Verification result that 'MacBook Air with M1 can calculate 900GFLOPS from the browser'

Apple's proprietary Arm architecture-based SoC ' M1 ' has been talked about as having extremely high performance, such as being reported to have surpassed the GeForce GTX 1050 Ti and Radeon RX 560 in the benchmark for measuring graphics performance. I will. Developer Bram Wasti reports on his website the results of measuring single-precision floating-point arithmetic performance with a MacBook Air equipped with such an M1.
jott --m1_webgpu_perf
https://jott.live/markdown/m1_webgpu_perf
Safari, which comes standard with the MacBook, experimentally supports a GPU API called WebGPU. So I coded a tuner to optimize matrix multiplication.
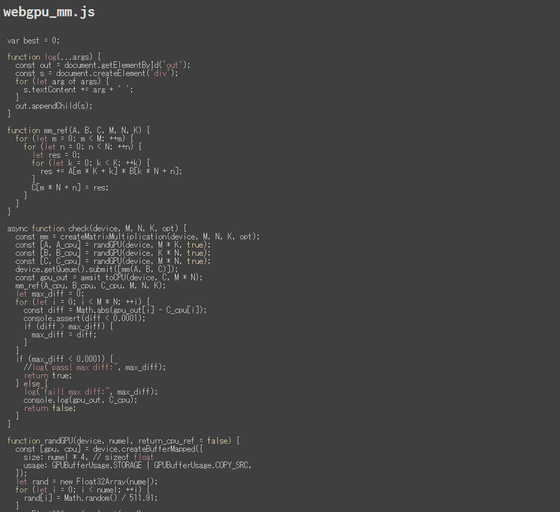
The tuner code is published below.
jott --webgpu_mm.js
https://jott.live/code/webgpu_mm.js
'The basic idea is to parallelize and vectorize memory access and use multiply-accumulate instructions to tune threading and dispatch parameters,' Wasti explains. As a result, the compute kernel will be as follows.
[code] [numthreads (2, 8, 1)]
compute void main (constant float4 [] A: register (u0),
constant float4 [] B: register (u1),
device float4 [] C: register (u2),
float3 threadID: SV_DispatchThreadID) {
uint m = uint (threadID.x);
uint n = uint (threadID.y);
float4 result_0_0 = float4 (0.0, 0.0, 0.0, 0.0);
float4 result_1_0 = float4 (0.0, 0.0, 0.0, 0.0);
float4 result_2_0 = float4 (0.0, 0.0, 0.0, 0.0);
float4 result_3_0 = float4 (0.0, 0.0, 0.0, 0.0);
for (uint k = 0; k <256; k ++) {
float4 a_0_0 = A [(m * 4 + 0) * 256 + (k * 1 + 0)];
float4 a_1_0 = A [(m * 4 + 1) * 256 + (k * 1 + 0)];
float4 a_2_0 = A [(m * 4 + 2) * 256 + (k * 1 + 0)];
float4 a_3_0 = A [(m * 4 + 3) * 256 + (k * 1 + 0)];
float4 b_0_0 = B [(k * 4 + 0) * 256 + (n * 1 + 0)];
float4 b_0_1 = B [(k * 4 + 1) * 256 + (n * 1 + 0)];
float4 b_0_2 = B [(k * 4 + 2) * 256 + (n * 1 + 0)];
float4 b_0_3 = B [(k * 4 + 3) * 256 + (n * 1 + 0)];
result_0_0 + = mul (a_0_0.x, b_0_0);
result_1_0 + = mul (a_1_0.x, b_0_0);
result_2_0 + = mul (a_2_0.x, b_0_0);
result_3_0 + = mul (a_3_0.x, b_0_0);
result_0_0 + = mul (a_0_0.y, b_0_1);
result_1_0 + = mul (a_1_0.y, b_0_1);
result_2_0 + = mul (a_2_0.y, b_0_1);
result_3_0 + = mul (a_3_0.y, b_0_1);
result_0_0 + = mul (a_0_0.z, b_0_2);
result_1_0 + = mul (a_1_0.z, b_0_2);
result_2_0 + = mul (a_2_0.z, b_0_2);
result_3_0 + = mul (a_3_0.z, b_0_2);
result_0_0 + = mul (a_0_0.w, b_0_3);
result_1_0 + = mul (a_1_0.w, b_0_3);
result_2_0 + = mul (a_2_0.w, b_0_3);
result_3_0 + = mul (a_3_0.w, b_0_3);
}
C [(m * 4 + 0) * 256 + (n * 1 + 0)] = result_0_0;
C [(m * 4 + 1) * 256 + (n * 1 + 0)] = result_1_0;
C [(m * 4 + 2) * 256 + (n * 1 + 0)] = result_2_0;
C [(m * 4 + 3) * 256 + (n * 1 + 0)] = result_3_0;
}
dispatch params: 128,32,1 [/ code]
Wasti reports that he tuned his MacBook Air with an M1 chip for a few seconds and actually calculated it to achieve 900G FLOPS. Mr. Wasti's MacBook Pro with Intel Core i9 (2019 model, 16 inches) achieved only 100 GFLOPS with the same processing.
Also, when measuring the performance of the edge AI 'MobileNet v3 Large (x1.0)' with a MacBook Air equipped with an M1 chip, it is a maximum of 219 MFLOPS, which is a level that can execute 4500 inferences per second. In addition, Google's natural language processing model BERT (12-layer configuration) is 11.2 GFLOPS, which is equivalent to the performance of being able to execute 90 inferences per second.
Wasti said, 'We can do a lot more with the tweaks, but we're very happy with the results. The fact that we hit almost 1 TFLOPS in the browser is very encouraging and makes technology like the M1 available. It's especially exciting. '
Related Posts:








in Hardware, Posted by log1i_yk