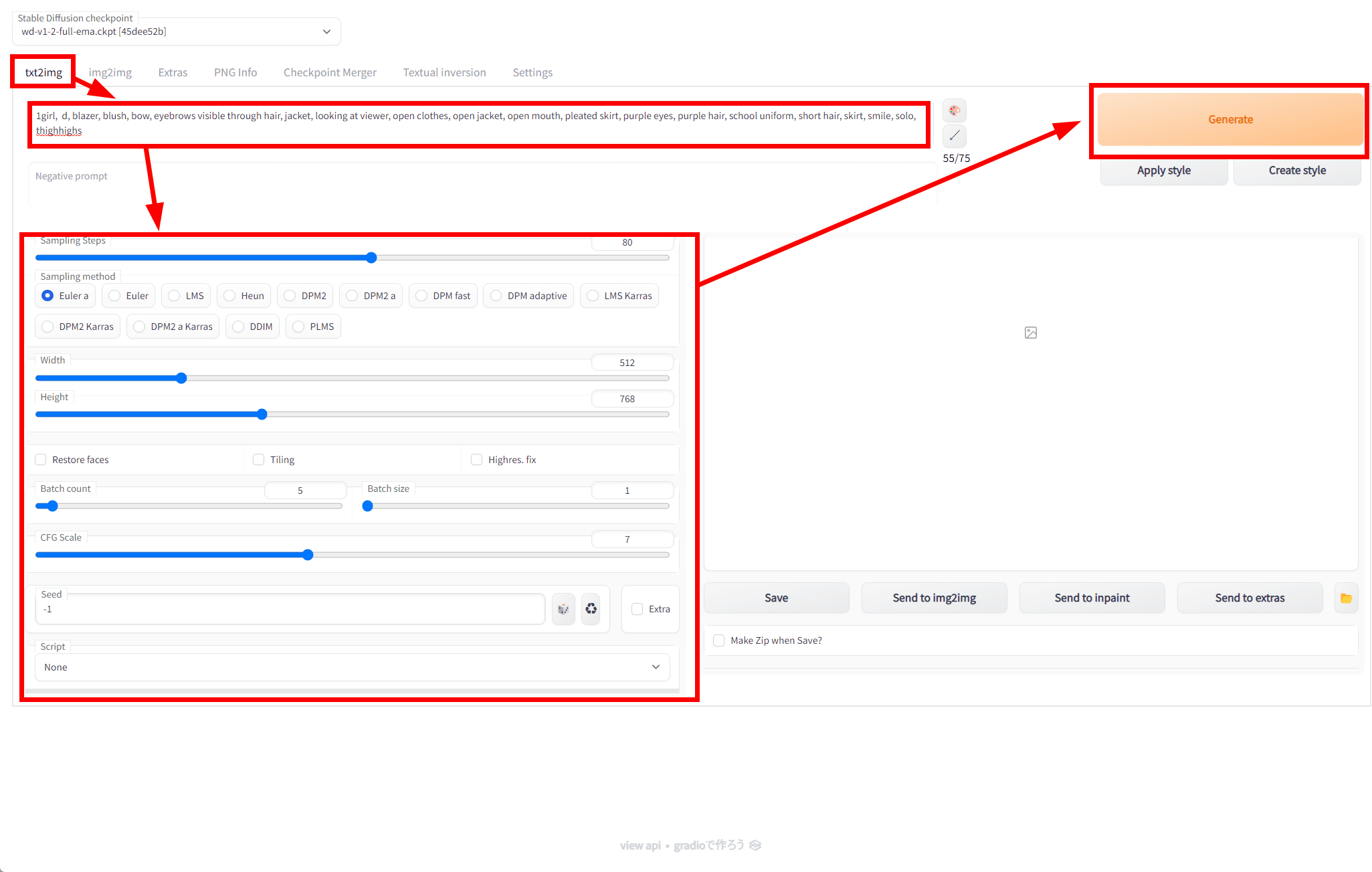
How to use ``Deep Danbooru'' in ``AUTOMATIC 1111 version Stable Diffusion web UI'' to find the Danbooru tag for the image generation AI prompt in the opposite direction from the illustration image Summary
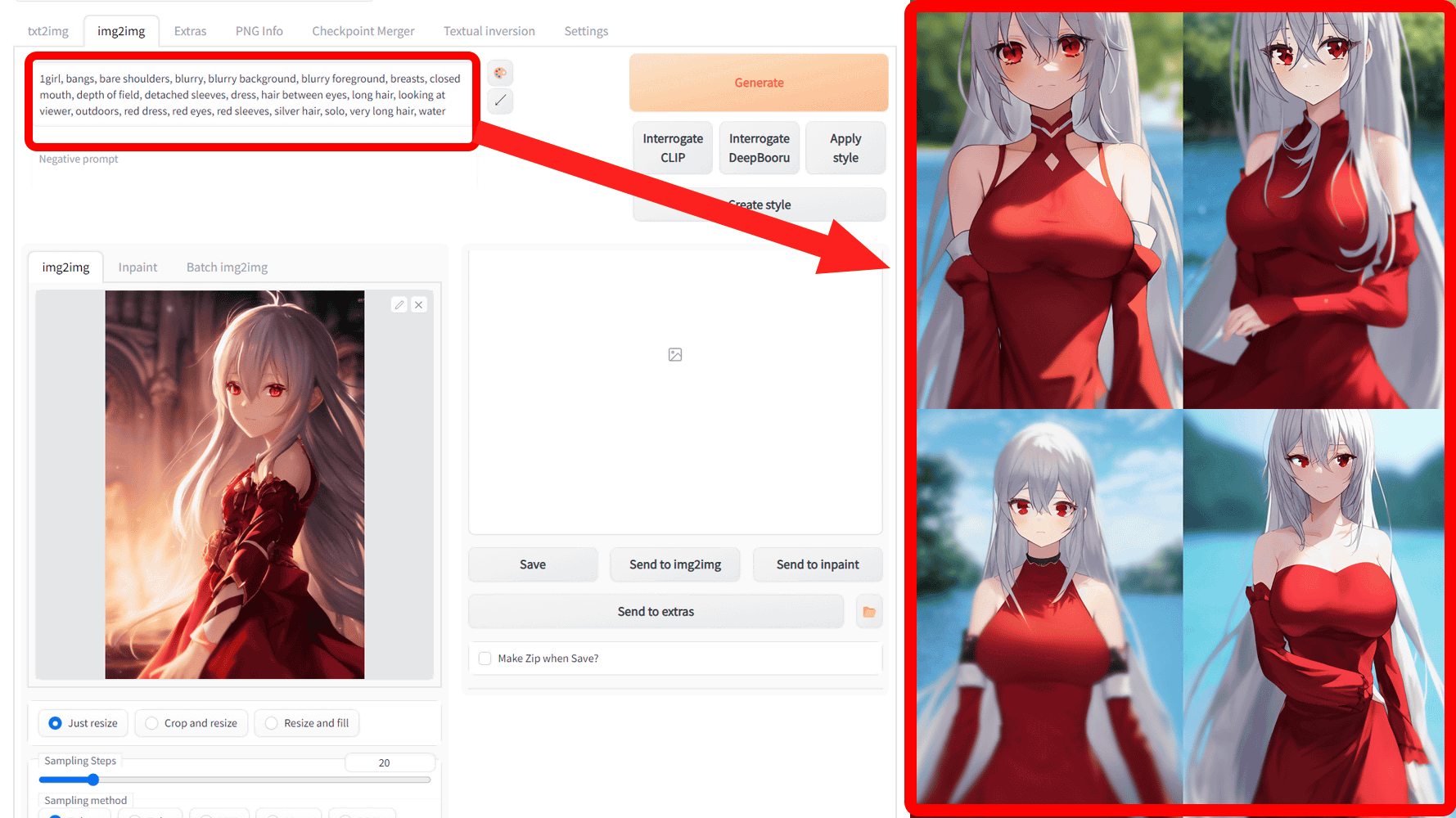
Image generation AIs such as Stable Diffusion generate images from character conditions called 'prompts'. Image generation AI specialized in 2D illustrations, such as
GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable diffusion web UI
https://github.com/AUTOMATIC1111/stable-diffusion-webui
GitHub - KichangKim/DeepDanbooru: AI based multi-label girl image classification system, implemented by using TensorFlow.
https://github.com/KichangKim/Deep Danbooru
The following article summarizes how to install and update the AUTOMATIC 1111 version of Stable Diffusion web UI.
Image generation AI ``Stable Diffusion'' works even with 4 GB GPU & various functions such as learning your own pattern can be easily operated on Google Colabo or Windows Definitive edition ``Stable Diffusion web UI (AUTOMATIC 1111 version)'' installation method summary - GIGAZINE
