大規模な分散システムを構築する際に押さえておくべき概念

By tec_estromberg
他の人が分散システムを構築する際に参考になるように、UberのエンジニアリングマネージャーのGergely OroszさんがUberのバックエンドを構築する際に必要だった概念や経験などをブログにまとめています。
Distributed architecture concepts I learned while building a large payments system
http://blog.pragmaticengineer.com/distributed-architecture-concepts-i-have-learned-while-building-payments-systems/

大規模で利用率が高い分散システムを構築する際にはさまざまなことを考慮する必要があります。Oroszさんのブログには「SLA」「スケーリング」「一貫性」「データの持続性」「メッセージの永続性と持続性」「べき等性」「シャーディングとクォーラム」「アクターモデル」「リアクティブ・アーキテクチャ」といった概念が簡単にまとめられています。
・SLA
SLAとはService Level Agreement(サービス品質保証)の略で、どの程度の品質のサービスを提供しなければならないのかというもの。「Availability(可用性)」「Accuracy(正確性)」「キャパシティ」「Latency(応答時間)」などが指標として使用されます。
可用性とはサービスが稼働している時間の割合のことで、例えば99.99%というのは年間のダウンタイムが約50分であったことを意味します。
正確性はシステム内のどの程度の割合のデータが正確であることを保証される必要があるかというものです。例えば決済システムなどは100%の正確性を持つ必要があります。
キャパシティはシステムがサポートできる負荷の指標で、通常1秒あたり何リクエストまでシステムがさばけるのかという数字で表されます。
応答時間とはどの程度の時間で応答を返せるかという指標で、リクエストのうち95%に応答できた時間と99%に応答できた時間などがよく使用されます。

By Z Jason
Oroszさんの仕事は既存の決済システムを置き換える新しいシステムを開発することだったため、目標として「前のものよりも良いSLA」をターゲットに設定してアーキテクチャなどを検討していったとのことです。
・スケーリング
ビジネスが成長した場合、多くの場合負荷も増大します。ある時点で既存のシステムでは増大した負荷に対応できなくなり、システムのスケールを拡大する必要がでてきます。一般的なスケーリング戦略として、「水平スケーリング」と「垂直スケーリング」があげられます。
水平スケーリングとは、システムに新たなマシン(ノード)を追加してスケーリングを行うことです。クラウドを利用している場合などボタンを押すだけで簡単に実行できるため、分散型システムの拡張には水平スケーリングが一般的に使用されています。
垂直スケーリングは、コンピュータを買い替えるように「より強力なマシンを購入する」というものです。分散型システムの場合、垂直方向のスケーリングは水平方向のスケーリングに比べてコストがかかるため、通常はあまり行われませんが、Stack Overflowなどいくつかのサイトは垂直方向にスケーリングされています。
・一貫性(Consistency)
分散システムは可用性の低いマシン(ノード)で構築されることが多いです。たとえノード1台1台の可用性が99.9%だったとしても、複数のノードを組み合わせることでそのうちの1つが落ちている時でもサービスを提供できるようにすればシステム全体としての可用性は高まります。
こうした高可用性のシステムでは一貫性が重要になります。一貫性とは、全てのノードが同じリクエストに対しては同じレスポンスを返すというものです。可用性を高めるために複数のノードを追加した場合、一貫性を保つのはそれほど簡単ではなく、ノード間の通信が失敗した場合などさまざまな状況に対応する必要があります。
Wikipediaなどをみるとさまざまなモデルが確認できますが、分散システムでよく使用されているのは(pdf)「strong consistency(強一貫性モデル)」「weak consistency(弱一貫性モデル)」「eventual consistency(結果整合性モデル)」の3つです。Hackernoonの記事「eventual vs strong consistency」に結果整合性モデルと強一貫性モデルのそれぞれの利点と欠点がどんなものなのかが書かれています。原則として、一貫性の水準を下げるとシステムは速くなりますが最新のデータを返さない可能性が高まります。
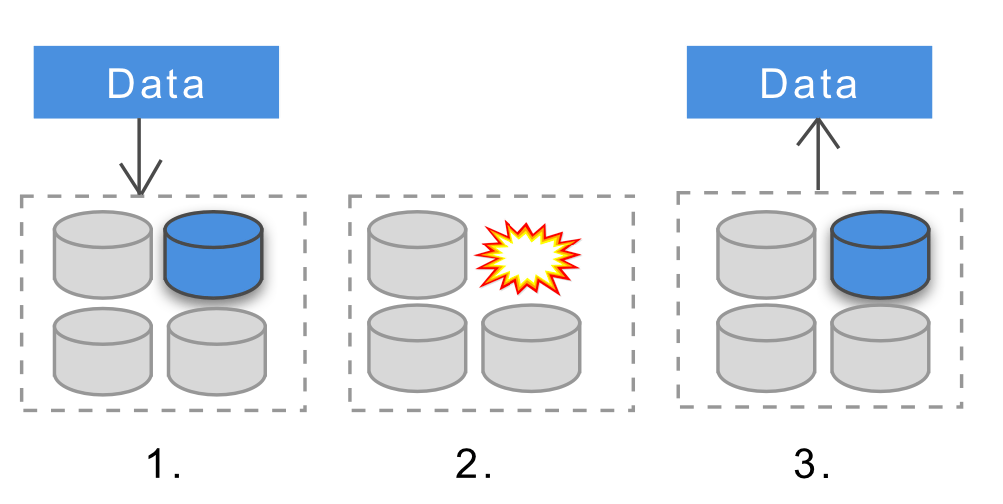
・データの持続性(Data Durability)
持続性とは、「一度正しくデータベースに加えられたデータが将来にわたって利用可能であること」という意味です。これはいくつかのノードがクラッシュしたり通信が途切れたりしてもデータベースからデータが取り出せるようにすることを意味します。
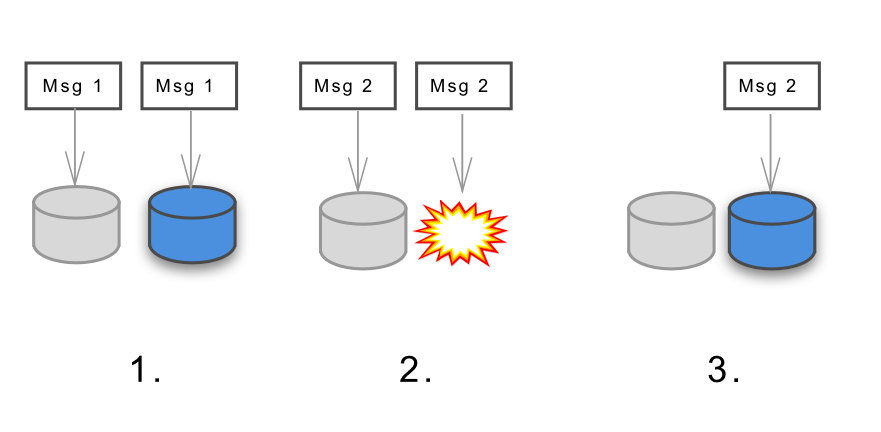
・メッセージの永続性と持続性(Message Persistence and Durability)
分散システムにおいてはノードが相互にメッセージを送信します。ここで重要になってくるのは、メッセージが正しく届かない可能性があるということです。ミッションクリティカルなシステムにおいてはいかなるメッセージも失われてはいけません。分散システムではRabbitMQやKafkaといったメッセージサービスがよく使用されます。これらのメッセージサービスはメッセージの送信において複数の水準での信頼性を保つことができます。
メッセージの永続性とは、万が一メッセージを処理中のノードで障害が発生した場合でも、障害が解決された後にメッセージが正しく処理されることを意味します。メッセージの持続性とは、主にメッセージキューで使用されるもので、メッセージが送られる時に送信先のノードがオフラインでも、ノードがオンラインに戻った時にちゃんと届くようになっていることを意味しています。
・べき等性(Idempotency)
べき等性とは、「同じ操作が何回実行されても同じ結果を返す」ことを意味します。例えば、決済システムにおいてクライアントが支払中に接続が切れ、再接続を繰り返す中で何度も支払を要求した場合でも、実際に支払が行われるのは1回限りである必要があります。べき等性を持った分散システムを構築するには、何らかの分散ロックシステムが必要で、よくオプティミスティックロックなどが使用されます。エンジニアのベン・ナデルさんが書いたべき等性を達成するために使用したさまざまな戦略についての記事が参考になるとのこと。
・シャーディングとクォーラム(Sharding and Quorum)
分散システムでは、1つのノードが保持できるよりも多くのデータを保存する必要があります。そこで使用される手法がシャーディングで、データをある種のハッシュで水平方向に分割し、パーティションに割り当てる方法です。
多くの分散システムは、複数のノードがデータのコピーを持っています。オペレーションが一貫した方法で実行されるようにするために、特定の数のノードが同じ結果を返すという投票ベースのアプローチが設計されます。これをクォーラムと呼びます。
・アクターモデル(Actor model)
変数やインターフェース、メソッドの呼び出しなど、プログラミングに出てくる通常の言葉は1つのマシンで動くシステムを想定しており、分散システムについて話す時は別のアプローチを使用する必要があります。一般的に使用されるのがアクターモデルで、これはコードをコミュニケーションの観点からとらえるものです。他にはCommunicating Sequential Processes(CSP)という方法も人気があります。
アクターモデルは、相互にメッセージを送りあう「アクター」をベースにしたモデルです。それぞれのアクターは他のアクターを作成したり、他のアクターにメッセージを送ったり、次のメッセージで何をすべきか決めるといった限られた機能しか持ちませんが、いくつかの簡単なルールで複雑な分散システムをうまく表現できる上に他のアクターがクラッシュした時に修復を行うことも可能です。アクターモデルについては「The actor model in 10 minutes」という記事がオススメされています。また、さまざまなプログラミング言語にアクターモデルのライブラリが存在します。
・リアクティブ アーキテクチャ(Reactive Architecture)
大規模な分散システムを構築する場合、普通は弾力性があって障害からの復旧が早く、スケール可能なシステムというのが目標になります。リアクティブ・アーキテクチャは、そうしたシステムを組む際に広く使用されているパターンです。リアクティブ・アーキテクチャについては、「Reactive Manifesto」という記事や「Reactive Application Development」という本の著者へのインタビューが参考になるとのこと。
Oroszさんは分散システムについて学ぶ人の助けになることを望んでいるとブログを締めくくっています。
・関連記事
Western Digitalが次世代コンピューティングアーキテクチャ「RISC-V」の推進を加速 - GIGAZINE
世界中のソフトウェアアーキテクトの知見や助言がまとめたられた書籍「ソフトウェアアーキテクトが知るべき97のこと」がウェブ上で無料公開中 - GIGAZINE
人工知能や機械学習のパフォーマンスを最大50倍に向上させ10倍も高速化できるARMの「DynamiQ」 - GIGAZINE
AWSを10年運用してわかったことをAmazonの最高技術責任者が語る - GIGAZINE
無料で使えるアプリ版Google Analyticsとでも言うべき「Firebase Analytics」などを繰り出すGoogle傘下Firebaseのすごいバックエンド機能まとめ - GIGAZINE
・関連コンテンツ