How does Google's 'Gemma 4 12B,' which runs on laptops, process images and audio without the need for an encoder?
Google released
A Visual Guide to Gemma 4 12B - by Maarten Grootendorst
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-gemma-4-12b
Gemma 4 12B is a 120-parameter multimodal model that runs on 16GB of memory, offering performance close to the Gemma 4 26B A4B, which has a larger total number of parameters. Details about Gemma 4 12B and where to download it are explained in detail in the article below.
Google releases 'Gemma 4 12B,' an AI model that can run on laptops, for free; it requires 16GB of VRAM - GIGAZINE

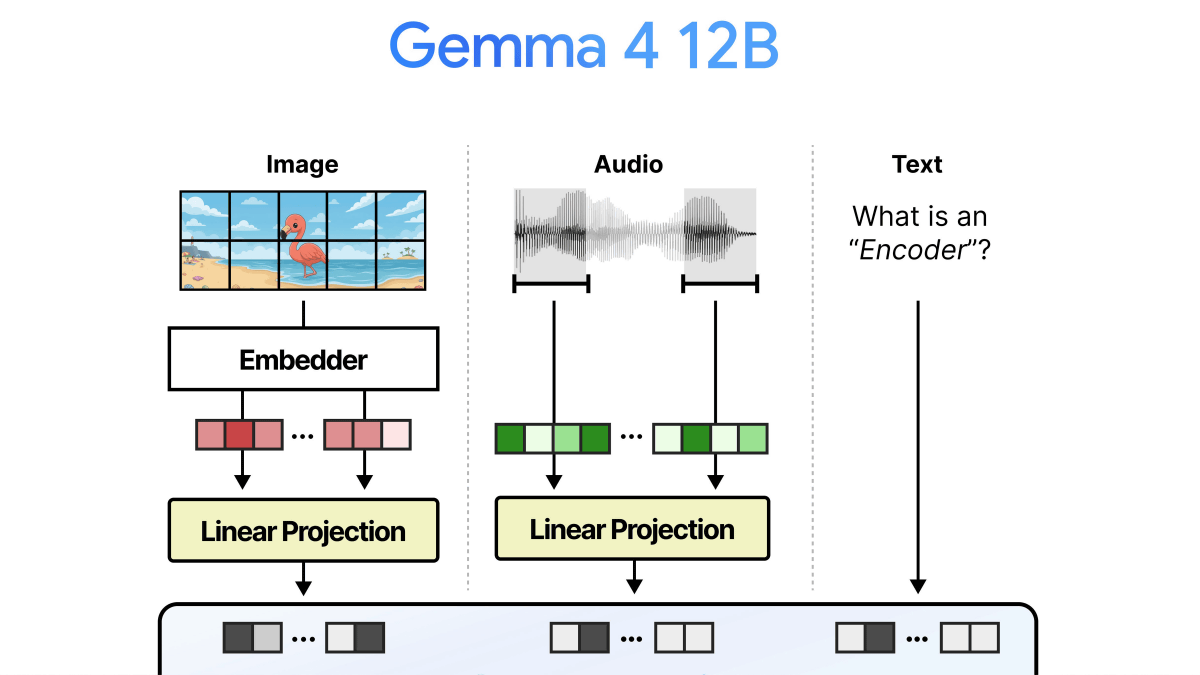
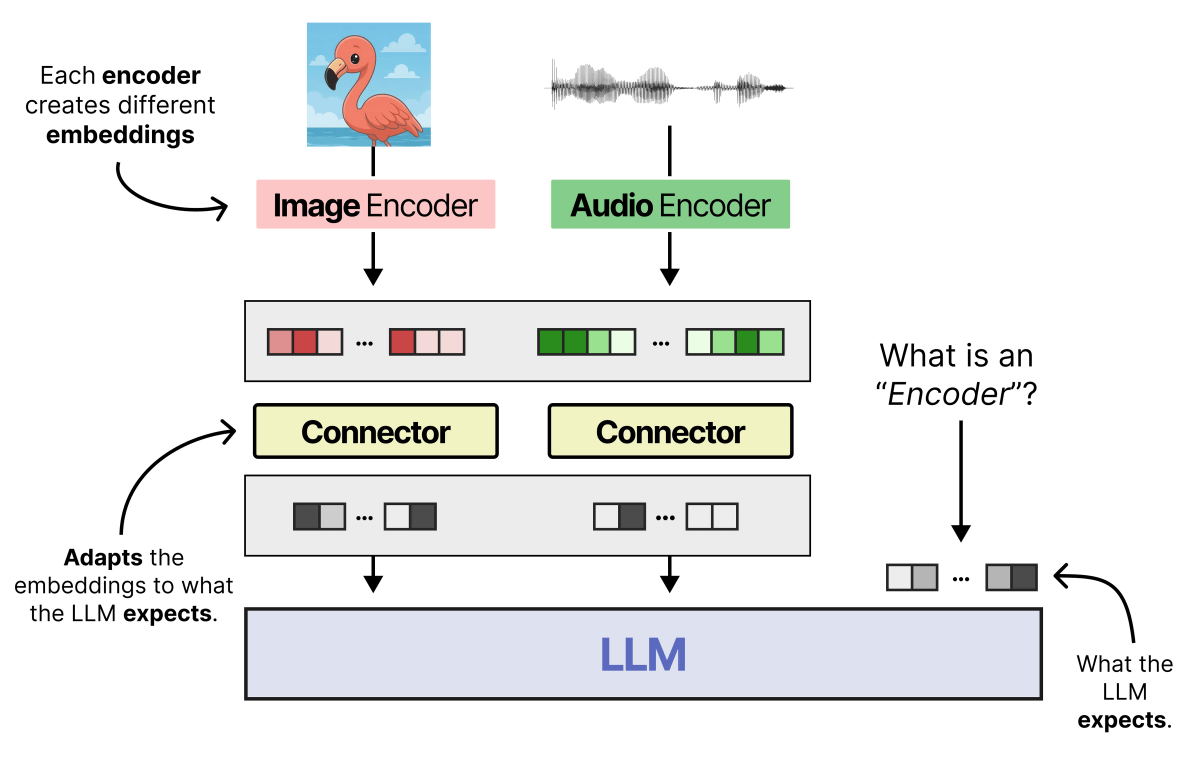
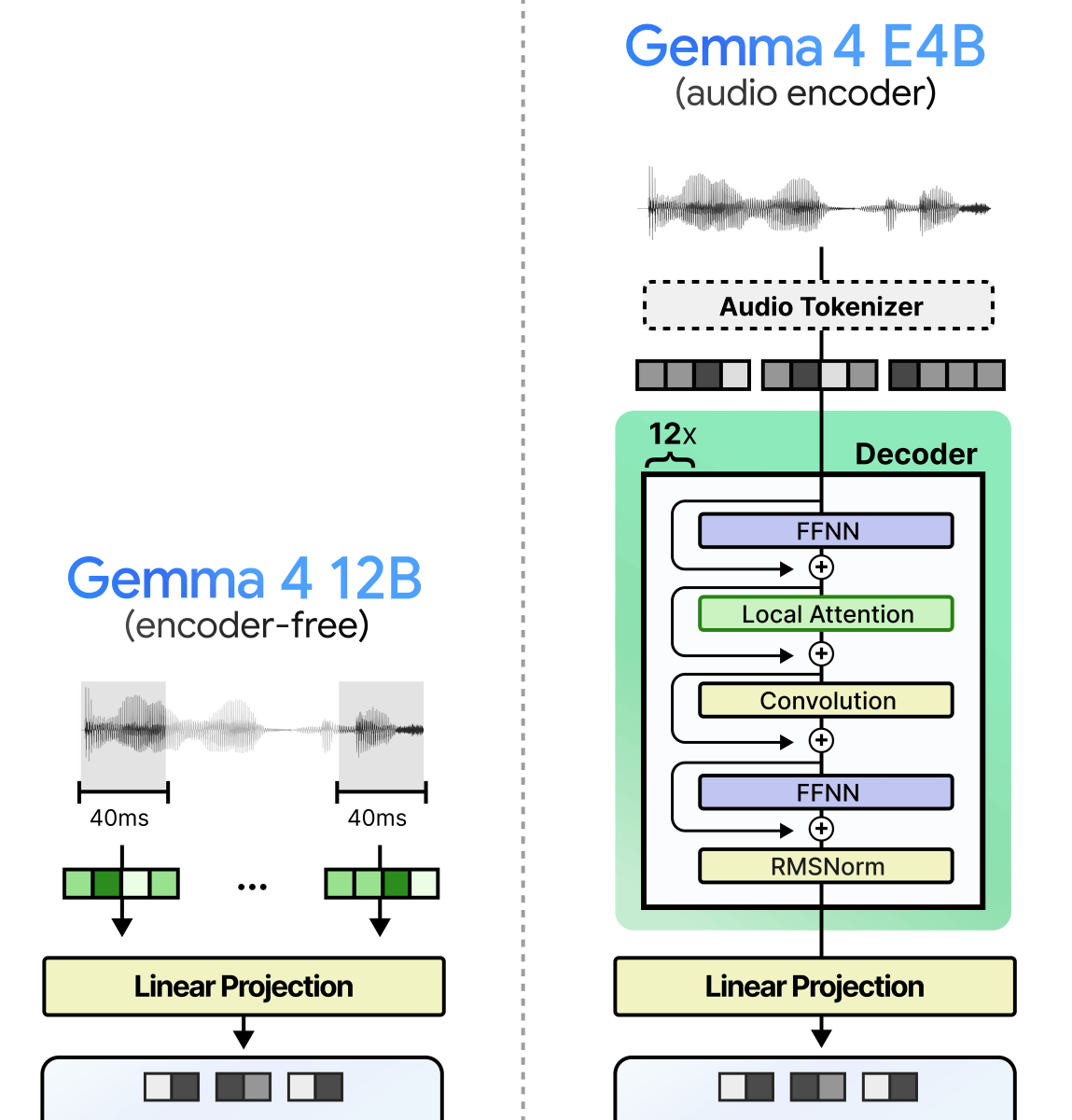
Gemma 4 12B is not only lightweight, but it also has the unusual feature of being able to process audio and images without an encoder. The following diagram shows the image and audio processing flow of a typical multimodal model. In a typical model, the input image or audio needs to be converted into a format called 'embedding,' which is easy for the AI model to understand, using an encoder, and then further formatted into data that can be processed by LLM using a 'connector.' Since the encoder itself is a small AI model, in a multimodal model, memory