Announced robot AI 'RT-2' that can execute complicated instructions such as 'Move ○○' even in an environment where Google has not learned

On July 28, 2023, Google DeepMind announced a learning model `` Robotic Transformer 2 (RT-2) ' ' that can convert vision and language into action. Robots equipped with RT-2 can execute instructions such as ``Put strawberries in the correct bowl'' and ``Pick up objects that are likely to fall off the desk'', as well as instructions that are not included in the learning data and can be executed with high accuracy. .
RT-2: New model translates vision and language into action
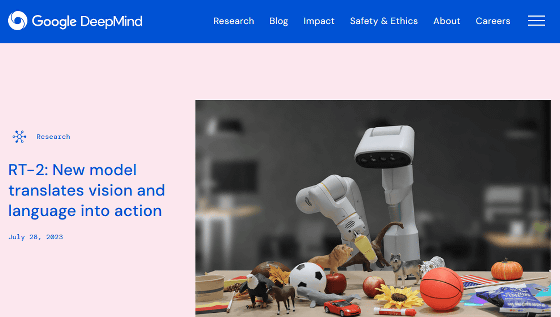
What is RT-2? Google DeepMind's vision-language-action model for robotics
https://blog.google/technology/ai/google-deepmind-rt2-robotics-vla-model/
A ``vision-language model'' that can give instructions in language to a robot equipped with a camera has existed so far, but in order to give instructions to a robot using an existing learning model, `` It was necessary to combine multiple learning models, such as a learning model that identifies images and a learning model that interprets language. The newly announced RT-2 is positioned as a ``vision-language-action model'' and is a single learning model that ``recognizes objects with a camera and acts according to verbal instructions. You can perform the action 'Do'.
RT-2 is trained using RT-1 data announced in December 2022. As a result of the research team conducting more than 6000 tests, RT-2 recorded the same success rate as RT-1 in learned tasks. Also, the success rate of unlearned tasks was 32% for RT-1, while RT-2 improved to 62%.
Examples of tasks that RT-2 can perform are as follows. I am able to correctly perform tasks such as 'put the strawberry in the correct bowl', 'lift the container that is about to fall off the desk', 'move the can of Red Bull to 'H'', and 'move the soccer ball to the basketball'.

Instructions such as 'Move Coke can to Taylor Swift', 'Move Coke can to 'X'', 'Move bag to 'Google'', and 'Move banana to '1+2' total' can be executed correctly.

Furthermore, it is possible to operate as instructed even when objects, backgrounds, and environments that have not been learned are targeted.

The research team has also released a demonstration video of RT-2. By clicking the image below, you can check the demonstration video that performs multiple actions including actions such as 'collecting green objects'.

Research papers and demonstration videos of RT-2 are available at the following links.
RT-2: Vision-Language-Action Models
https://robotics-transformer2.github.io/

Related Posts:






in Software, Posted by log1o_hf