Also, you can understand the basic usage of the AUTOMATIC 1111 version Stable Diffusion web UI by reading the following article.
Basic usage of ``Stable Diffusion web UI (AUTOMATIC 1111 version)'' that can easily use ``GFPGAN'' that can clean the face that tends to collapse with image generation AI ``Stable Diffusion''-GIGAZINE
Deep Danbooru is not originally developed by AUTOMATIC1111, who develops Stable Diffusion web UI, but is a technology released by developer Kichang Kim in 2019. It is possible to estimate tags that are compatible with Danbooru tags from beautiful girl illustrations by deep learning that has learned a huge amount of illustration data on the Internet.
Source code release of “Deep Danbooru” – KANOTYPE BLOG
https://blog.kanotype.net/?p=833
Update of 'Deep Danbooru' for tagging beautiful girl illustrations – KANOTYPE BLOG
https://blog.kanotype.net/?p=812
Experimental release of “Deep Danbooru” to tag beautiful girl illustrations – KANOTYPE BLOG
https://blog.kanotype.net/?p=804
To use Deep Danbooru with AUTOMATIC1111 version Stable Diffusion web UI, first update AUTOMATIC1111 version Stable Diffusion web UI to the latest version, then open 'webui-user.bat' with a text editor such as Notepad or Vim .
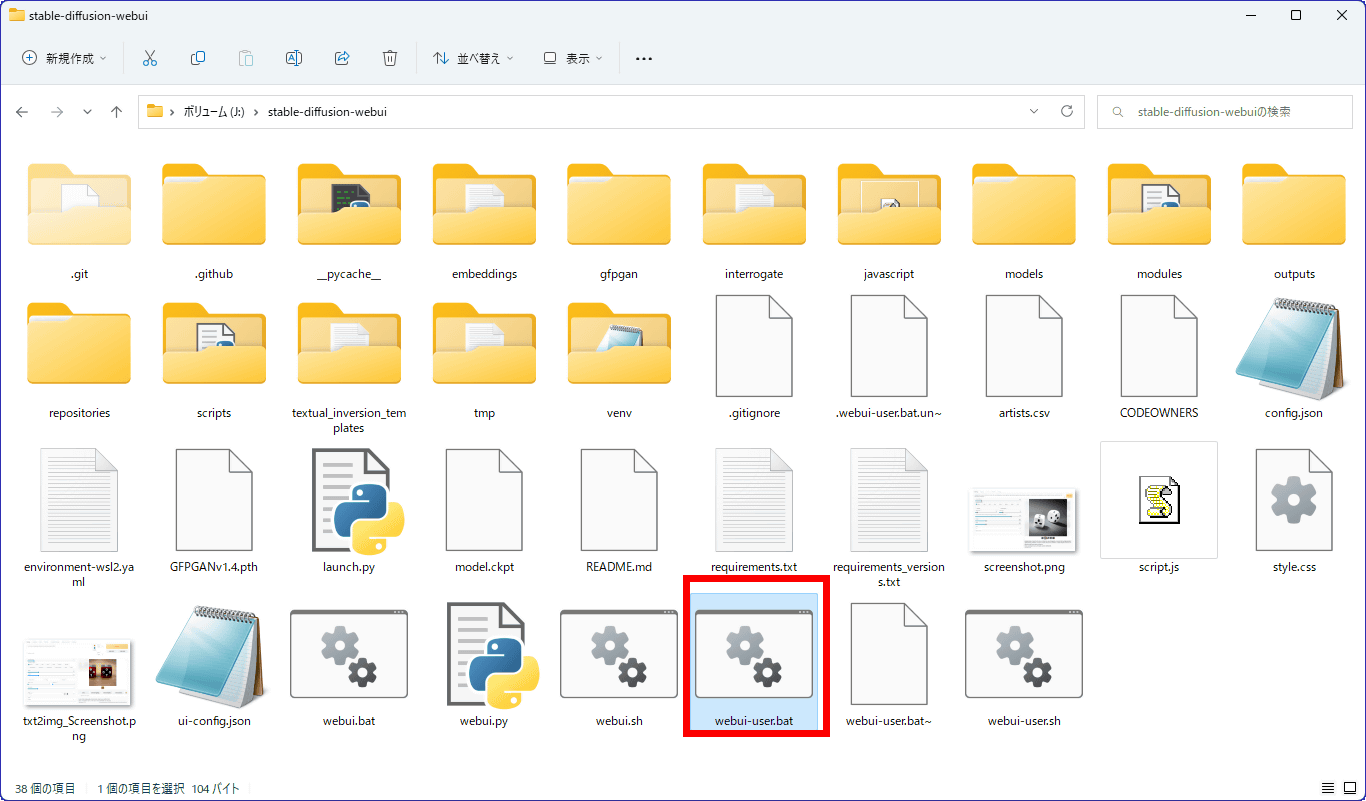
Make sure that line 6 has the following items:
[code]set COMMANDLINE_ARGS=[/code]
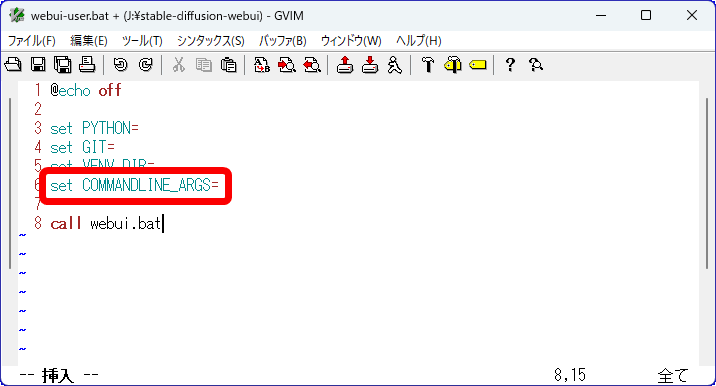
Replace this line with the following and save.
[code]set COMMANDLINE_ARGS=--deepdanbooru[/code]
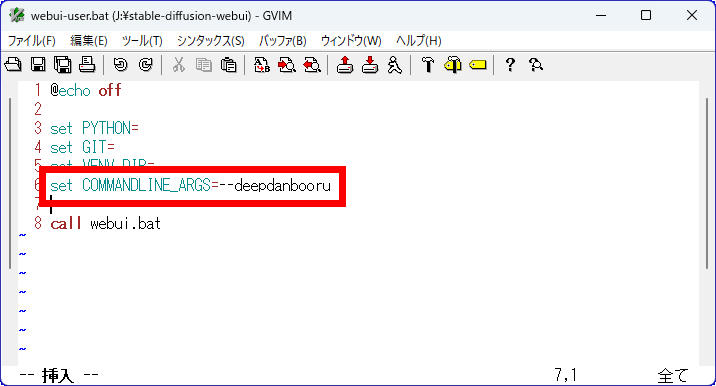
When you run webui-user.bat, the command prompt will start, but it will display 'Installing deepdanbooru', so wait for a while.
Once the installation is ready, the Stable Diffusion web UI will launch as usual as below.
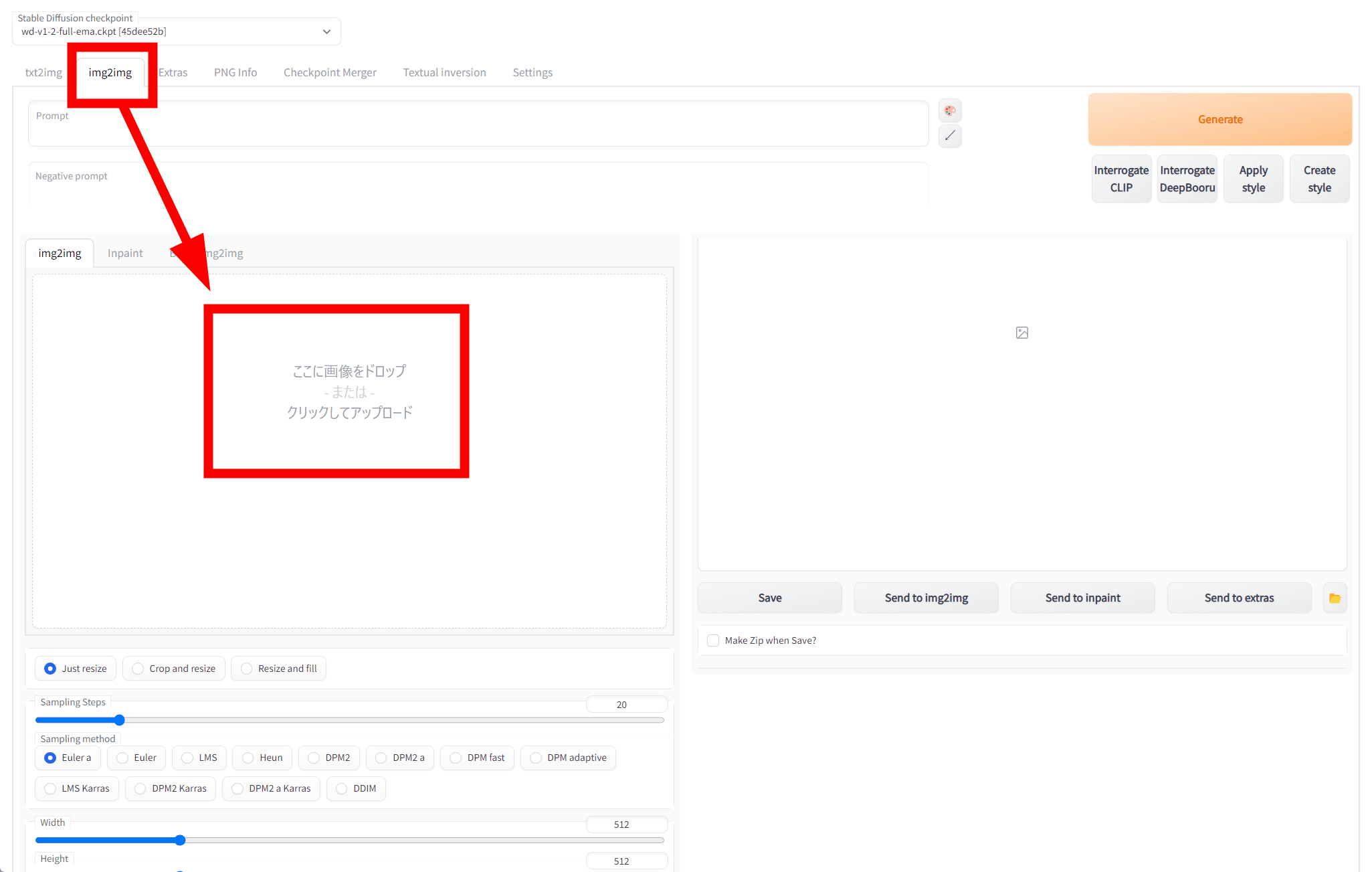
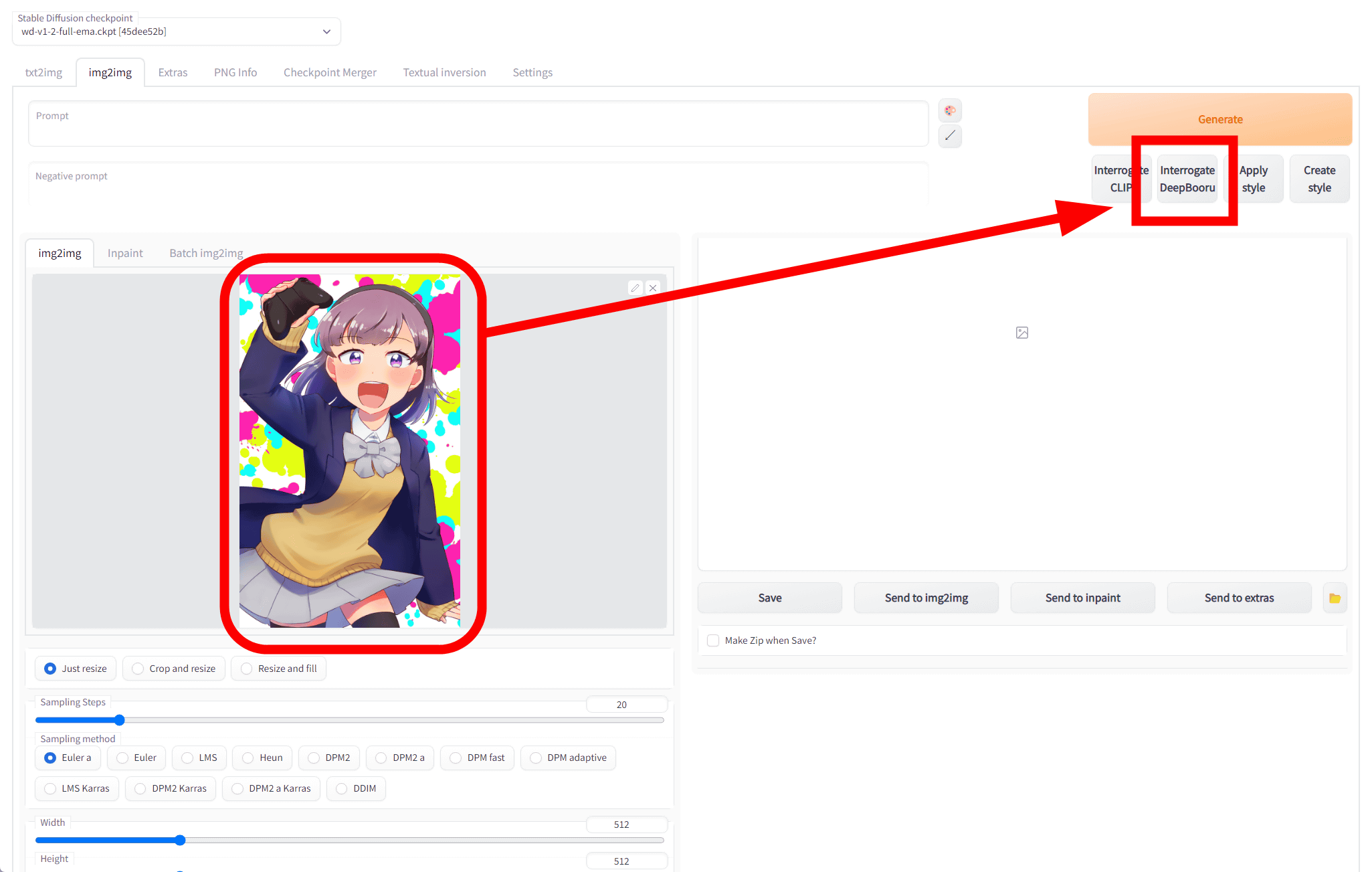
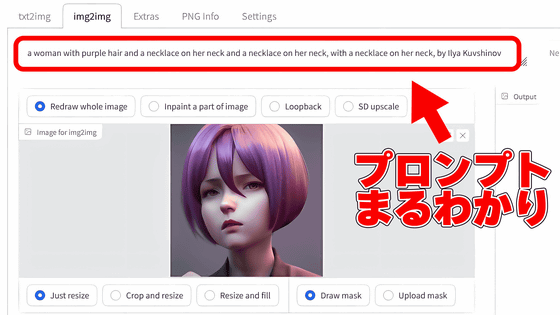
Open the Stable Diffusion web UI in your browser, click the 'img2img' tab at the top, click the field labeled 'Drop image here or click to upload', and select the image you want to estimate the tag.
This time, I will read the cover illustration of '
For the first time, Deep Danbooru will be downloaded from GitHub.
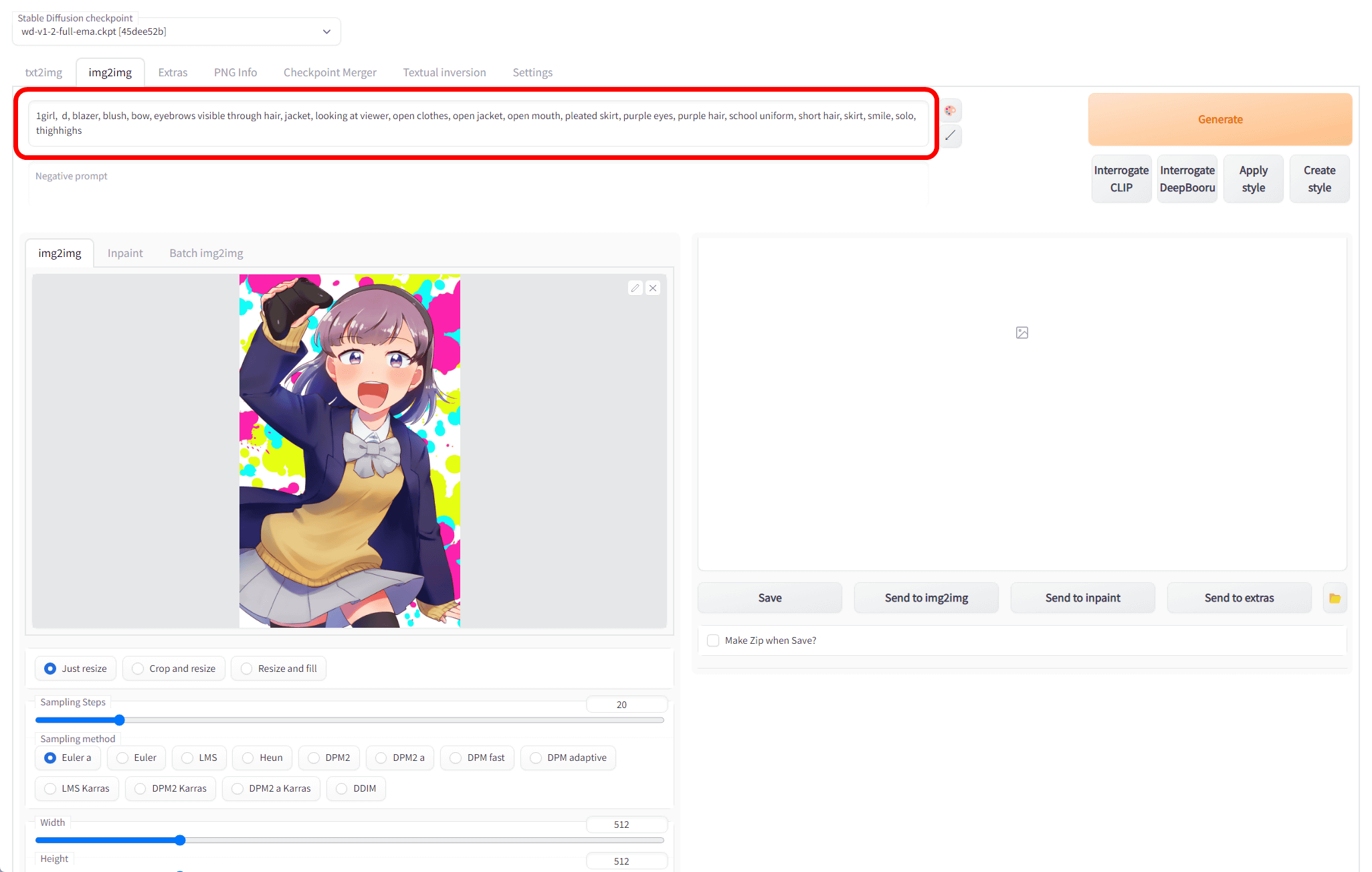
After a while, the prompt box at the top of the illustration says, '1girl, d, blazer, blush, bow, eyebrows visible through hair, jacket, looking at viewer, open clothes, open jacket, open mouth, pleated skirt, purple eyes, The tag 'purple hair, school uniform, short hair, skirt, smile, solo, thighhighs' was displayed.
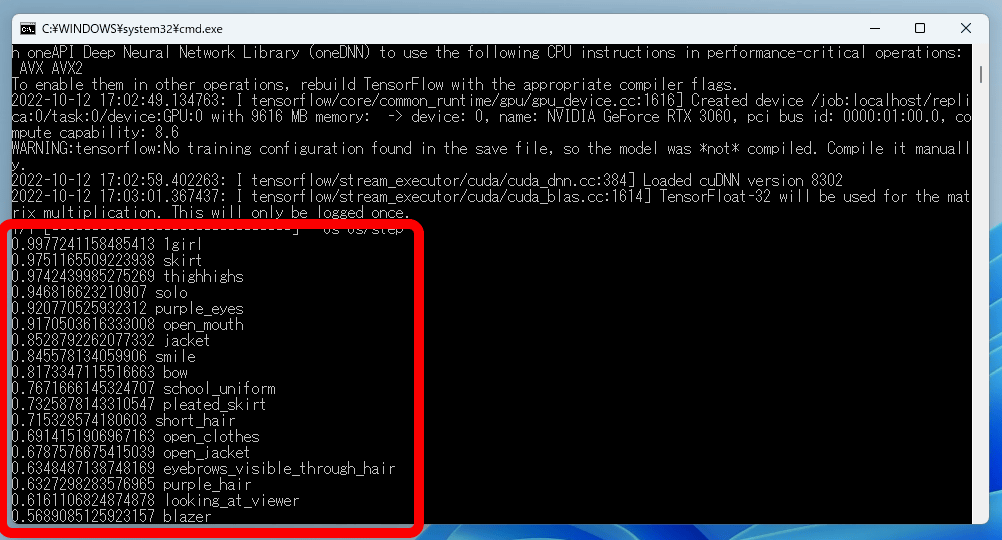
Looking at the command prompt, the tags are estimated and arranged in order from the most relevant tags as shown below.
Next, input this tag as a prompt to Waifu-Diffusion trained on the Danbooru-derived dataset and output the image. The following article summarizes how to introduce Waifu-Diffusion to the AUTOMATIC 1111 version of Stable Diffusion web UI.

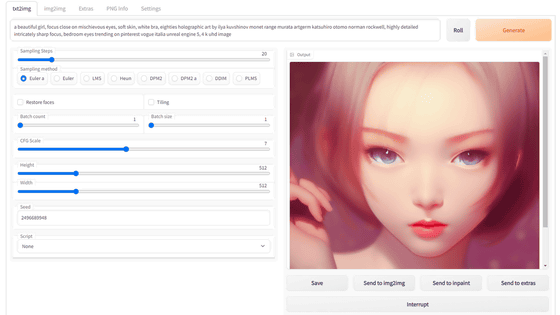
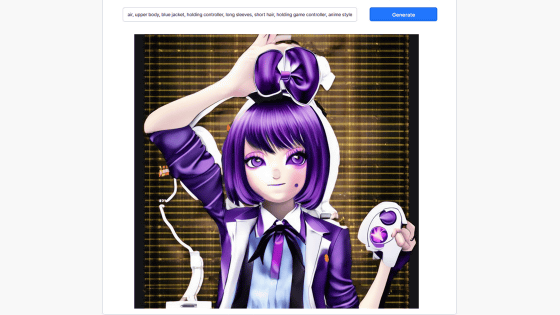
Toss the inferred tag into the 'txt2img' prompt field, enter the generation settings, and click 'Generate'. The model used this time is Waifu-Diffusion v1.2, with a sampler Euler a, generation steps of 80, resolution of 512 x 768 pixels, CFG scale of 7, and a batch count of 5.
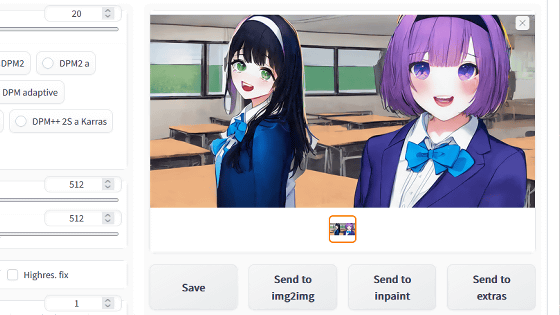
The generated 5 illustrations look like this. The purple hair and eyes, the uniform blazer with the front open, and the smile with the mouth open are reflected. Since the background and gamer elements were not reflected in the tag, they are not included in the illustration, but by extracting the general impression of the illustration as a tag, it is possible to generate illustrations with a common impression. .

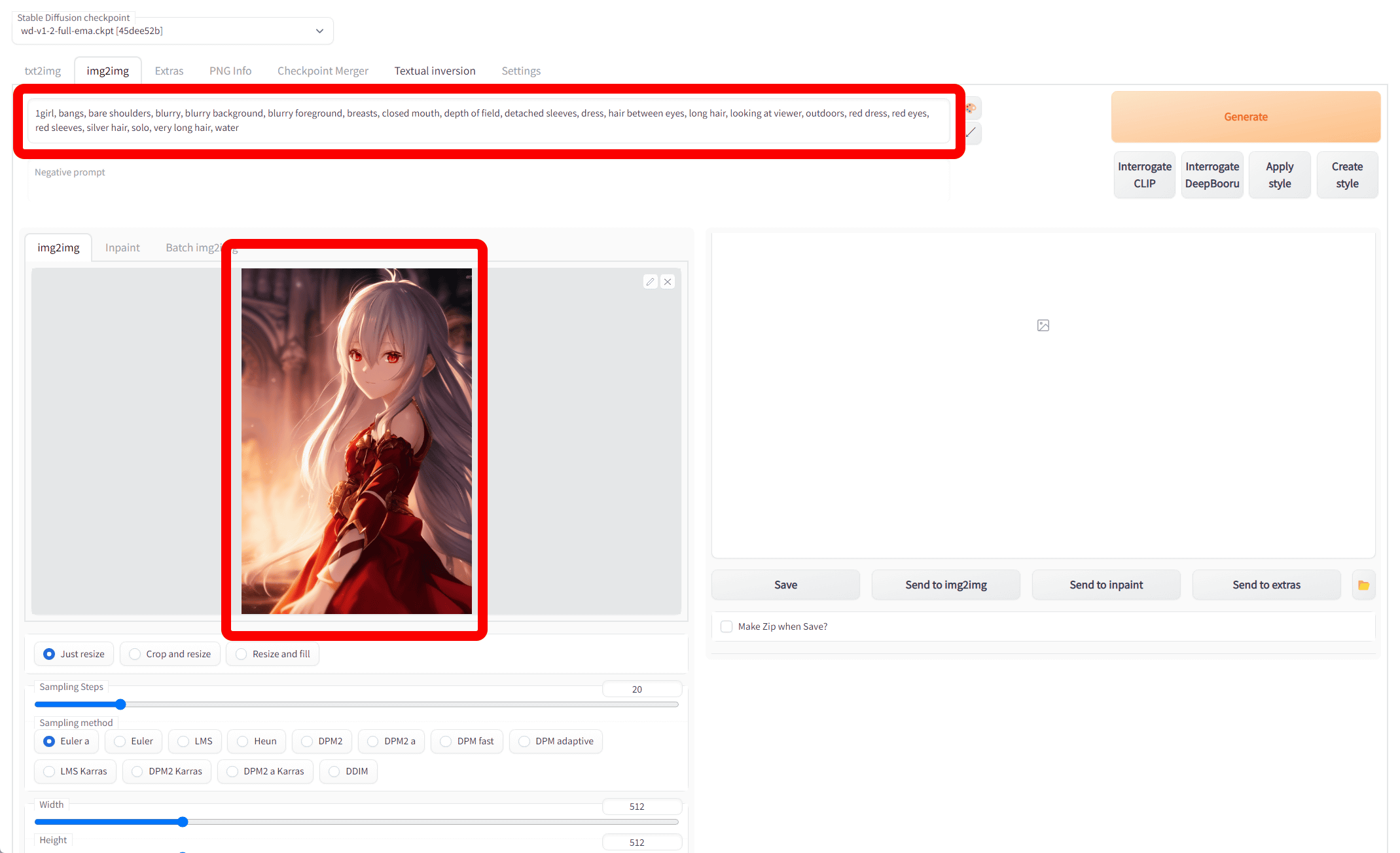
Next, let's use Deep Danbooru to estimate tags of images generated in advance by Waifu-Diffusion. The prompt for this illustration is 'Masterpiece extremely detailed CG unity 8k wallpaper of a loli girl with silver long wavy hairstyle and white marble glowing skin and perfect symmetrical pretty face with blush cheeks and glaring red eyes, wearing fantasic dress with many frills, standing in the baroque architecture, art by krenz cushart and violet_evergarden, golden hour lighting, strong rim light, intense shadows, bokeh', set negative prompt to 'out of frame, cropped', resolution 512 x 768 pixel sampler Euler a Generated with Waifu-Diffusion v1.2 with 100 generation steps, 9 CFG scales, and a seed value of 983541770.

After reading and analyzing with the img2img tab, the estimated tags are '1girl, bangs, bare shoulders, blurry, blurry background, blurry foreground, breasts, closed mouth, depth of field, detached sleeves, dress, hair between eyes, long hair , looking at viewer, outdoors, red dress, red eyes, red sleeves, silver hair, solo, very long hair, water'. Silver hair, red eyes, red dress, bangs, background blur, etc. are also indicated by tags, but for some reason the mysterious element 'water' is added.
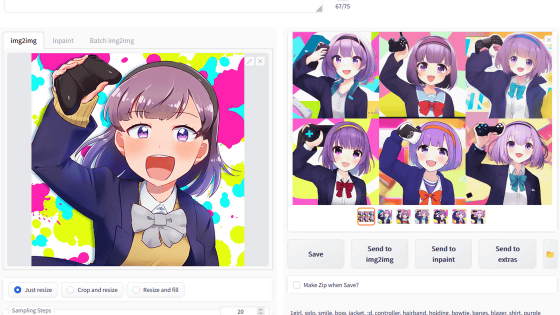
The following is an illustration of this tag generated with a resolution of 512 × 768 pixels, a number of generation steps of 100, a sampler Euler a, a CFG scale of 9, and a batch scale of 5. The red dress and red eyes are reflected, but the added 'water' shows that the coast and river-like scenery are spreading in the background. Also, there are many illustrations with red hair rather than silver hair, and the one on the bottom left shows two girls even though it says 1 girl.

This time, with the same tags and settings, I changed the model to Waifu-Diffusion v1.3 (epoch number 8, hash value d12b4159) and generated an illustration. Not only is everything drawn with silver hair, but the image quality is also improved, and you can see at a glance that the higher version of Waifu-Diffusion has generated a more accurate illustration.

Related Posts:



in Software, Web Service, Review, Anime, Manga, Creation, Web Application, Posted by log1i_yk