'OCR PDFs and images directly in your browser' allows you to extract text from PDF, JPEG, PNG, and GIF files using OCR for free and on your browser.
Engineer Simon Wilson has released `` OCR PDFs and images directly in your browser,' ' which allows you to extract text from image files such as PNG, JPEG, GIF, and PDF files using
OCR PDFs and images directly in your browser
https://tools.simonwillison.net/ocr
Running OCR against PDFs and images directly in your browser
https://simonwillison.net/2024/Mar/30/ocr-pdfs-images/
When you access OCR PDFs and images directly in your browser , it looks like this.
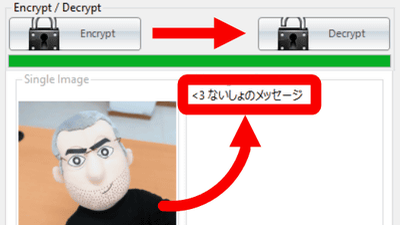
First, in order to try loading an image file, let's load an image (PNG format) that is a screenshot of the beginning of Lewis Carroll's ``

Drag and drop the image you want to OCR into the area labeled 'Drag and drop a PDF, JPG, PNG, or GIF file here or click to select a file' in OCR PDFs and images directly in your browser.
Then, the image file was loaded, and the extracted text was displayed in the red frame below in a few seconds. The accuracy of OCR is high and it can extract data well.

Next, I tried loading the PDF file. Drag and drop the PDF file of the beginning of Arthur Conan Doyle's `` A Study in Scarlet .''
The text was read out as shown below. According to Mr. Wilson, the accuracy of text extraction will decrease if the PDF file consists of multiple columns.

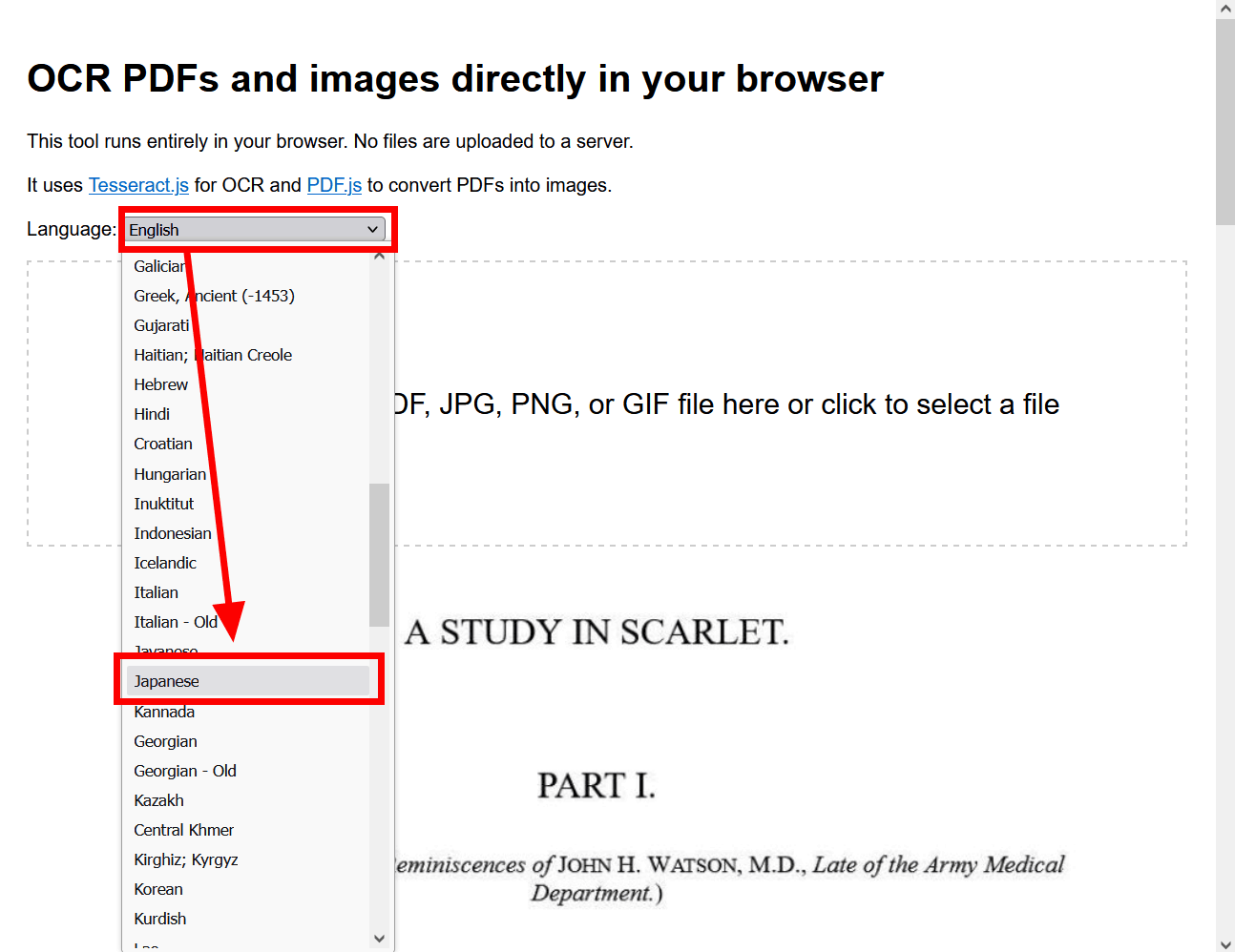
OCR PDFs and images directly in your browser supports not only English but also various languages including Japanese. To change the language to be extracted, select 'Japanese' in the 'Language' item.
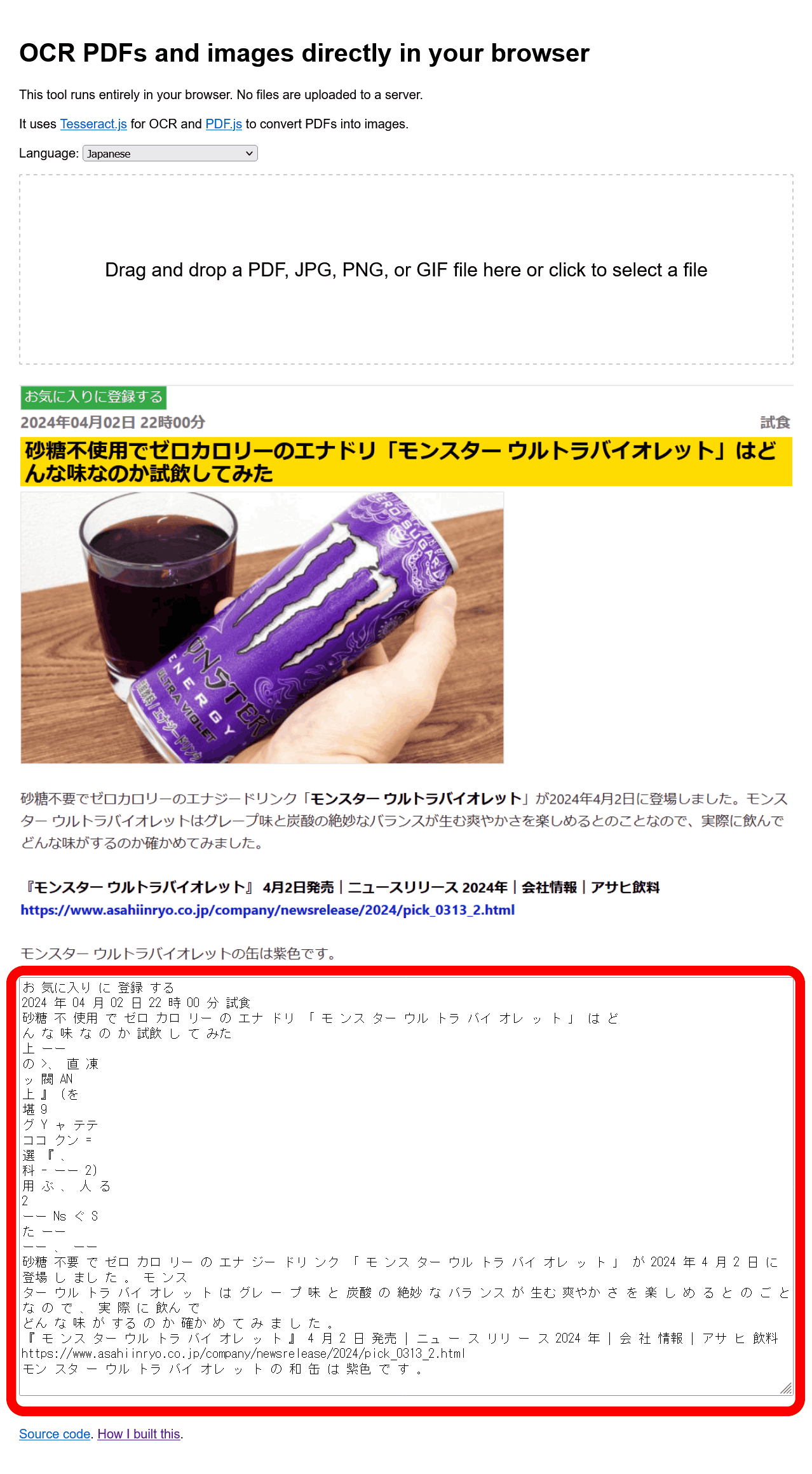
As a test, I tried loading the following image, which is a screenshot

The text of the article was extracted from the image, but as you can see in the image below, the accuracy seems to be considerably lower than in English, as the spacing between letters is inconsistent and non-existent kanji are inserted. However, it is still possible to extract text with considerable speed.
OCR PDFs and images directly in your browser is developed in open source, and the source code is published in the GitHub repository below.
tools/ocr.html at main · simonw/tools · GitHub
https://github.com/simonw/tools/blob/main/ocr.html
Regarding his motivation for developing OCR PDFs and images directly in your browser, Mr. Wilson said, ``In recent years, large-scale language models such as Gemini Pro 1.5 , Claude 3 , and GPT-4 have become extremely popular as a method for extracting data from PDF files and images. We are seeing promising results. However, these tools are still inconvenient for most people. On the other hand, older tools like Tesseract OCR are still very useful.' It seems that Claude 3 and ChatGPT are used for the development of OCR PDFs and images directly in your browser.
Related Posts:



in Review, Web Application, Posted by log1i_yk