Cloudflare describes a major network failure that occurred on June 21, 2022

Around 15:30 on June 21, 2022, Cloudflare's 19 major data centers failed, making it impossible to access multiple sites such as Discord and Pixiv. Cloudflare describes this massive network failure on its official blog.
Cloudflare outage on June 21, 2022

About Cloudflare failure that occurred on June 21, 2022
https://blog.cloudflare.com/ja-jp/cloudflare-outage-on-june-21-2022-ja-jp/
The failure occurred on June 21, 2022 in Amsterdam, Atlanta, Ashburn, Chicago, Frankfurt, London, Los Angeles, Madrid, Manchester, Miami, Milan, Mumbai, Newark, Osaka, Sao Paulo, San Jose, Singapore, and Sydney.・ There are 19 data centers in Tokyo.
Cloudflare has spent 18 months implementing a new architecture designed as a Clos network in 19 data centers. This architecture was an additional layer of routing called ' Multi-Colo PoP (MCP) ' for configuring the connection mesh. This connection mesh will allow you to easily disable or enable parts of your data center's internal network for maintenance and addressing issues, allowing you to perform maintenance without disrupting traffic. It was done.
To make this possible, Cloudflare used a protocol called BGP . In this BGP, you need to define a policy that determines which prefixes to advertise to or accept from the connecting network.
And when Cloudflare deployed this prefix advertising policy change, they accidentally deleted an important subset of the prefix because they misordered the configuration statements they added. Moreover, it took a long time to fix it because the subset of prefixes required for connecting each network was deleted.
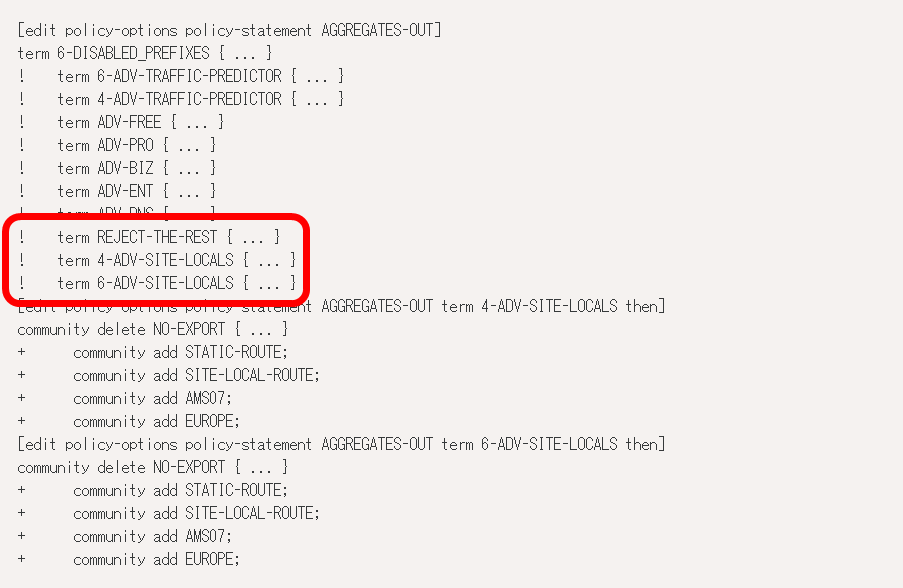
The failure occurred at 15:27 on June 22, 2022 Japan time, the failure was declared inside Cloudflare at 15:35, the cause was found at 15:58, and all the data was at 16:42. The restoration of the center and network was completed, and it was judged that the failure was resolved at 17:00.
