Firefox add-on "Copyfish" that allows you to copy text strings from OCR to images, movies, protected PDFs etc.
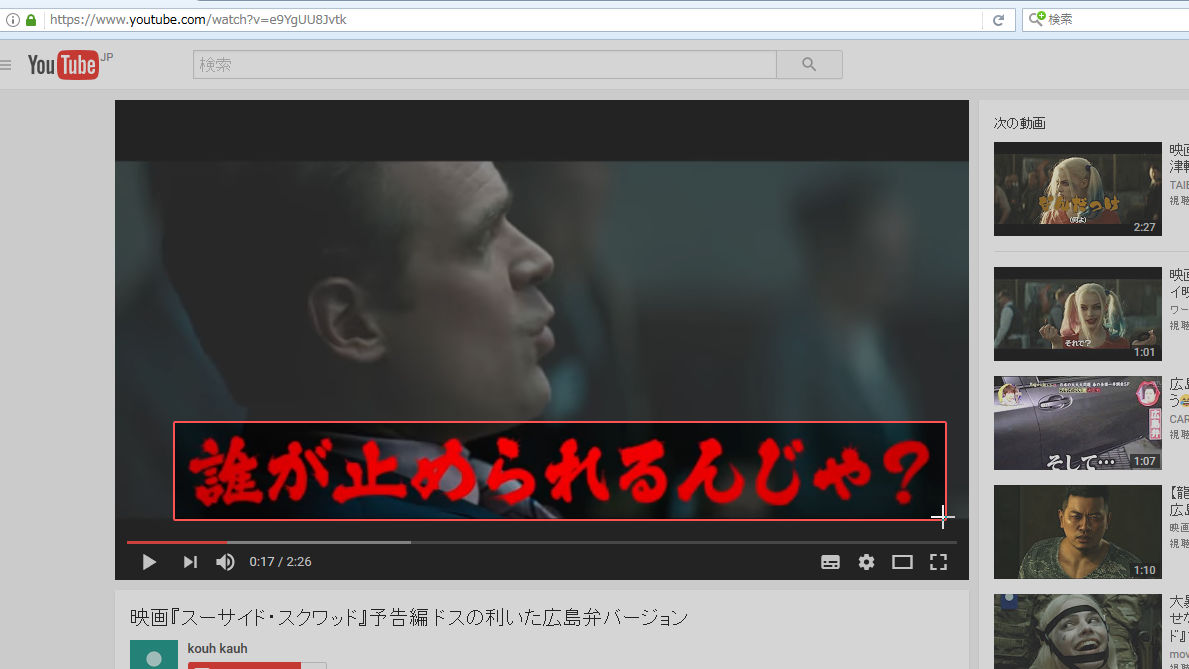
Browser Firefox addon "Copyfish"OCR(Optical Character Recognition) function can be added to convert movie subtitles, site logos, character images, etc. into character code format. Since it is possible to translate at the same time as text conversion, I tried using it at once.
Copyfish :: Add-ons for Firefox
https://addons.mozilla.org/en-us/firefox/addon/copyfish-ocr-software/
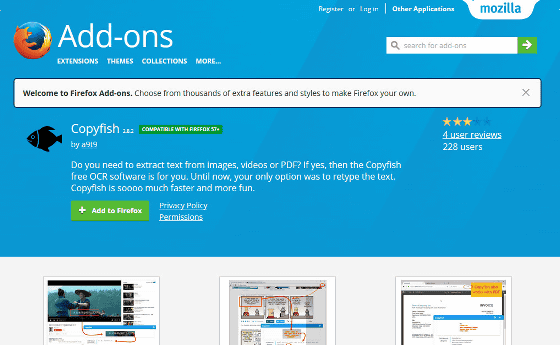
◆ Add-on installation
Go to the above URL in Firefox and click "Add to Firefox".

Click "Install".

If you open the page labeled "Welcome!", Installation of the Copyfish add-on is complete.

◆ I tried using
· Movie subtitles
First of all, I will copy subtitles in the movie. Click the "Copyfish" button added to the add-on bar next to the search box.

After specifying the subtitle part you want to copy with the mouse cursor, click once.

As copy starts, wait for a while ......

I was able to convert subtitles in the movie to text.

If you copy another subtitle in the same way ......

I could not recognize the word "very" well. In such a case, click "Redo OCR", redo the character conversion, click "Recapture" and specify the letters OK.

Changing the specified range, I was successfully recognized.

Next I will try Japanese subtitles.

By default, characters that can be recognized are specified as "English (English)", so characters can not be recognized well. So, click the "gear" icon.
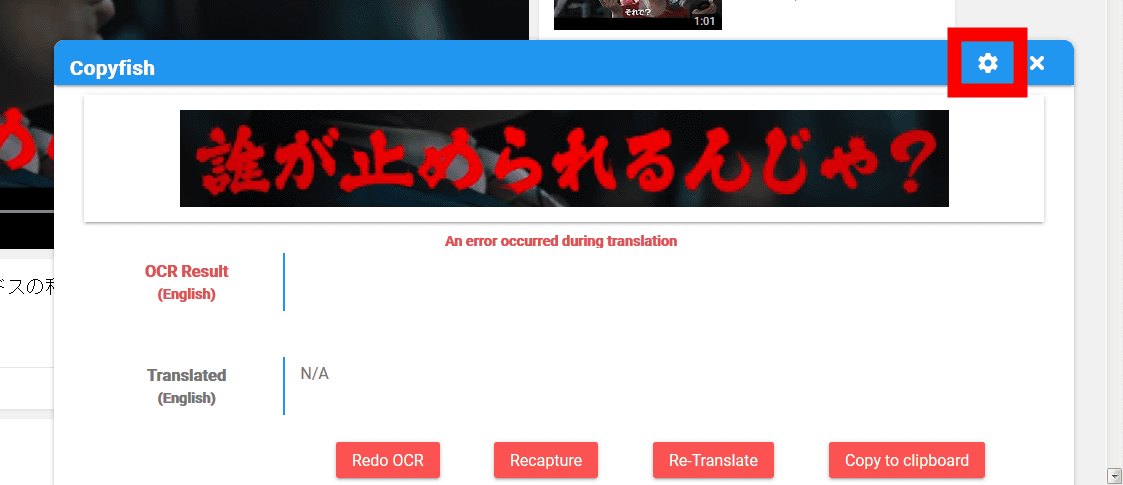
The "Copyfish Options" page opens, so click "English" in "Input Language (OCR Language)".

If you specify "Japanese (Japanese)" OK.

Next time I was able to recognize characters as Japanese, but the word "who" was misrecognized as "Luo". In the case of a characteristic font, it seems that there are times when it is not possible to recognize characters well.

Try different font characters ......

I recognized it correctly.

· Character image
Copyfish can convert not only subtitles but also characters of image format to text. Designating the "University of Tokyo" logo on the University of Tokyo website ......

Can be text without problems, translation is perfect.

Try with the logo of GIGAZINE ......

I could not recognize it well. It seems that it is difficult to recognize it properly in the case of a bag character or the like.

· Protected PDF
It is also possible to convert characters of "protected PDF" that can not be recognized / extracted as text as text. Open PDF file instruction Specify "Firefox" as the program and display the PDF file with the Firefox browser.

After that, just click on the Copyfish button on the add-on bar and designate the part you want to convert to text ......

I could use OCR function without any problem.

Related Posts: