MIT researchers completely delete large datasets from the net as'implanting discrimination into AI'
In recent years, the possibility that artificial intelligence (AI) discriminates and prejudices has been regarded as dangerous, and there are many chief researchers in the artificial intelligence department of Facebook saying that 'image generation using artificial intelligence algorithms is discriminating'. It has also been accused of being attacked by and has caused the
80 Million Tiny Images
https://groups.csail.mit.edu/vision/TinyImages/
MIT apologizes, permanently pulls offline huge dataset that taught AI systems to use racist, misogynistic slurs • The Register
https://www.theregister.com/2020/07/01/mit_dataset_removed/
MIT removes huge dataset that teaches AI systems to use racist, misogynistic slurs
https://thenextweb.com/neural/2020/07/01/mit-removes-huge-dataset-that-teaches-ai-systems-to-use-racist-misogynistic-slurs/
An AI trained by machine learning loads a 'human-made data set' during the training process. Although AI itself does not create discrimination or prejudice by itself, because of the mechanism of learning based on the dataset, AI may inherit the discrimination and prejudice contained in the dataset as it is.
For example, machine-trained AI tends to associate 'flowers' and 'music' with 'fun things,' but not words such as 'insects' and 'weapons' to 'fun things.' I know. Similarly, while the word “female” is associated with “artistic”, it tends to be difficult to associate with “math”.
