GoogleがAIの誤情報生成を防止するAIモデル「DataGemma」をリリース、「信頼できるデータ集」を参照して幻覚(ハルシネーション)を軽減

チャットAIやコード生成などに用いられる大規模言語モデル(LLM)の開発が急速に進んでいますが、LLMには誤った情報を真実かのように出力してしまう「幻覚(ハルシネーション)」という問題が存在しています。このハルシネーションを軽減できるAIモデル「DataGemma」がGoogleによって公開されました。
DataGemma: AI open models connecting LLMs to Google’s Data Commons
https://blog.google/technology/ai/google-datagemma-ai-llm/
Grounding AI in reality with a little help from Data Commons
https://research.google/blog/grounding-ai-in-reality-with-a-little-help-from-data-commons/
DataGemmaは、Googleが主導するデータセット集積プロジェクト「Data Commons」の情報を参照して回答に活用できるAIモデルです。Data Commonsには国連や世界保健機関といった信頼性の高い機関が発表したデータセットが含まれており、これらの情報を出力に含めることで、ハルシネーションを軽減して回答の正確性を高めることができます。
DataGemmaはGoogle製のオープンソースLLM「Gemma 2 27B」に微調整を施したもので、「Retrieval-Interleaved Generation(RIG)」と「Retrieval-Augmented Generation(RAG)」という2種類の手法に最適化されています。各手法の仕組みは以下の通り。
◆Retrieval-Interleaved Generation(RIG)
RIGでは、回答を生成する際に「Data Commonsからデータを取得するプロセス」を挟み、信頼性の高いデータを含む回答を出力します。
例えば、一般的なLLMに「再生可能エネルギーの使用量は増えているの?」と聞くと「はい。増えています。全体の12%以上が再生可能エネルギーで、これは2000年から6%増えています」といったような回答が出力されます。
一方で、DataGemmaでは最終的な回答を生成する前に、内部で「はい。増えています。全体の12%以上 || [Data Commonsに世界全体の何%が再生可能エネルギーなのか問い合わせる] が再生可能エネルギーで、これは2000年から6% || [Data Commonsに世界全体の再生可能エネルギー使用量は2000年からどれだけ増えているのかか問い合わせる] 増えています」というData Commonsへの問い合わせ文を含む文章を生成。そして、Data Commonsから目的の情報を得た後に「はい。増えています。全体の12% || 18.71% 以上が再生可能エネルギーで、これは2000年から6% || 16.87% 増えています。」といった正しい数字付きの回答を出力します。
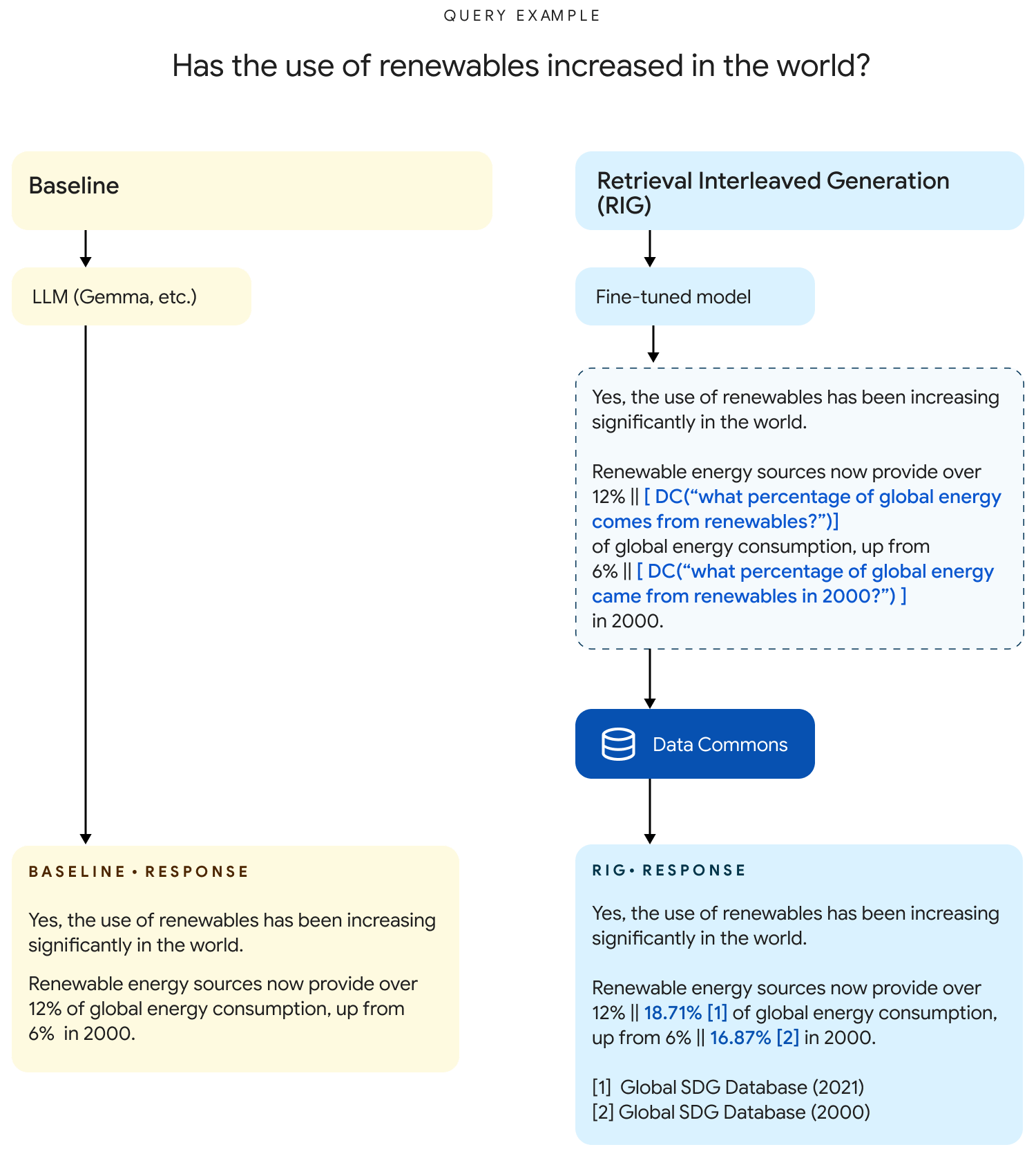
RIGはあらゆる質問に適用可能ですが、DataGemmaがData Commonsの情報を保持できないため、「続く質問にData Commonsのデータが反映されない」という問題があります。
◆Retrieval-Augmented Generation(RAG)
RAGでは、質問に応じてDataGemmaで「Data Commons向けの質問」を生成し、「Data Commonsから得られたデータ」を補助LLMに入力して最終的な回答を出力します。
例えば、「再生可能エネルギーの使用量は増えているの?」という質問が入力された場合、DataGemmaが「世界全体の再生可能エネルギーの使用割合は?」「世界全体の再生可能エネルギーの使用割合の推移は?」といったData Commons向けの質問を生成し、Data Commonsから得たデータを補助LLMに入力して「2021年の世界全体の再生可能エネルギー使用率は18.71%です。これは2000年と比べて16.87%高い値です」といった回答を出力します。
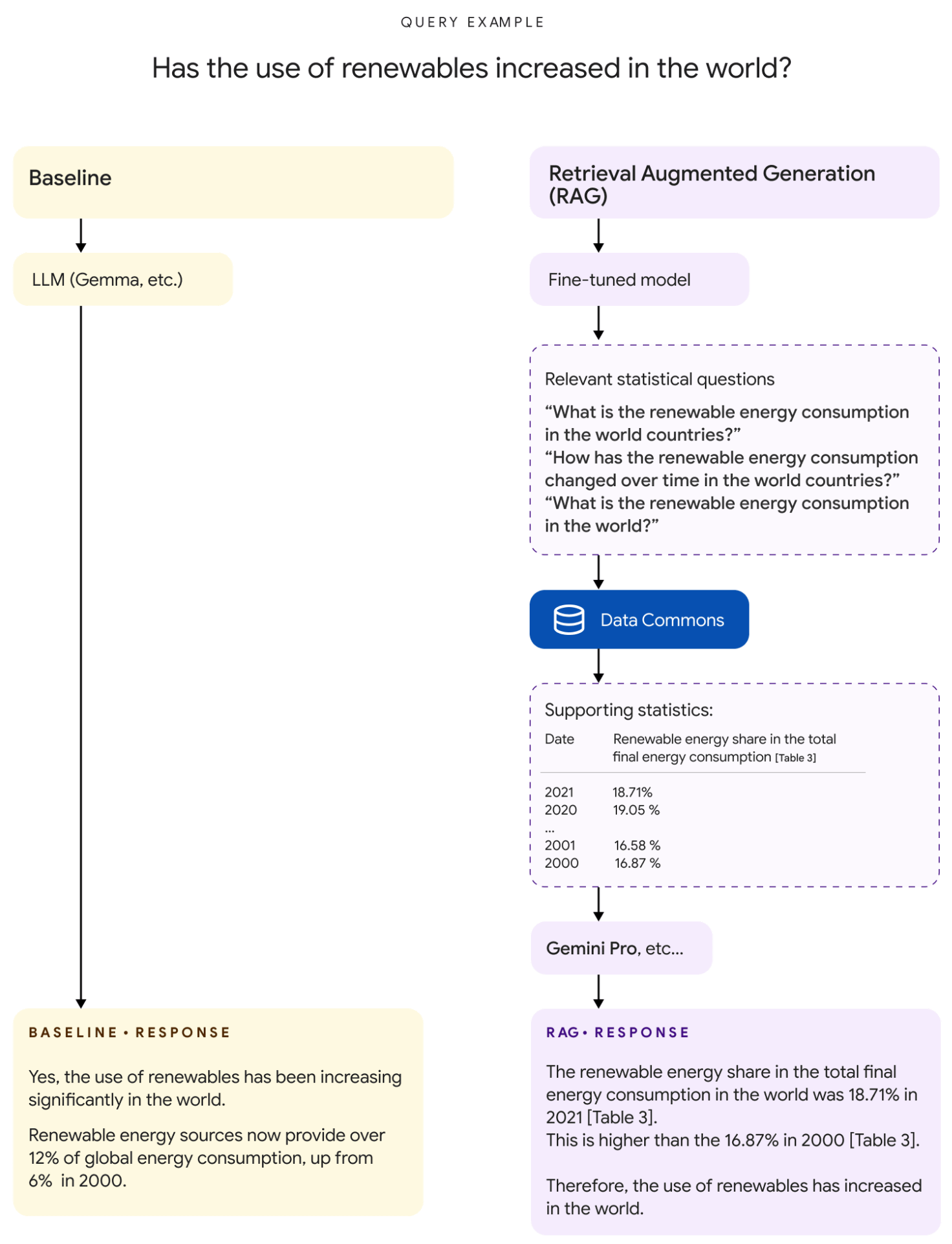
Googleの実験では、補助LLMに入力するデータの大きさは平均3万8000トークン、最大34万8000トークンだったとのこと。このため、補助LLMにはGemini 1.5 Proなどのコンテキストウィンドウの大きなLLMを用いる必要があります。また、ユーザーの質問内容によっては直感的でない回答を出力してしまうこともあるとのこと。
なお、GoogleはRIGとRAGに最適化したDataGemmaのモデルデータを以下のリンク先で公開しています。
DataGemma Release - a google Collection
https://huggingface.co/collections/google/datagemma-release-66df7636084d2b150a4e6643
また、DataGemmaの研究論文は以下のリンク先で確認できます。
Knowing When to Ask - Bridging Large Language Models and Data
(PDFファイル)https://docs.datacommons.org/papers/DataGemma-FullPaper.pdf

・関連記事
AI検索エンジン「Perplexity」の中の人に「どんな広告を表示するの?」「日本ではどう展開するの?」などいろいろ聞いてきた - GIGAZINE
Metaの生成AIがトランプ前大統領暗殺未遂事件について答えなかったことをユーザーが問題視、Metaは「幻覚のせい」と指摘 - GIGAZINE
生成AIの幻覚で指定される「架空のパッケージ」に悪用の危険性があるとセキュリティ研究者が警告 - GIGAZINE
さまざまなチャットAIがどれくらい幻覚を見るのかをランキングにした「Hallucination Leaderboard」が公表される - GIGAZINE
AIと人間の「幻覚」はどう違うのか? - GIGAZINE
・関連コンテンツ