




自己学習する「人間のような」次世代人工知能を開発するカギとなるものは?

By angelo Yap
ついにコンピューターが囲碁でプロ棋士に勝利したことが話題となったように、近年、人工知能技術のめざましい進化が話題となっています。そんな人工知能をさらにもう一歩進化させるために必要なものを、アメリカのビジネス誌Fortuneが探っています。
Why Memory and Mimicry Are The Next big Frontiers in AI - Fortune
http://fortune.com/2015/12/04/next-ai-frontier/
過去数年間、人工知能開発に携わる研究者たちはコンピューターが独力で音声や画像認識できるようにするため、ディープラーニングを使用したコンピューターにさまざまな情報を学習させてきました。しかし現在、既にコンピューターの画像・音声認識機能はかなりのレベルにまで進化しており、これらの機能が今後も徐々に改良されていくことは明らかです。また、これまで抱えてきたアルゴリズムや基礎研究における難問の多くはほとんど解明されてしまった状況、とのこと。

By hyoin min
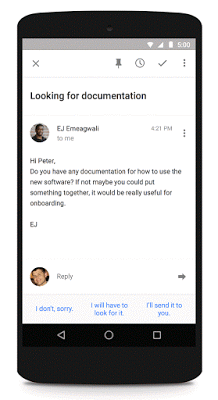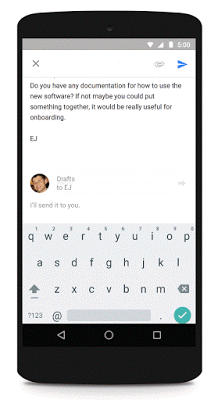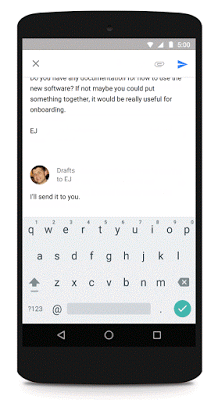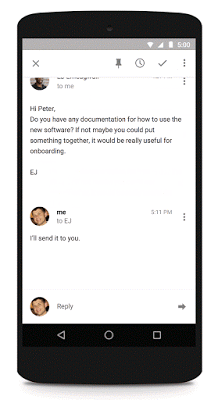
2015年に人工知能関連技術で特に注目を集めたのが、大手テクノロジー企業であるGoogleとFacebookで、2社は大きなブレイクスルーとなる新プロダクトをそれぞれ披露しています。Facebookの開発した革新的技術というのが、2015年秋に発表された人工知能アルゴリズムの「Memory Networks」で、赤ん坊のようにコンピューターが学習することを手助けするというもの。対して、Googleが公開したのは、Facebookとは異なる方法でコンピューターに学習させる技術で、状況や問題に応じて時間や記憶を加える、というものでした。Googleはこの人工知能技術を自社の翻訳ツールに応用しており、Inbox by Gmailの「Smart Reply」という機能にも応用しています。
Smart ReplyはInbox by Gmailで使用できる機能で、受信メールのテキストを解析してそれに応じた返信を3種類提示する、というもの。
その他、人工知能関連分野で注目を集めたのが産業用ロボット向けの機械学習ソフトウェアを開発するスタートアップ「Osaro」。2015年末にシリコンバレーの著名投資家であるピーター・ティール氏や実業家のスコット・バニスター氏、さらにはYahoo!のジェリー・ヤン氏などから合計330万ドル(約4億円)の資金調達に成功し話題となりました。Osaroは「ディープ・レインフォースメント・ラーニング」と呼ばれる、ディープラーニングと強化学習の一種であるQ学習とを融合させた新しい方法を研究レベルから製品レベルに進化させるための開発を行っています。
Osaroの共同創立者であるデリク・プリッドモア氏はコンピューターには「次に何がくるのか」を解明するための明確な方針(policy)が必要、と語ります。これまで、エンジニアはこの方針を巧妙に作成してきたわけですが、こういった方針には拡張性がないそうです。そこで役立つのが「ディープ・レインフォースメント・ラーニング」です。ディープ・レインフォースメント・ラーニングはコンピューターを完全に動作させるため、正しい行いを学習させ、正しい結果を生み出せるようにするための学習方法です。
なお、Googleが買収したDeepMindがディープ・レインフォースメント・ラーニングの最も有名な事例である「DQN」を開発しています。DQNは、人間が手を加えずとも自動で学習を繰り返すことで、単純なゲームなどでハイスコアをたたき出せるようになるというもの。DQNの詳細は以下の記事で確認できます。
ゲームを自ら学んで人間以上に上達できる人工知能「DQN」が人間を脅かす日はいつくるのか? - GIGAZINE

こういった類いの研究は、これまでは研究開発の領域を出られないレベルでした。実際、多くのテクノロジー企業はまだ人工知能の開発において研究開発の領域を抜け出せていないそうです。しかし、Osaroのプリッドモア氏は研究開発を飛びこえ、ロボットが状況を認識したり認識した情報を基に動作を起こしたりするために必要な学習を提供するためのプロダクションシステムを構築することを計画しています。
Osaroが製品化に向けて開発を進めるソフトウェアは、理論上は「ロボットにタスクとタスクから学べること」を教えることができます。さらに良いことに、ソフトウェアは学習した知識を環境ごとにパラメーターとして適応させて使用することも可能です。この技術のカギとなるのは、パラメーターはプログラムされるのではなく学習させることができるという点で、これにより利用者によって異なるロボットの使用環境に、各ロボットが自動で最適化されていくことになるというわけ。

By Patrick Lentz
DeepMindのDQNは無作為にゲームをプレイしまくることで学習を進めていきますが、現実世界でそのようなことを行えば、莫大な時間と費用が必要になります。そこで、Osaroはコンピューターの学習過程をサポートするためのアルゴリズムを、「人間を模倣すること」で作成したそうです。もちろん人間の学習法を模倣しているのはOsaroだけではなく、ワシントン大学は子どものように学習するロボットを発表しています。
「Minds.ai」と呼ばれるスタートアップのCEOであるスーミット・サンヤル氏は「強化学習は人工知能分野の最前線に位置しています。強化学習こそが、貧弱な人工知能を強力なものにするのです」と語っているように、強化学習とディープラーニングを掛け合わせることが、次世代の人工知能誕生のカギとなっているようです。
・関連記事
Googleはモバイル端末に人工知能を組み込み「関係性」を理解できる専用チップ開発を計画している - GIGAZINE
人工知能やロボットなどで代替可能な職業100&代替されない可能性が高い職業100まとめリスト - GIGAZINE
人工知能は核兵器よりも潜在的に危険、ホーキング博士が「100年以内に人工知能は人間を超える」と警告 - GIGAZINE
Googleの人工知能開発をリードするDeepMindの天才デミス・ハサビス氏とはどんな人物なのか? - GIGAZINE
Googleの自己学習する人工知能DQNを開発した「ディープマインド」の実態、何が目的なのか? - GIGAZINE
・関連コンテンツ








in メモ, Posted by logu_ii
You can read the machine translated English article Self-learning "Like a human" What is the….