OpenAIの「超知性」誕生に備える研究チームがGPT-2のような弱いAIモデルでGPT-4のように強力なAIを制御する方法を詳しく説明

チャットAI「ChatGPT」などの開発で知られるOpenAIは、人間よりもはるかに賢いAIである「超知性」が2033年までの10年間で開発されると推測しています。しかし、超知性を確実に制御する方法は現状構築されていません。OpenAIでは「スーパーアライメントチーム」を立ち上げ、超知性を制御するための研究が行われており、その方法を解説しています。
WEAK-TO-STRONG GENERALIZATION: ELICITING STRONG CAPABILITIES WITH WEAK SUPERVISION
(PDFファイル)https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
Weak-to-strong generalization
https://openai.com/research/weak-to-strong-generalization
OpenAI thinks superhuman AI is coming — and wants to build tools to control it | TechCrunch
https://techcrunch.com/2023/12/14/openai-thinks-superhuman-ai-is-coming-and-wants-to-build-tools-to-control-it/
OpenAI Demos a Control Method for Superintelligent AI - IEEE Spectrum
https://spectrum.ieee.org/openai-alignment
人間の知性を超えるような来たるべき「超知性」の開発に備えて、OpenAIではコンピューティング事業のうち約20%を超知性の制御のための「スーパーアライメント」に充てており、2027年までに超知性の制御に向けたソリューションを構築することを目指しています。一方で、スーパーアライメントチームのコリン・バーンズ氏は「設計方法すら分からない、現状開発されていない超知性に対する研究を行うことは非常に困難です」と述べ、スーパーアライメントの研究に問題を抱えていることを明らかにしています。
それでも、スーパーアライメントチームが2023年12月に発表した論文では、いまだ開発されていない超知性の制御に関する問題を回避するための方法を示しました。
これまでの人間の賢さの枠を超えないAIは人間による監督が可能でしたが、今後超知性が開発されるにしたがって、AIの賢さを下回る人間ではAIの監視が困難になります。そのため、知性が低い監督者が、自身よりも強力なAIを制御するための方法の構築が急務となります。そこでスーパーアライメントチームは、人間が超知性を適切に監視できるかを見る代わりに、大規模言語モデルのGPT-2がより強力なGPT-4を監督できるかというテストを行いました。科学系雑誌のIEEE Spectrumによると、GPT-2のパラメーターは15億程度であるのに対し、GPT-4のパラメーターは約1760億に上るとのこと。
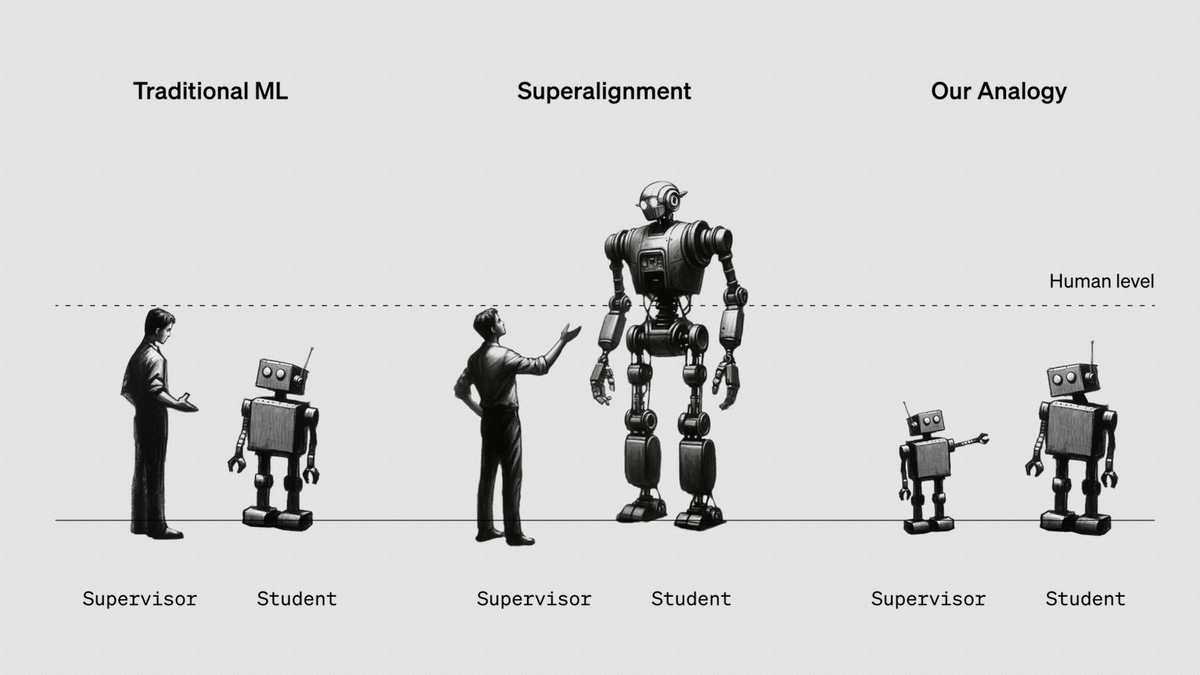
