budoux'. After that, you can use the code below.
[code]import budoux
parser = budoux.load_default_japanese_parser()
print(parser.parse('It's the weather today.')) # ['It's the weather today', 'It's the weather.' '][/code]
◆Java
The BudouX module is published as 'com.google.budoux' in the Maven Central Repository. After installation, you can use the code below.
[code]import com.google.budoux.Parser;
public class App {
public static void main(String[] args ){
Parser parser =
Parser.loadDefaultJapaneseParser();
System.out.println(parser.parse('Today is the weather.'));
// ['Today', 'It's the weather.']
}
}[/code]
◆Demo
We have prepared a demo so that you can see how BudouX actually works.
・Width 360px
・Width 540px
・Width 100%
A forum related to this article has been set up on the GIGAZINE official Discord server. Anyone can write freely, so please feel free to comment!
• Discord | 'Are you planning to use Google's parting library 'BudouX'? ' | GIGAZINE
https://discord.com/channels/1037961069903216680/1158330470031949866
Related Posts: