I found a website where you can easily use the image generation AI 'Stable Diffusion 2.0' for free, so I compared the generated results with 'Stable Diffusion 1.4' Review
Version 2.0 of the AI ``Stable Diffusion'', which generates images just by entering sentences (prompts), was officially released on November 24, 2022. A website where you can easily try out Stable Diffusion 2.0 was published, so I actually generated an image and compared it with the generation results of the conventional Stable Diffusion 1.4.
Stable Diffusion 2 | Baseten
When you access the link above, you will see a screen like the one below.
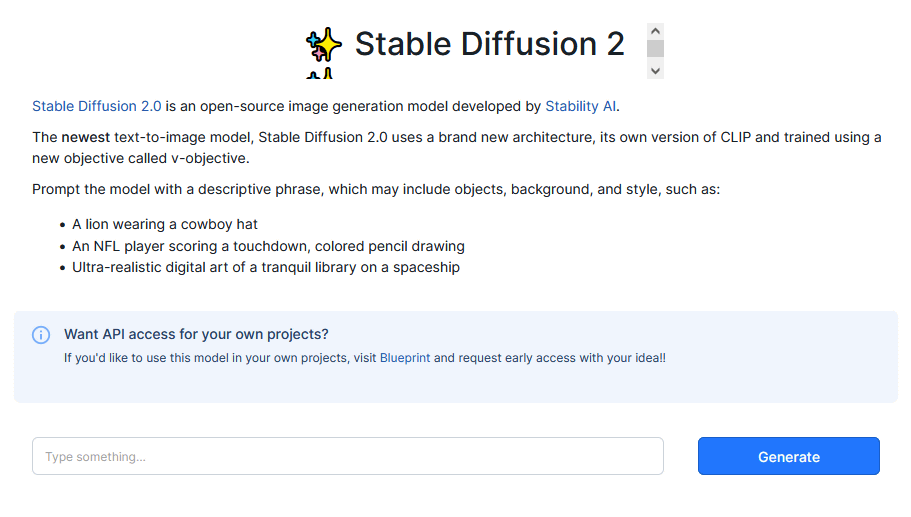
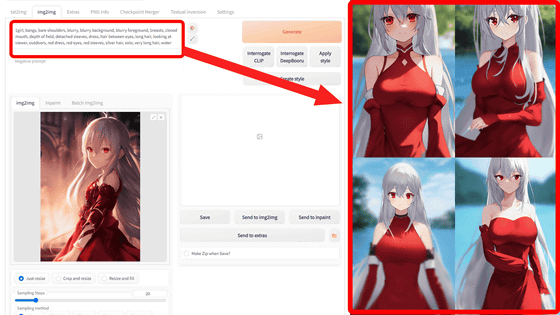
To generate an image, enter the prompt in the input area at the bottom and click 'Generate' on the right. This time, I entered the prompt 'A lion wearing a cowboy hat' as shown in the input example above.

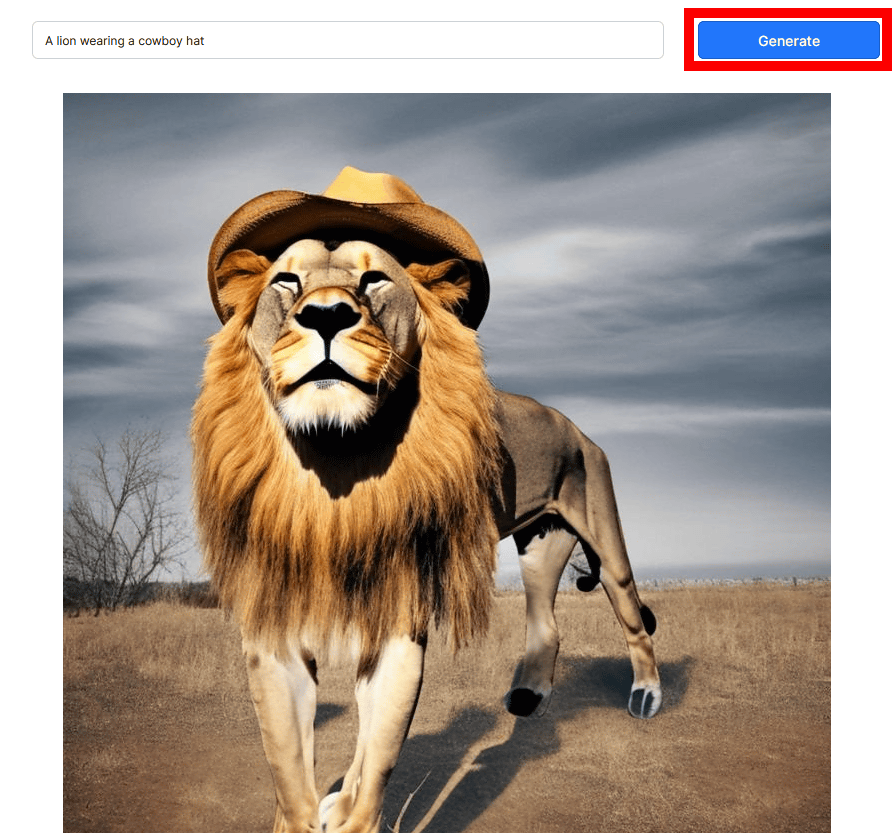
The generated result looks like this. We were able to output an image of a ``lion wearing a cowboy hat'' in about 30 seconds. If you want to generate again with the same prompt, click Generate again.
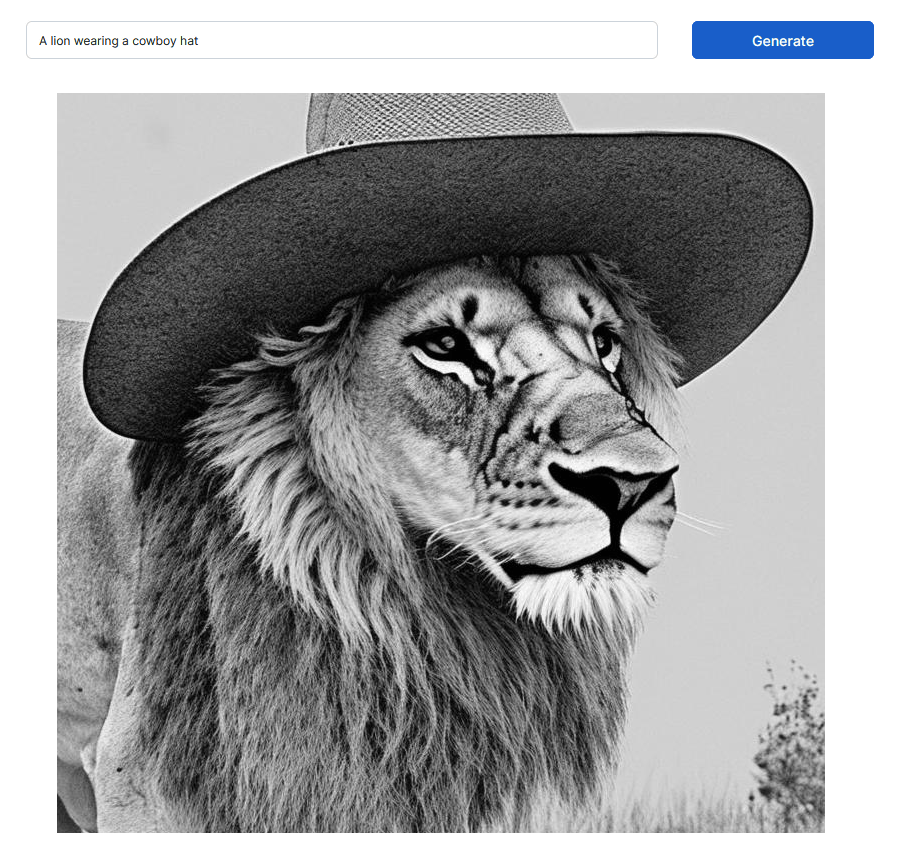
The generated result looks like this. This time I was able to generate a monochrome lion image.
Below are the results of generating 6 images with Stable Diffusion 1.4 using the same prompt. We found problems with images generated with Stable Diffusion 1.4, such as ``not wearing a cowboy hat'' and ``the expression of the coat is rough,'' which clearly shows the difference in quality between Stable Diffusion 2.0 and Stable Diffusion 2.0.

Next, 'girl with long pink hair, instagram photo, kodak, portra, by wlop, ilya kuvshinov, krenz, cushart, pixiv, zbrush sculpt, octane render, houdini, vfx, cinematic atmosphere, 8 k, 4 k 6 0 fps Below is the image generated by Stable Diffusion 2.0 by entering the prompt ', unreal engine 5, ultra detailed, ultra realistic'. In Stable Diffusion 1.4, the problem of ``the human head being cut off'' frequently occurs, but in Stable Diffusion 2.0, the subject fits perfectly within the frame.
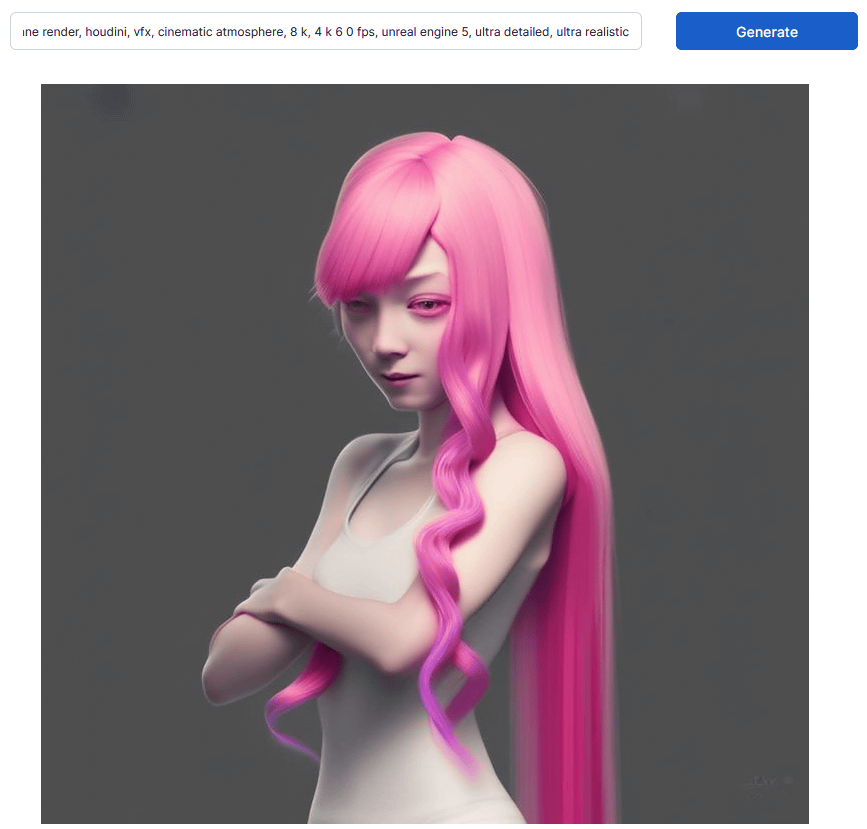
Below is an image generated with Stable Diffusion 1.4 by entering the same prompt. You can see that the outline is blurred compared to the image generated with Stable Diffusion 2.0.

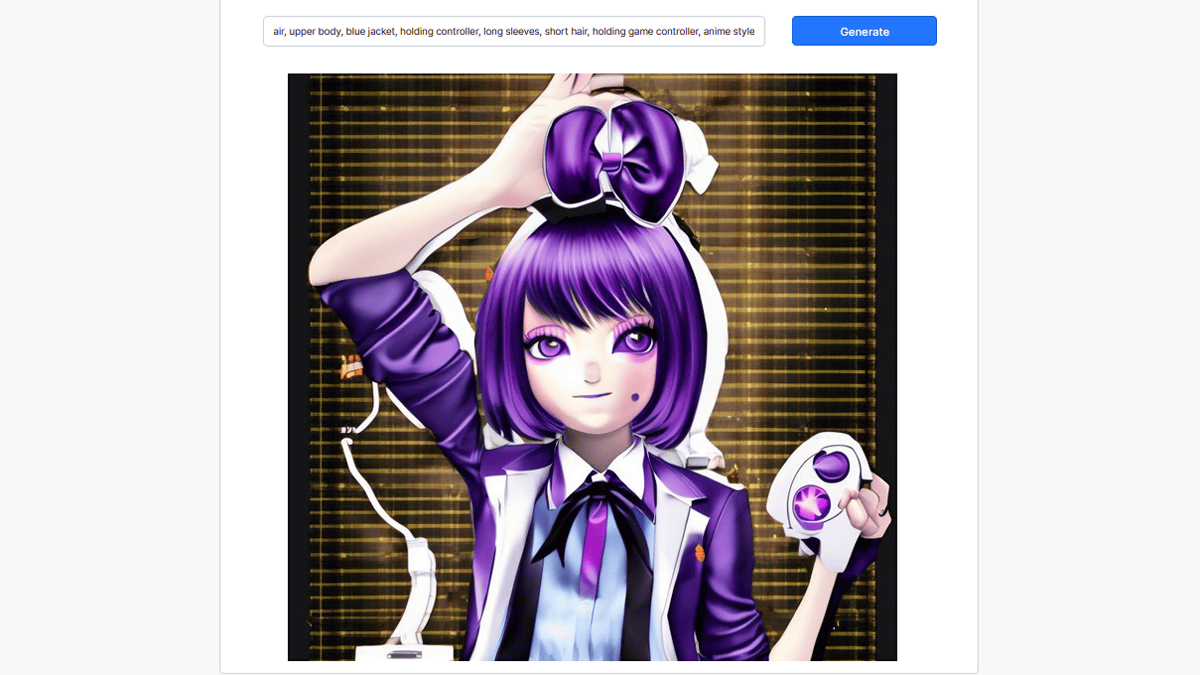
``1girl, solo, smile, bow, jacket, :d, controller, hairband, holding, bowtie, bangs, blazer, shirt, purple eyes, open mouth, school uniform, looking at viewer, game controller, purple hair, upper body, When you enter the prompt 'blue jacket, holding controller, long sleeves, short hair, holding game controller' and generate an image with Stable Diffusion 2.0, it looks like this. The shape of the fingers and the controller are unnatural.
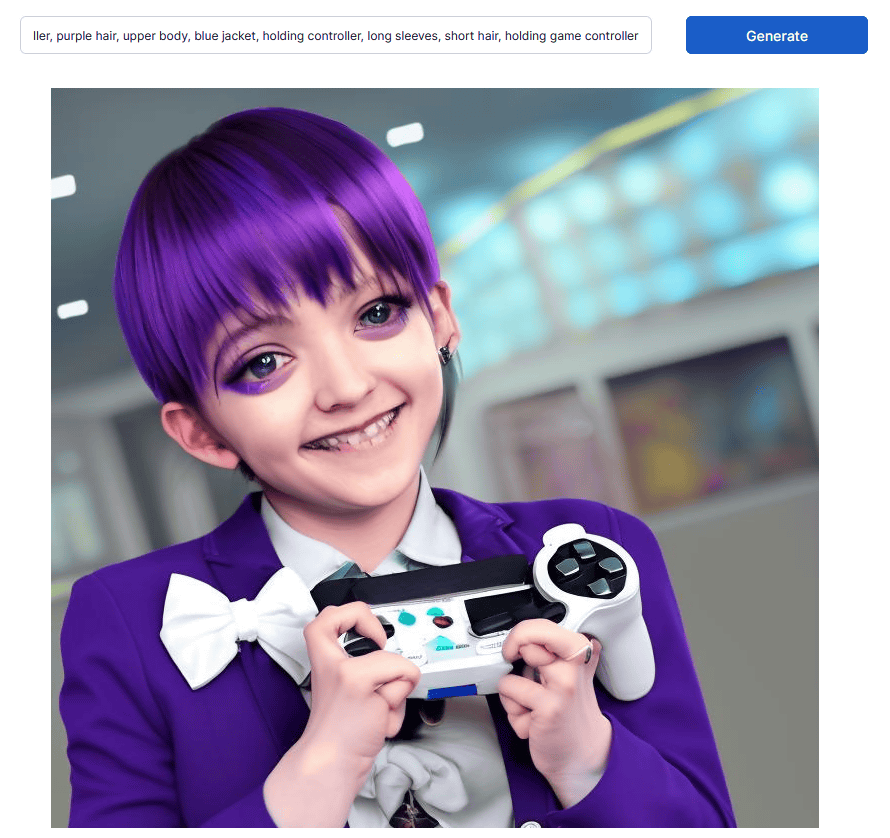
The generated result with Stable Diffusion 1.4 looks like this. Only the one on the bottom right was able to keep the face within the frame and follow the instructions of ``a girl with purple hair holding a controller.''

Next, in order to generate an illustration-like image, we added the phrase 'anime style' to the above prompt and generated it with Stable Diffusion 2.0. Below is the result. The result is a strange image that looks like a life-sized board is being illuminated, but most of the prompts are followed and the outline is clear.

The generated results with Stable Diffusion 1.4 are below. As expected, Stable Diffusion 1.4 is not good at fitting the face into the frame, and the outline tends to be blurred.

To generate high-quality images that match the prompt in Stable Diffusion 1.4, ``Generate images with multiple seed values, select the seed value that can generate high-quality images, and then generate several hundred images with that seed value.'' However, with Stable Diffusion 2.0, it was possible to quickly generate high-quality images according to the prompt instructions even with random seed values.
Related Posts:


in Free Member, Software, Review, Web Application, Posted by log1o_hf