スーパーアライメントチームはそれぞれの大規模言語モデルに対し、チェスパズルや常識的推論などの自然言語処理(NLP)ベンチマークのセット、ChatGPTの回答のデータセットに基づく質問という3種類のタスクを与えました。GPT-2はこれらのタスクに特化してトレーニングが行われてきた一方で、GPT-4では基本的なトレーニングのみが行われ、これらのタスクの微調整は行われませんでした。しかし、基本的なトレーニングの観点では、GPT-4がGPT-2のパフォーマンスを上回っています。
GPT-2はタスクの実行方法の指示をGPT-4に与え、GPT-4はそのタスクを実行します。そのため、スーパーアライメントチームは「GPT-4は、監督者であるGPT-2と同じ間違いを犯すのではないか」と予測していました。しかし、強いモデルであるGPT-4は監督者であるGPT-2を一貫して上回りました。特に、NLPタスクではGPT-3.5に匹敵するレベルの精度で機能することが明らかになり、知性が低いGPT-2の監督の下でも、GPT-4の能力の多くを引き出すことに成功したことが報告されています。
スーパーアライメントチームはこの現象を「弱から強への一般化」と呼んでおり、これは「強力なモデルがタスクの実行方法に関する暗黙の知識を有しており、弱い監督者から不適切な指示が与えられても、自身の中にある知識を用いてタスクを実行できることを示している」というものです。つまり、監督者である弱いモデルからエラーやバイアスを含む指示が与えられても、強力なモデルは監督者の意図に沿うような結果を出力するため、強力なAIが監督者の破滅を導くような結果にはならないとされています。

一方でスーパーアライメントチームは、「今回の検証方法はあくまで概念的なものであり、ChatGPTのデータを用いた実験ではうまく機能しませんでした。そのため将来的な弱から強への一般化が困難になる可能性もあります」と述べつつも、「将来的な超知性の制御に向けた研究の第一歩となることを期待しています」と語っています。実際にスーパーアライメントチームは、今回の実験で用いたソースコードをGitHub上で公開するとともに、超知性の制御に関する研究に取り組む学生や研究者に対して1000万ドル(約14億円)規模の助成金制度を2024年2月から開始することを発表しました。
スーパーアライメントチームのレオポルド・アッシェンブレナー氏は「OpenAIのAIモデルの安全性だけでなく、他のAI開発組織のモデルやその他の高度なAIの安全性にも貢献することは、OpenAIの使命の一つです。この研究を行うことは、超知性を人間にとって有益なものにして、安全に扱うために絶対に不可欠なものであると考えています」と述べています。
・関連記事
「ChatGPT」や「DALL-E 2」を開発したOpenAIのCEOが「汎用人工知能」についての展望を発表 - GIGAZINE
OpenAIが開発している新型AI「Q*(キュースター)」とは一体どのようなものだと推測されているのか? - GIGAZINE
ChatGPTの開発元OpenAIが「10年以内にAIがほとんどの分野で専門家のスキルレベルを超える」という懸念に基づき「超知能AI」の登場に備えるべく世界的な規制機関を立ち上げる必要があると主張 - GIGAZINE
ChatGPTの回答には政治的偏りによるバイアスが潜んでいるという研究結果 - GIGAZINE
DeepMindの研究者が「AIが人類を滅ぼす可能性は高い」との論文を発表 - GIGAZINE
・関連コンテンツ







