Cloudflare impacts large-scale failures that bring down 50% of the network, large sites such as Discord and Feedly

In the afternoon of July 17th Pacific Time, a misconfiguration of the router caused a major outage that caused 50% of Cloudflare's network to go down. Due to this failure, large sites such as Discord and Feedly are reportedly temporarily unavailable.
Cloudflare outage on July 17, 2020
Cloudflare DNS outage impacts Feedly, Tumblr, Discord, and more-DCD
https://www.datacenterdynamics.com/en/news/cloudflare-dns-outage-impacts-feedly-tumblr-discord-and-more/
Cloudflare is building a single backbone with dedicated lines to connect between its data centers. It is explained that by laying a dedicated line, data centers can be connected without passing through the Internet, so high-speed and highly reliable communication can be realized.
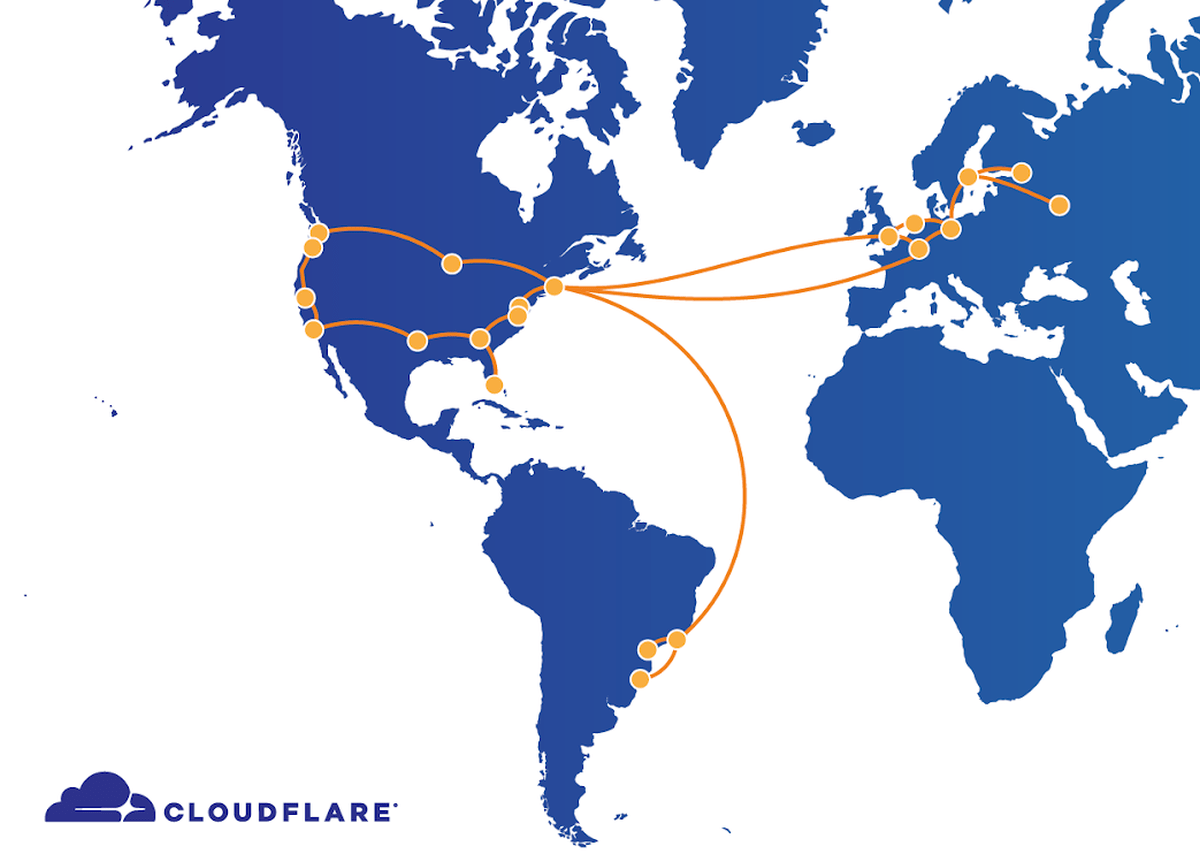
It is the communication in this backbone that has failed this time. The first anomaly was detected at 20:25 on July 17, Pacific time, when a problem occurred on the line connecting the Newark and Chicago data centers, causing a backbone link between the Atlanta and Washington, DC data centers. It was said that congestion had occurred. To solve this problem, a router configuration change was made at 21:12 in Atlanta's data center, but the change caused the network to go down for 27 minutes. The service was restored by removing the Atlanta router from the backbone at 21:39, but congestion occurred at the data center collecting logs and metrics from 21:47 to 22:10. The network was completely restored at 22:10.
Some sites, such as Discord and Feedly, will be unavailable for 27 minutes after the network goes down. Discord's Twitter account posted, 'There is a problem with the Discord connection due to a failure in the upstream of the Internet.'
Users are currently having trouble disconnecting to Discord due to an upstream internet issue.We've got all engineers on deck investigating the issue
pic.twitter.com/GvtxKanokl — Discord (@discord) July 17, 2020
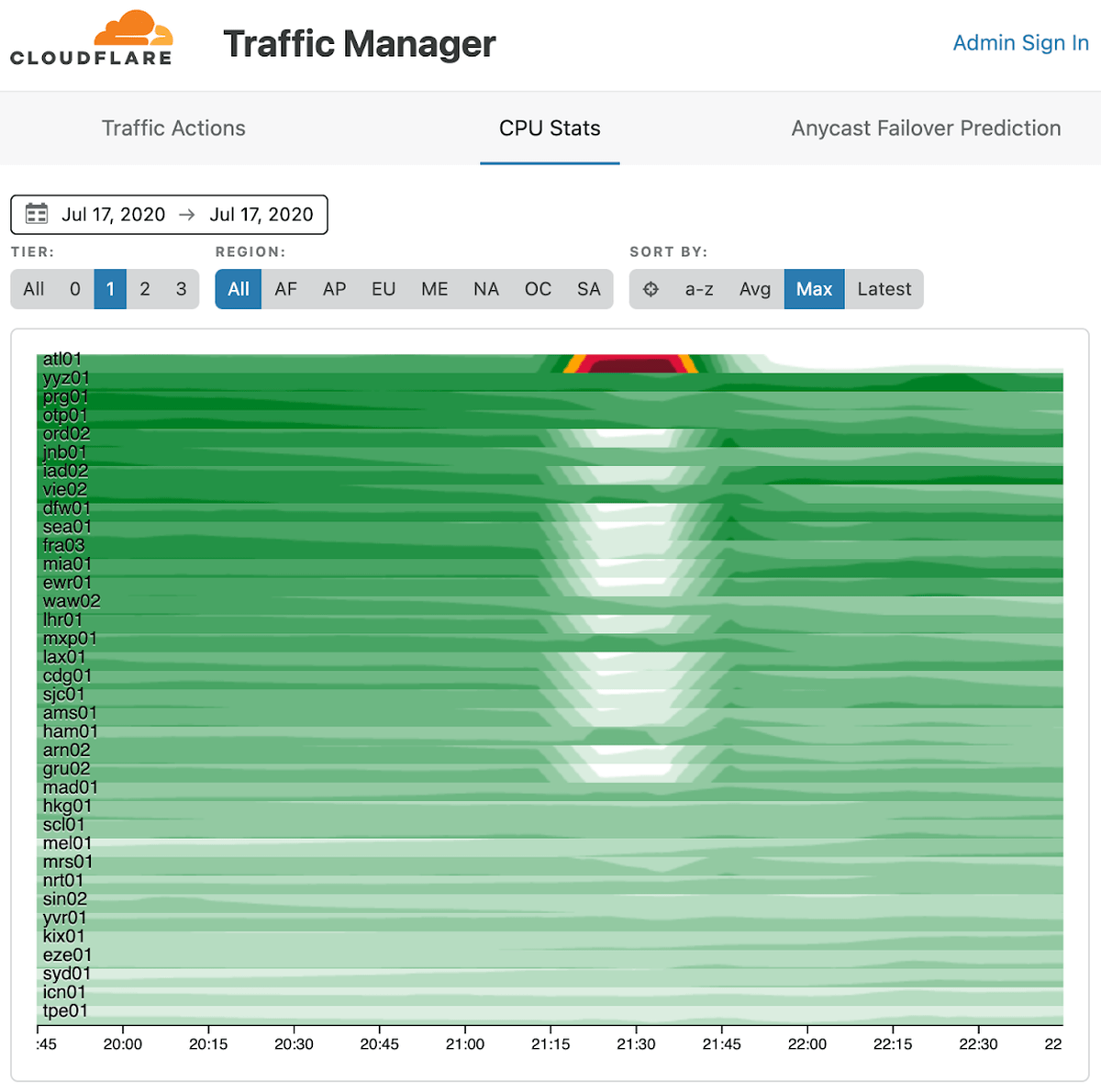
A graphic of router CPU utilization, which the monitoring tool used internally by Cloudflare showed at the time of failure, is also available. The utilization of 'atl01' at the top, which points to the router installed in the Atlanta data center, is displayed in red and yellow, which indicates that it was extremely loaded. On the other hand, the CPU utilization of routers installed in some other data centers is displayed in white, which means that the CPU is not loaded at all, and the traffic that should flow to other routers in the Atlanta router is displayed. You can see that was concentrated.
This failure was caused by the Atlanta router notifying the router in the backbone with incorrect route information via

The settings made to the prefix list '6-SITE-LOCAL' are as follows. For routes that match the prefix list, the local-preference value, which is the router priority item, was set to 200, some communities were added, and routes were accepted.

By disabling only the prefix list while the above settings were still in effect, Atlanta routers sent all routers their local-preference value of 200. The correct setting was not to invalidate the prefix list, but to invalidate each route setting that was set for the prefix list. The other router has a local-preference value of 100, and the route with a high local-preference value is prioritized, causing a problem in which backbone traffic is concentrated on the Atlanta router.
Following this failure, Cloudflare will introduce a maximum prefix length limit for backbone BGP sessions and change the default value of local-preference. Cloudflare commented, 'We apologize for any inconvenience caused to all users who could not access the internet during the outage.'
Related Posts:







in Web Service, Posted by darkhorse_log