usage increases and the delay time until output is generated is longer in order to perform the processing by the encoder. Gemma 4 12B achieves memory saving and latency reduction by omitting the encoder.
The number of image encoder parameters was 550 million for the Gemma 4 31B and Gemma 4 26B A4B, and 150 million for the Gemma 4 E2B and Gemma 4 E4B. The Gemma 4 12B uses only an embedded module with 35 million parameters, without using an encoder.
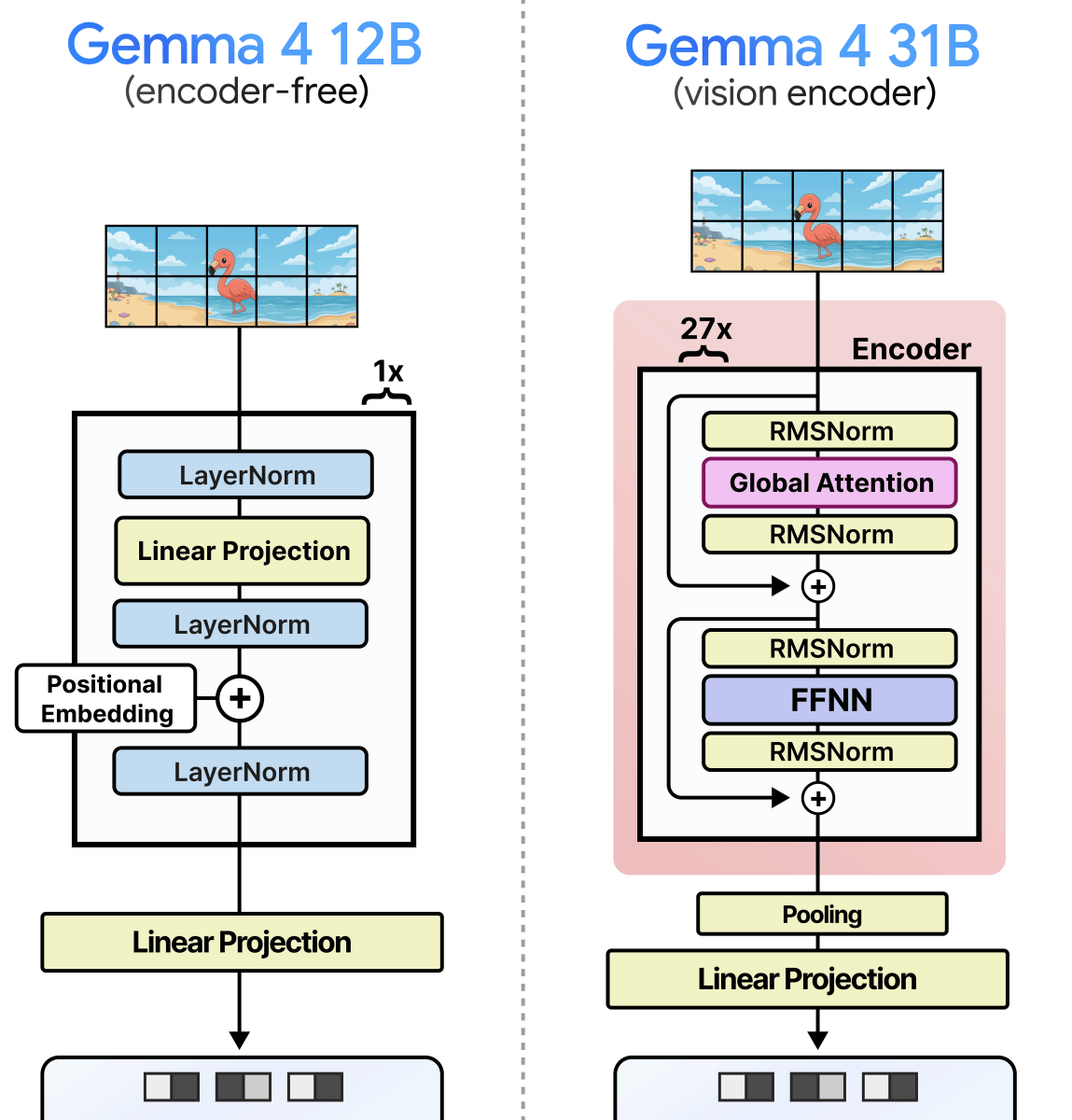
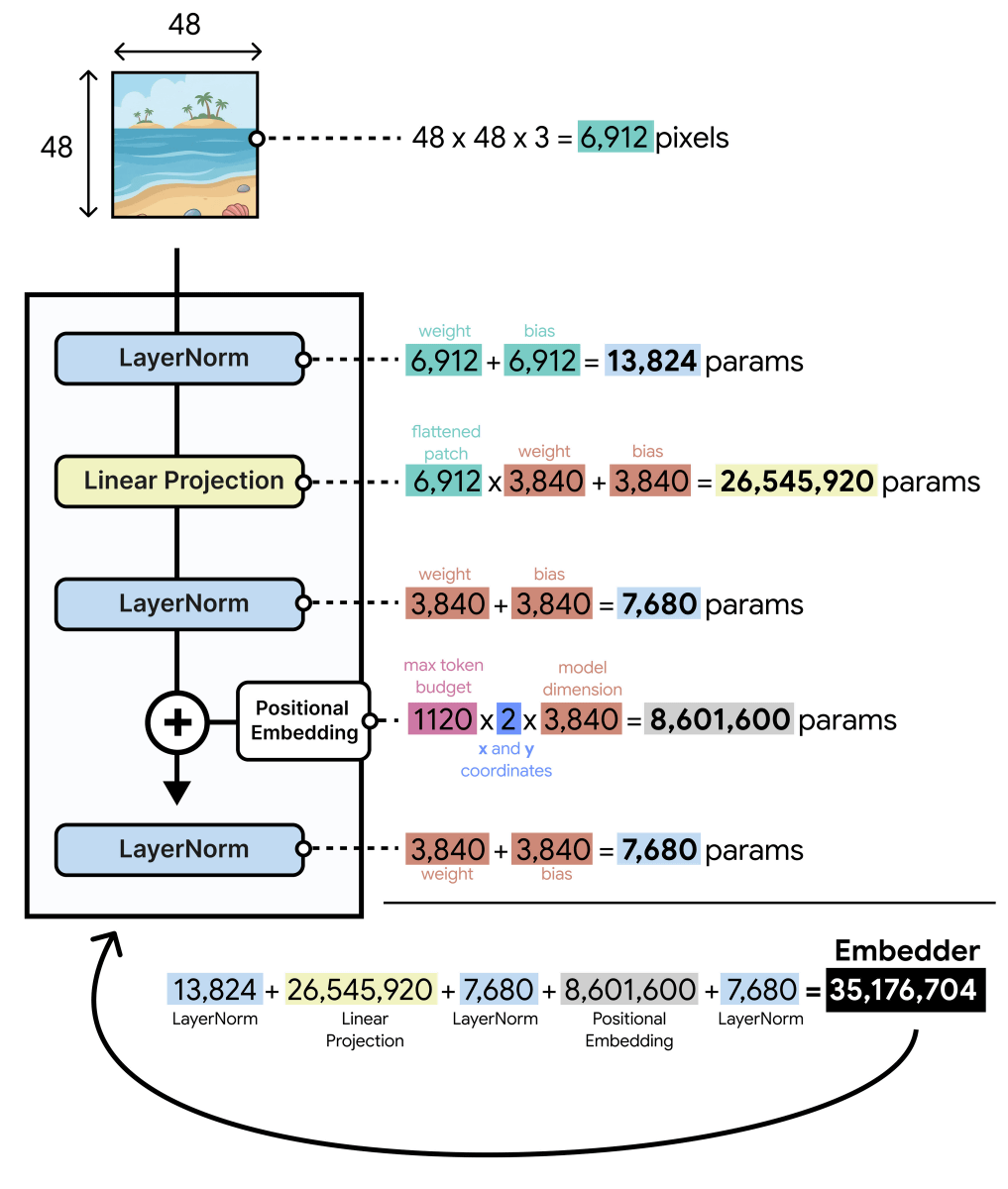
When you hear 'embedded module with 35 million parameters,' you might imagine it's 'an encoder miniaturized to 35 million parameters,' but in reality, it's a mechanism that only functions as a data conversion path, 'dividing an image into 48x48 pixel sections and converting them into an embedded format,' and is completely different from an encoder. Mr. Grutendorf explains that 'the reason the number of parameters has ballooned to 35 million is simply because there are a large number of pixels to project onto the LLM.' Gemma 4 12B divides an image into 48x48 pixel patches for processing, and each patch needs to be projected onto Gemma 4 12B's 3840 dimensions, meaning that projection alone requires 48 (vertical) x 48 (horizontal) x 3 (RGB) x 3840 = 26,542,080 parameters.
