Google has introduced QAT, a memory-saving technology for running AI locally on smartphones and laptops, to Gemma 4, allowing Gemma 4 E2B to run with just 0.84GB of memory.

Running AI requires a large amount of memory, and 'quantization' is widely used as a technique to reduce the memory usage of the AI model. Google has now released ' Gemma 4 QAT, ' a memory-saving version of Gemma 4 that adopts an approach of 'simulating quantization during the training phase.'
Gemma 4 with quantization-aware training
When running an AI model locally on a typical PC, the model is first loaded into the ultra-fast VRAM. Any portion that doesn't fit in VRAM is loaded into the relatively slower RAM, and if it still doesn't fit in RAM, it's loaded into the swap file on the SSD. Therefore, to run an AI system quickly, you need to select an AI model that fits within the VRAM. High-performance AI models often use tens to hundreds of gigabytes of memory, but by using a technique called 'quantization,' which reduces memory usage by lowering the computational precision of the AI model, it's possible to run high-performance AI models on a home PC.
Many publicly available quantized models are AI models that have been quantized after completion, and since quantization inherently 'reduces computational precision,' response quality inevitably deteriorates. Gemma 4 QAT is a model that employs a technique called 'Quantization-Aware Training (QAT),' which simulates quantization during the AI model's training phase. It successfully achieves memory savings through quantization while minimizing quality degradation.
The Gemma 4 QAT is compatible with all variations of the Gemma 4: E2B, E4B, 12B, 26B A4B, and 31B. Additionally, optimized versions for mobile use are available for the E2B and E4B models.
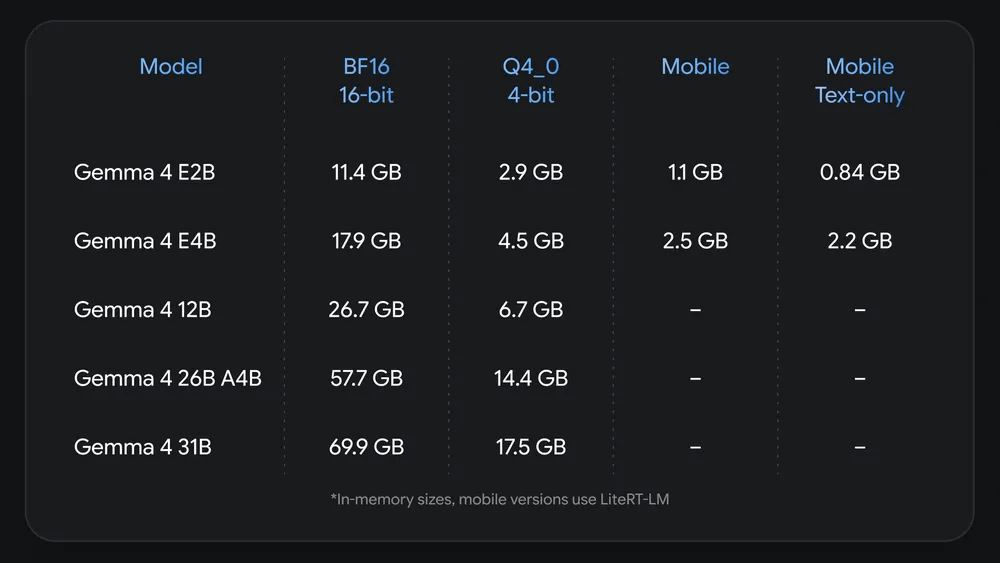
The following diagram summarizes the memory usage of each model. The original Gemma 4 E2B consumes 11.4GB of memory, but the QAT version (Q4_0 4-bit) uses 2.9GB, and the mobile version uses 1.1GB. Furthermore, a text-only model of the Gemma 4 E2B, which omits image and speech recognition capabilities, can run on as little as 0.84GB of memory. Other models also successfully achieve significant memory usage reductions while minimizing quality degradation.
Each model of Gemma 4 QAT is available at the following link. It is free to download and licensed under the Apache License 2.0 . It is also explicitly stated that it can be run using llama.cpp, Ollama, and LM Studio.
Gemma 4 QAT Q4_0 - a google Collection
https://huggingface.co/collections/google/gemma-4-qat-q4-0
Related Posts:







in AI, Posted by log1o_hf