Because I hear who is talking by machine learning that I do not react even if I talk to another person's iPhone "Hey Siri"

ByToshiyuki IMAI
"Hey Siri" is a function that starts Siri by talking to "iPhone" and "Hey Siri" and can start voice input with hands-free. Everyone is using the same phrase, but Siri does not start up with others' voice in many cases. The reason was written on Apple 's official blog that "technology to recognize the owner's voice by machine learning is used".
Personalized Hey Siri - Apple
https://machinelearning.apple.com/2018/04/16/personalized-hey-siri.html
"Siri" was announced in 2011 with iOS 5, and it is the voice recognition function installed in the iPhone after that. In 2014, calling "Hey Siri" towards the iPhone, Siri started up, and a function to accept subsequent voice input was also added. Up to iPhone 6 is a Hey Siri function that could only be used while charging, but after iPhone 6s you can use the Hey Siri function at any time by using a low power processor.
It is good to be able to start voice input with a natural call called Hey Siri like "Hey Siri, what is the weather today?", But at the beginning of development it started "Unintended Siri startup" occurred It was said that it was closed. This unintended activation occurs in three situations: "users say similar phrases", "others say Hey Siri" "others say similar phrases." Of these, speaker recognition technology is used to prevent unintentional activation by others.
Speaker recognition is a technology that identifies "who talks" as its name suggests. First of all, I want someone who wants to recognize to speak several phrases, and based on that we create a statistical model of the user's voice. And when actually recognizing, it compares the input voice with the model and judges whether it belongs to the model or not.
Initial settings when using Hey Siri on iPhone are instructed to say some phrases in advance, but that sound is used for model creation. Also, besides registering the model for the first time, updating the model using sounds actually used is also performed. It is stated in the blog that it is unnecessary to set the initial setting when using Hey Siri in the future.
· Hey Siri system overview
The figure below shows the overview of the Hey Siri system. The upper half is a high level figure, the input voice is first converted to a fixed length speaker vector by the green feature extractor, and then enters the stage of model comparison. In the feature extractor, two stages of processing are performed as shown in the lower half of the figure. In the first step, convert the input speech to a vector of fixed length and convert it so as to emphasize speaker-specific characteristics in the second step. Then, the inner product with the model vector registered beforehand is calculated, and Siri starts when the result exceeds the threshold value.
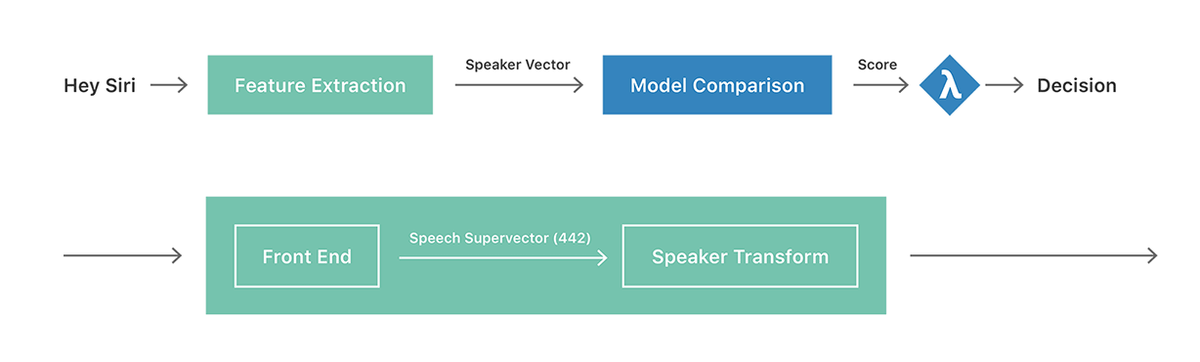
The most important part of this speaker recognition is the "speaker conversion" part in the second stage of the feature extractor, and the goal of this conversion is to minimize the variation of "another person's timing voice" Another person's voice "to clarify the difference. Apple's earlier approach is to use 13-dimensionalMel frequency cepstrum coefficients (MFCCs)And 28 variablesHidden Markov Model (HMM)To input a voice vector to "Hey Siri detector". The vector of 13 × 28 = 364 generated in this way is a super vector, because it is a concatenated vector, so this super vector is the output speech vector.
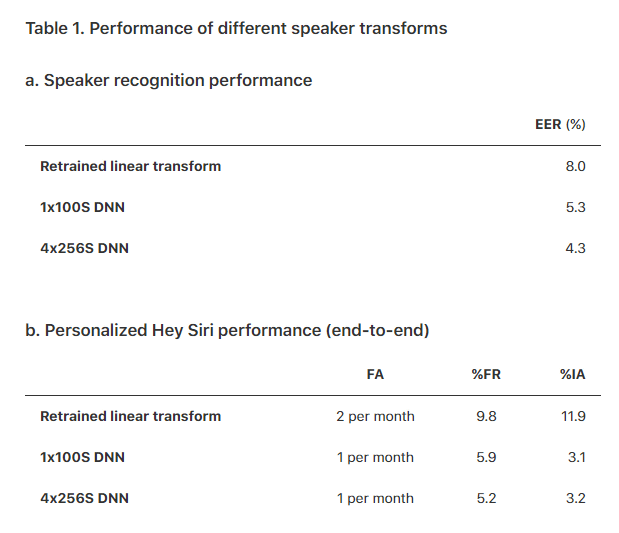
After that, using the linear discriminant analysis, it was said that the misperception rate was drastically decreased by training "transcoder conversion" to be successful. Furthermore, using a nonlinear identification technology in the form of a deep neural network seems to be able to perform better conversion. The number of Mel frequency cepstrum coefficients (MFCCs) used was changed from 13 to 26, and it was ineffectiveHMMWe delete the first eleven variables, reduce them to 17 variables, make the output into a 26 × 17 = 442 dimensional speech vector and pass it through the neural network. The structure of the neural network is as follows. First, the input vector is passed through the hidden layer (1 × 100 S) of 100 neurons that is activated by the sigmoid function, the output is passed through a layer of 100 neurons that activates by a linear function, and finally Softmax It converts output to probability representation through layer. After training this neural network, when actually performing "speaker conversion", remove the last Softmax layer and output it as a speaker vector.

Further optimization was repeated, and finally the neural network consisting of the sigmoid layer (4 × 256 S) consisting of 4 256 neurons and the linear layer of one hundred neurons left the best results. As a result, "False Reject (FR)" which the person himself wrongly identifies as "Hey Siri", and "Imposter Accepts (IA) who reacts to another person's" Hey Siri " Equal Error Rate (EER), which is a point where ratios match, has been reduced to 4.3%.
Although the speaker recognition function has been greatly improved by the neural network, it has not been able to demonstrate sufficient performance in the echoing room or the noisy environment. Siri's development team is focusing on grasping and quantifying degradation in harsh environments. By training with test data already noise or echoedCertain achievementsIt is said that it is cited.
Also, the purpose of the Hey Siri function is to "start Siri". Up to this point, I have explained about recognizing the speaker of the trigger phrase Hey Siri, but if we can identify the speaker even with words other than "Hey Siri", "~~~, what is the weather today?" You can talk to Siri even if you do not have a speech phrase called Hey Siri.Next article of development teamThen,Long / Short term storage unitWe are conducting research to summarize speaker information from variable length speech both in the case of specific words and in case of nonspecific words. The results of the Siri development team show that performance can be greatly improved by using speaker recognition of "Hey Siri".
Related Posts:







in Software, Smartphone, Posted by log1d_ts