While images require an embedded module, audio is much simpler: the audio is divided into 40-millisecond segments, the pitch is tokenized, and then processed directly by the LLM. According to Mr. Grutendorf, 'Audio is inherently a two-dimensional sequence and can be processed by the LLM just like text.'
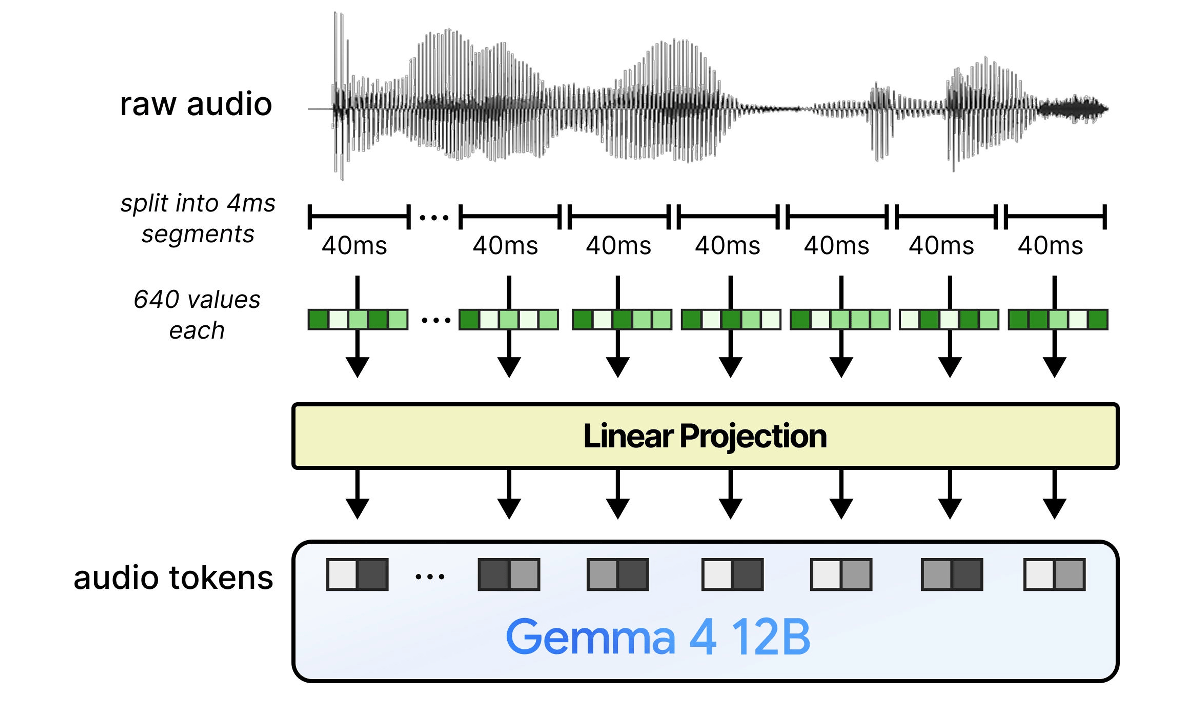
The Gemma 4 E2B and Gemma 4 E4B had a built-in audio encoder with 305 million parameters to process audio. In the Gemma 4 12B, the audio encoder is no longer needed, which reduces memory usage.
Related Posts:




in AI, Posted by log1o_hf