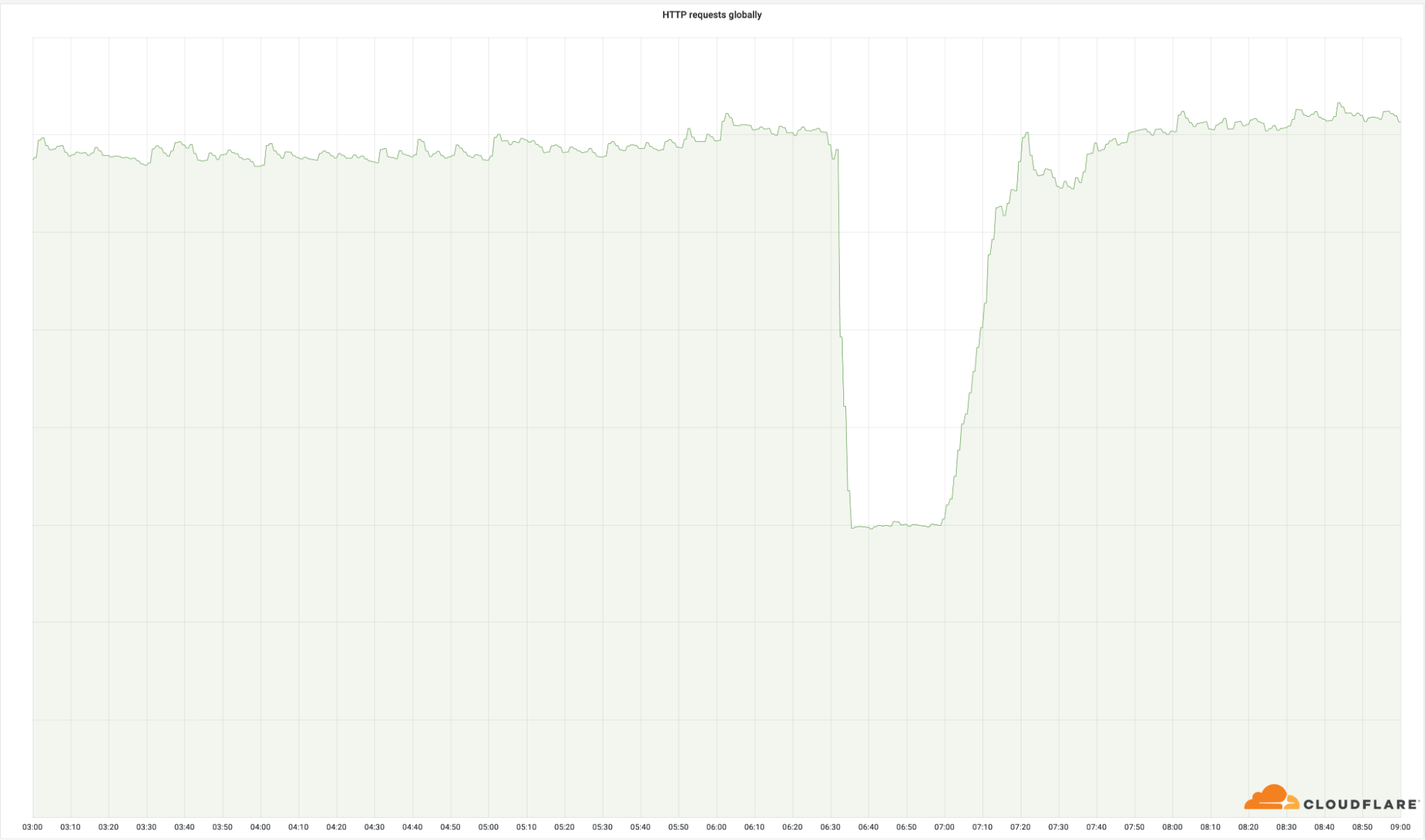
Below is a graph of the number of HTTP requests for the entire world of Cloudflare. It is said that 4% of the entire internal network was affected by the failure, but the number of HTTP requests dropped to about three-sevenths when the failure occurred.
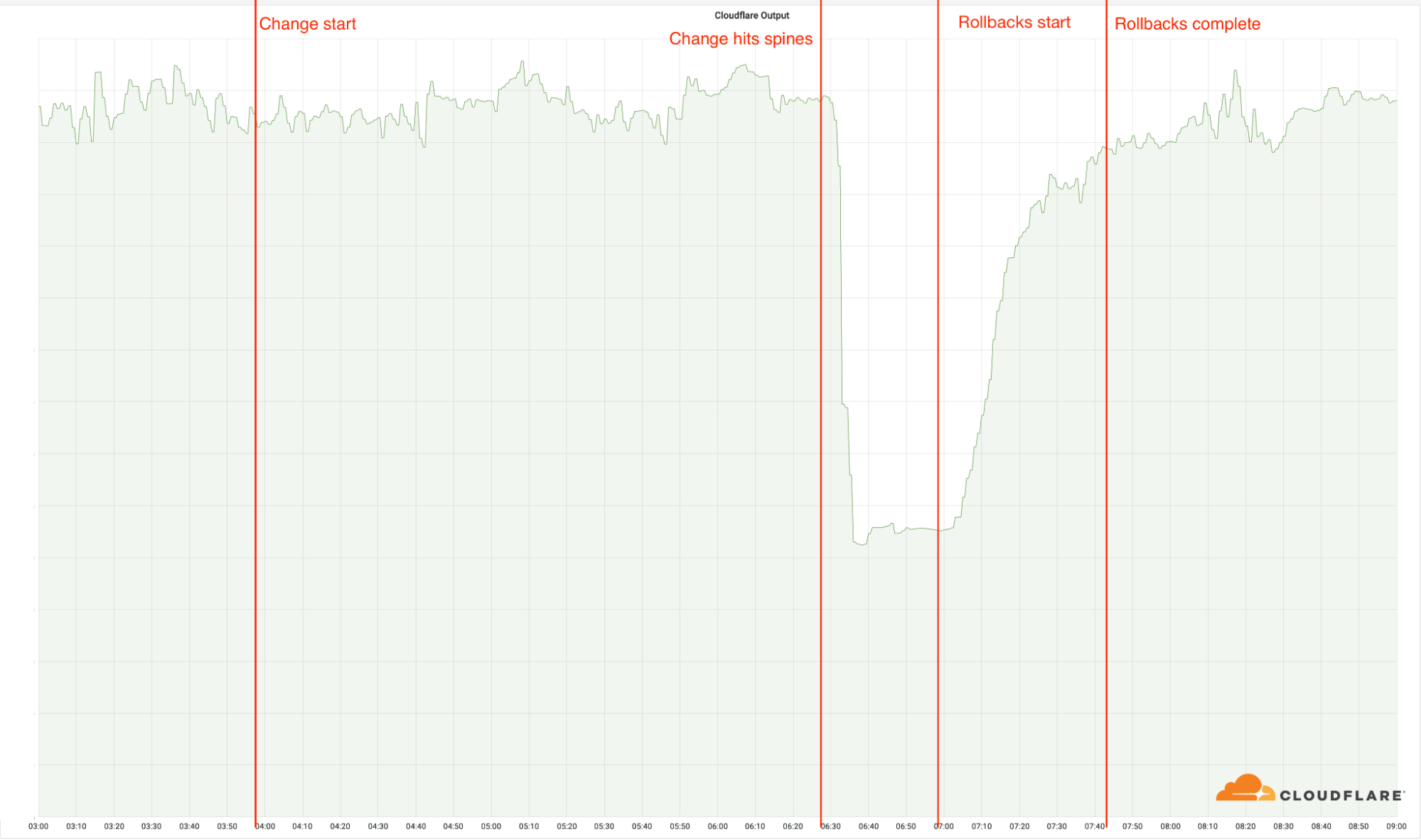
Cloudflare's network output bandwidth graph also shows that it's slumping at the timing of the failure.
Cloudflare said, 'We have invested heavily in MCP design to improve service availability, but this very traumatic incident clearly failed to meet our customers' expectations. We sincerely apologize for the inconvenience caused to all users who could not access the Internet, including our customers. We have already started to fix it, and we will do this in the future. We will continue to strive to prevent this from happening again, 'he said, reviewing the work procedure and carefully implementing MCP.
Related Posts:







in Web Service, Posted by log1i_yk