Such problems have been pointed out for some time, and it is important to create datasets that do not reflect human discrimination.
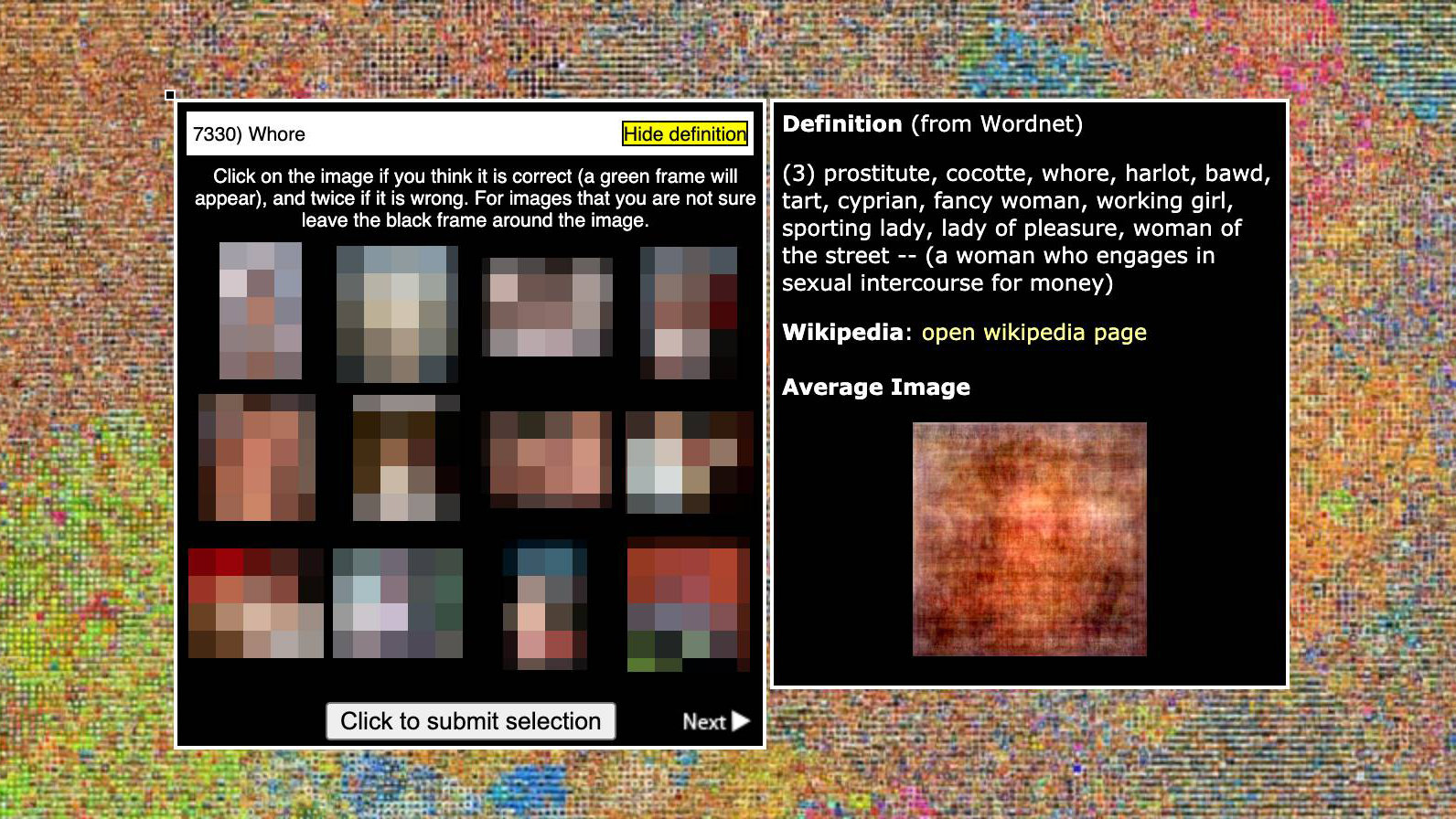
The Massachusetts Institute of Technology (MIT) created a library of images called Tiny Images in 2008 with 80 billion images. This image library links 'photos' with 'subject name labels' and is used for computer training. However, Vinay Prabhu, chief scientist at UnifyID, who develops next-generation authentication services, and Abeba Birhane, a PhD student at University College Dublin, surveyed Tiny Images and found thousands of images in Asia. It was found to have been labeled with discriminatory terms of descent and blacks, and inappropriate labels were also used to describe women.
LARGE IMAGE DATASETS: A PYRRHIC WIN FOR COMPUTER VISION?
(PDF file) https://arxiv.org/pdf/2006.16923.pdf
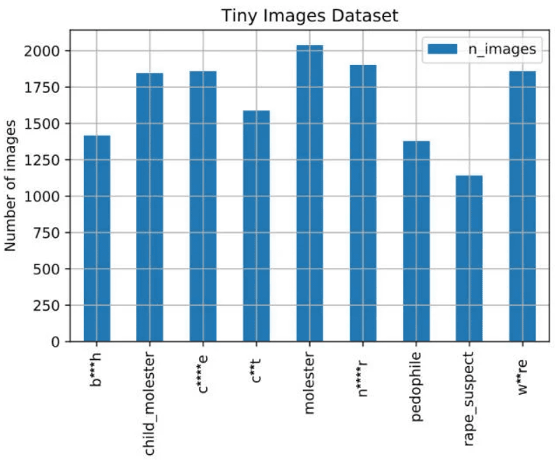
In the figure below, the words 'b***h' (prostitute), 'child_molester' ( sodomy ), 'c**t' (female organ), and 'rape_suspect' (rape suspect) were labeled. It is shown that there are 1000 to 2000 images each.
The data set includes photographs of monkeys labeled with black discrimination terms, or women in swimsuits labeled prostitutes, anatomical sites labeled with poor language, etc. It was Such associations could potentially use these terms when analyzing photos and videos for apps, websites, products, etc. that rely on neural networks trained with Tiny Images. Was pointed out.
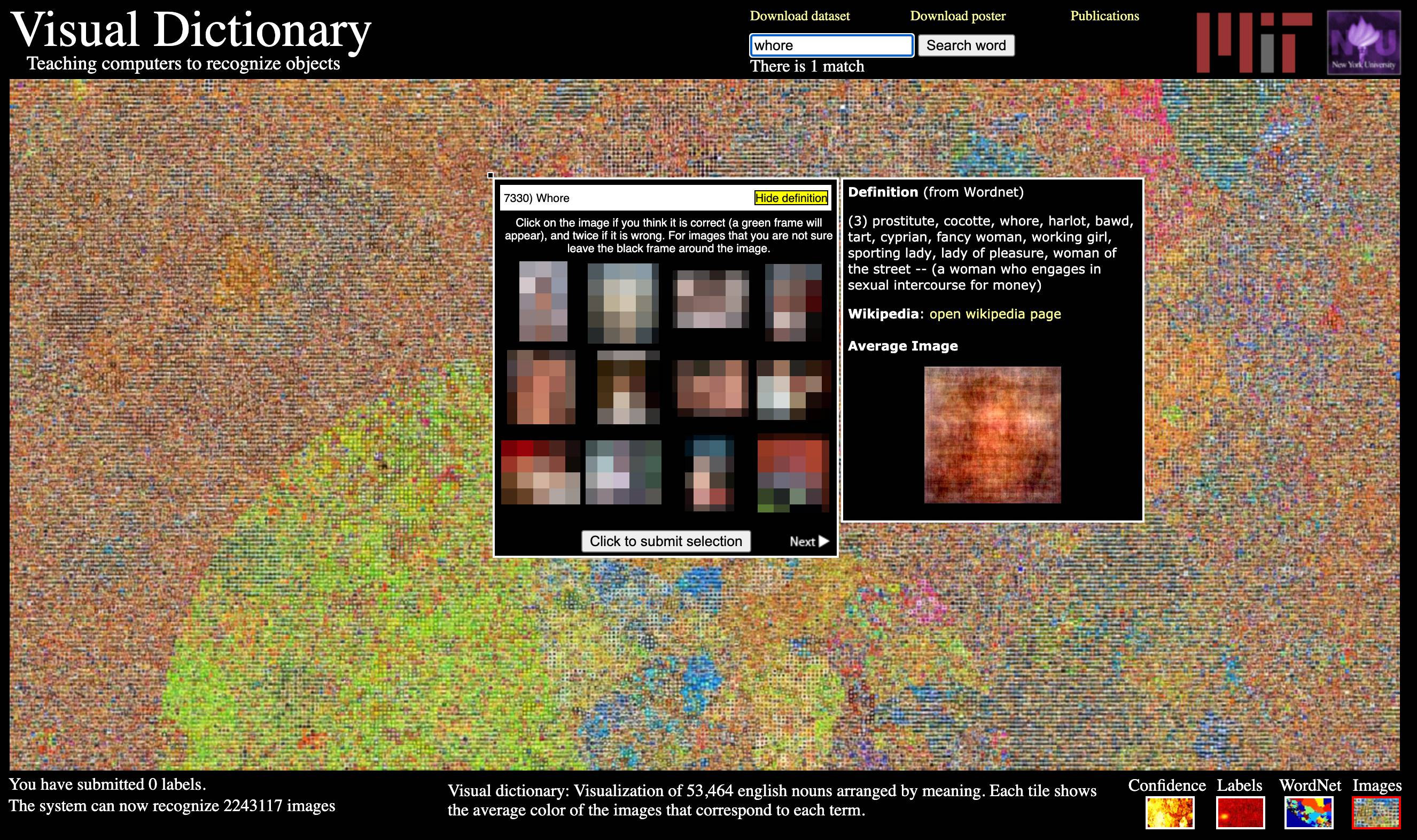
In response to this issue, as of June 29, 2020, MIT completely removed Tiny Images online. According to MIT's Antonio Torralba et al., the Tiny Images dataset contained inappropriate terms because it relies on an English concept dictionary, a collection of data automatically created by WordNet . thing. Researchers decided to remove the dataset itself from the Internet rather than make corrections, as the dataset is very large and the image is so small at 32 x 32 pixels that manual filtering is difficult. did.
In June 2020, IBM announced that it will withdraw from the face recognition market because it is 'concerned that technology will promote discrimination and inequality.' Facial recognition software is used in criminal investigations in many countries, but it also has problems with data sets, which makes blacks particularly inaccurate and causes false arrests.
IBM announced withdrawal from the face recognition market, ``technology is concerned about promoting discrimination and inequality''-GIGAZINE

Related Posts:






