Chrome extension "Project Naptha" to select a character string on a photo or image and make it copyable
The Google extension that enables you to select & copy & paste strings that can not normally be copied and pasted, such as photos, JPEG images, diagrams, sentences on screenshots,Project Naptha"is.
Project Naptha
http://projectnaptha.com/

What can actually do? You can tell by looking at the following GIF animation.
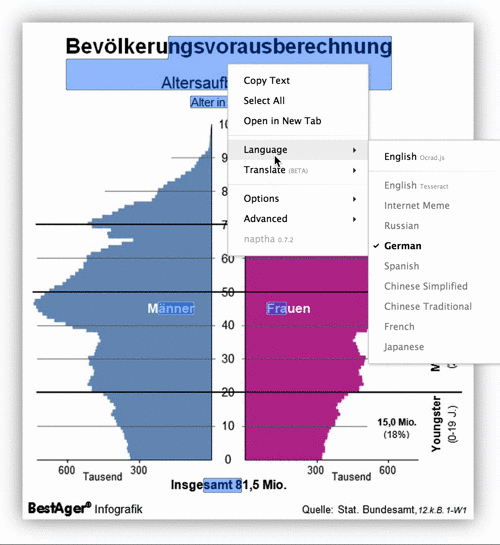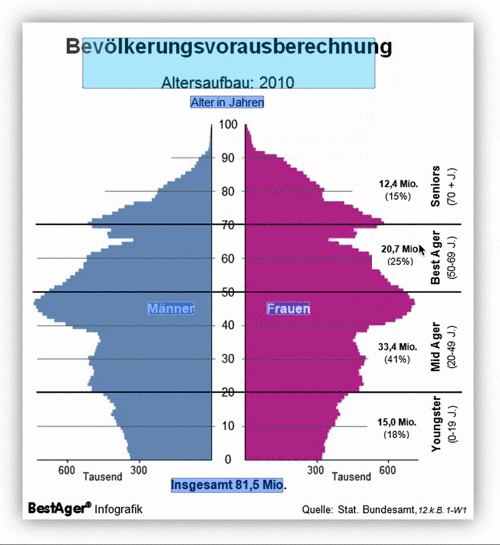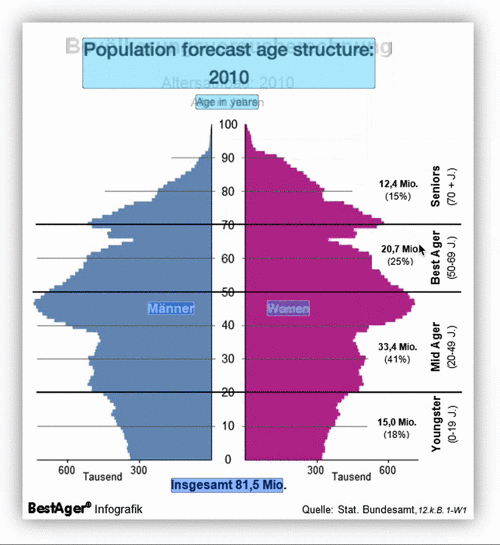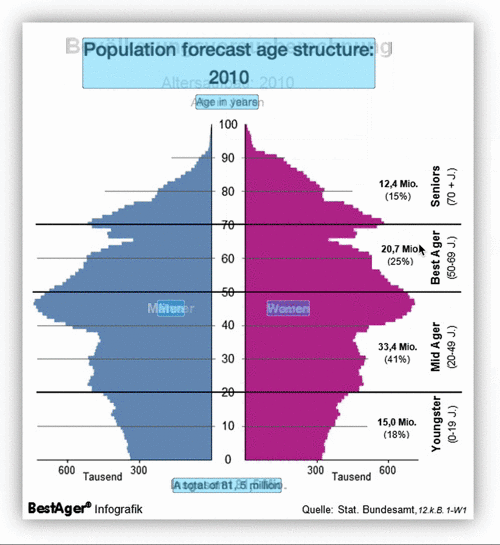
To use the extension function, first click "Add to Chrome".

The screen "Add to Chrome" appears, so click "Add".
When the extension is added, "Project Naptha was added to Chrome" appears next to the address bar.
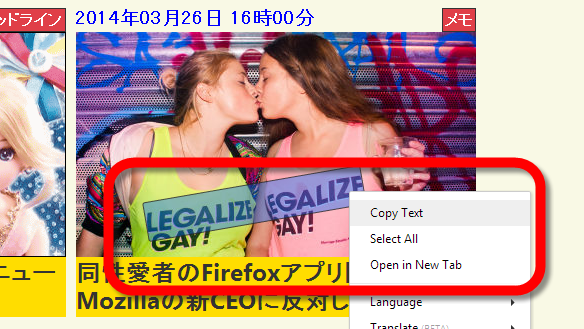
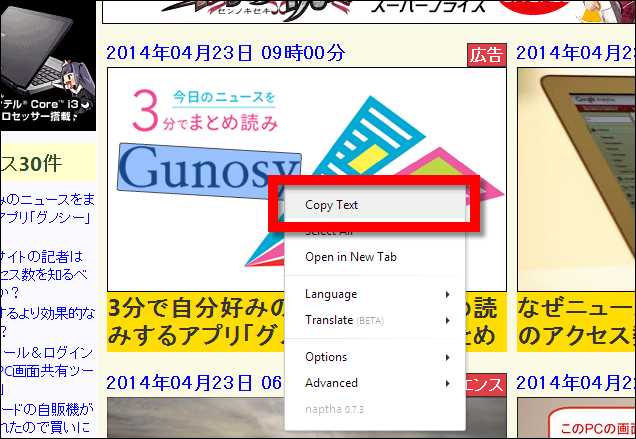
So, I actually open GIGAZINE and try it. Select the character "Gunosy" in the image and copy it with right click. At this time, there was no problem even if the characters were slightly enormous.
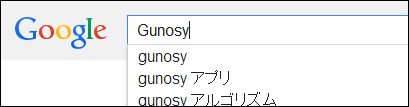
When I opened Google and pasted it in the search field, I was able to paste the characters in the image properly.
Project Naptha is an algorithm that recognizes text from individual characters invented by MicrosoftStroke Width Transform"It was developed to read the movement of the cursor and instantly text. Open source of Ocrad for character recognitionOCRI am using the Latin alphabet and someDiacritical markOnly weakness is a weak point. It also recognizes it based on the shape of certain letters, so even if the text to be read matches the notation "he1 | o" it may be recognized as "hello".
For example, copy the word "Tex compile" ... ...
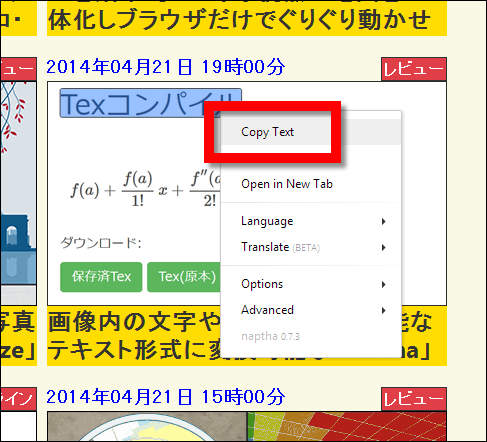
A long character string appeared when pasting.

The contents written are as follows.
TexII ' This text was recognized by the built-in Ocrad engine. A better may be attained by changing the OCR Engine (under the Language menu) to Tesseract. This message can be removed in the future by unchecking "OCR Disclaimer" (under the Options menu). More info: http://projectnaptha.com/ocrad
Looking at the first character string is "Tex II", it seems that such a notation has been made because "compile" of "Tex compilation" could not be read correctly.
If you use a unique font in the alphabet ......
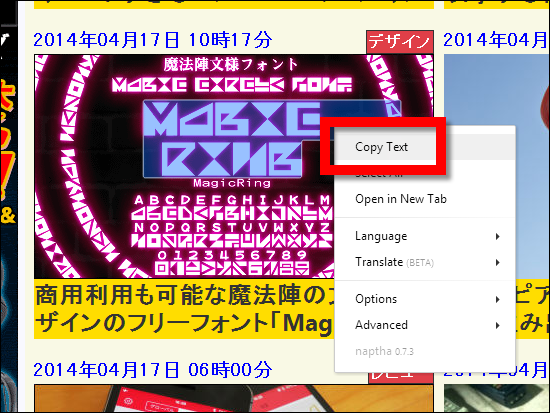
Likewise, it was not well recognized.

Originally the image is fundamentallyrasterBecause it is made of elements, it lacks the information necessary to identify characters.

Therefore, image sensing, information recognition, etc. are performedComputer visionAlthough it is used, this is a type of technology that "looks" at the existence of characters and objects, the shape of objects, and so on.

On the other hand, OCR is originally based on technology that has been used for over 30 years to recognize books and documents in the field of libraries and justice, and in recent years various algorithms have been added, recognizing road signs from photos It is also used to recognize characters of business cards.

Instead of Ocrad, using OCR "Tesseract" provided by Google, for example when someone uses Tesseract for public images, the recognition result is saved on Google side, so someone else is the same Even if you are trying to read characters from the image, recognition can be done by caching, and accuracy will be higher. For this reason, we plan to move from Ocrad to Tesseract in the future.
Currently Project Naptha can only be used with Google Chrome, but it does not support other browsers, but Firefox version will be released soon. In addition, if you have something like "Please let this browser compatible", it is possible to contact the developer.

Related Posts: