This article explains how a 10-year-old Xeon server can run the latest AI smoothly, achieving practical speeds even without a GPU.

AI services like ChatGPT run on ultra-high-performance AI servers, leading many to believe that running local AI on a home or local server requires a state-of-the-art PC with a high-performance GPU and large memory capacity. However, reports have emerged of running a 26B-scale local AI at a practical speed on an older server from around 2016 with an Intel Xeon processor, 128GB of DDR3 memory, and no GPU.
A 10 year old Xeon is all you need - point.free

The report was made by cafkafk, an open-source developer and member of the NixOS Steering Committee. The machine used had an Intel Xeon E5-2620 v4 processor, 8 cores and 16 threads, AVX2 support, AVX-512 support, 20 MiB L3 cache, 128GB of DDR3 memory, and no GPU. The Intel Xeon E5-2620 v4 was released in the first quarter of 2016.
The biggest factor determining the speed of local AI is not just the CPU's computing power. Every time a large-scale language model generates a 'token' corresponding to the next word, it needs to load a huge amount of numerical data called the model's 'weights' from memory into the CPU. To elaborate, weights are like the core of the knowledge that the AI has gained through learning, and during inference, this enormous amount of weights is loaded many times.
Therefore, when running local AI on an older Xeon, the enemy is not only 'slow computation' but also 'limited memory bandwidth.' DDR3 memory is slower than newer DDR5 memory or the high-speed memory found in GPUs, and even after the CPU finishes a calculation, it has to wait for the next data to arrive from memory. In AI inference, the processor spends a significant amount of time waiting for weights to be delivered from memory rather than actually performing calculations at full power.
The approach taken by cafkafk was not to brute-force the old hardware, but to thoroughly fine-tune the settings of the inference engine. While general local AI execution tools are easy to use, they sometimes don't allow for sufficient modification of internal optimization settings. Therefore, cafkafk used ik_llama.cpp, a derivative of the llama.cpp family. The 'magic spell' to actually get it working is as follows:
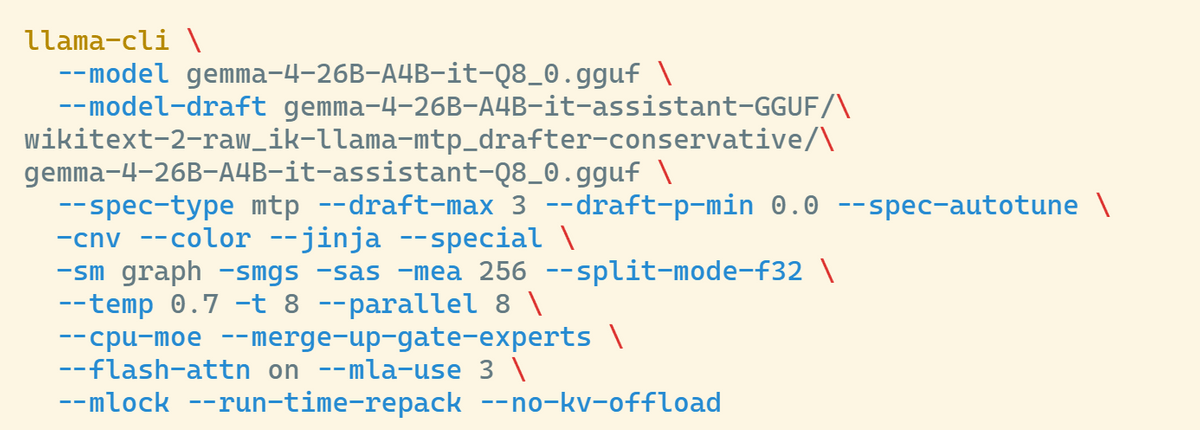
One of the key innovations is the following option, which specifies the use of 'speculative decoding.' Speculative decoding is a mechanism that speeds up processing by having a small draft model predict some tokens first, and then a larger validation model confirm the predictions. Rather than running the large model heavily from the beginning every time, it is possible to reduce the burden of memory reads by delegating part of the work to a small draft model.

With older CPUs, memory bandwidth tends to reach its limit before computing power, making speculative decoding more effective. The idea is to run a small draft model using the CPU's available computing resources, reducing the number of times the weights of the large verification model are repeatedly retrieved from memory. It's not about brute-forcing it with the GPU, but rather about minimizing congestion on the narrow path of memory bandwidth.
The model used was
However, when running MoE on a CPU, the choice of expert is also important. If experts switch frequently, the data stored in the CPU cache quickly becomes unnecessary, forcing the system to reload data from the slower main memory. To run AI quickly on older servers, it's necessary to reuse cached data for as long as possible.
Therefore, cafkafk uses '--cpu-moe' to adjust MoE's behavior for the CPU, and '--merge-up-gate-experts' to consolidate calculations within experts. The aim is to reduce round trips to DDR3 memory by consolidating calculations and memory accesses that would normally be split into multiple steps. This is less about speeding up local AI and more about meticulous traffic management to reduce memory movement.

Setting the number of threads is also important. The machine used has 8 cores and 16 threads, but cafkafk uses '-t 8' to match the number of physical cores. It might seem that using all 16 threads via SMT would speed things up, but when memory bandwidth is congested, increasing the number of threads will not speed up weight reading. Rather, it increases the scheduling burden and makes it difficult to improve speed.
The '--mlock' option is also an important setting. In Linux, when memory is insufficient, swapping occurs, moving unused data to storage. If the weights of the AI model are moved to swap, the system will have to reload the massive weights from storage, not just DDR3, causing a sharp drop in generation speed. --mlock locks the model to physical memory, preventing the slowdown caused by swapping. However, if the memlock limit on the Linux side is too small, the setting will fail, and you will also need to change the limit on the OS side.

Furthermore, the '--run-time-repack' option is used to rearrange the weights in memory in a way that is easier for the CPU to read. Model weights are not just a huge table of numbers; there are arrangements that are easier for the CPU to read and arrangements that are more difficult. By taking the time to arrange the weights at startup, the memory readout process when actually generating text becomes more efficient.
The handling of the KV cache is also something that cannot be overlooked in CPU-only configurations. The KV cache is like a short-term memory that holds the context of a conversation, and it becomes larger the longer the text or conversation is handled. In environments with a GPU, the KV cache may be offloaded to the GPU, but in configurations without a GPU, there is no GPU to offload to. cafkafk specifies that the KV cache should not be offloaded to the GPU using '--no-kv-offload'.
The attention processing, which calculates the relationships between input tokens, is also sped up. As the text lengthens, the number of possible relationships increases, and processing them normally would require writing a huge matrix to memory. Flash Attention reduces memory consumption and memory bandwidth burden by performing calculations in small units instead of storing the entire huge matrix in memory.
The options '--flash-attn on' and '--mla-use 3' are also used. MLA stands for Multi-Head Latent Attention, and it's a mechanism that compresses the KV cache. Instead of storing short-term conversational memories as they are, it reduces memory usage when dealing with large contexts by condensing them into smaller representations.
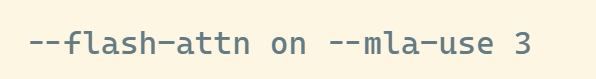
On the other hand, not all settings work as expected. The post mentions settings such as '-sm graph' related to splitting the computation graph, but explains that graph splitting is not supported in Gemma 4's external MTP configuration and automatically switches to layer splitting. cafkafk says this 'may be useful in the future.'

The actual memory usage is also quite large. According to cafkafk, for a context length of 262K tokens, the required memory for the model's weights and cache combined is approximately 82GB. This is broken down as follows: weights account for about 25GB and KV cache for about 56GB, with the KV cache being larger than the model itself. This configuration is only possible because of the 128GB of DDR3 memory available.
Thus, cafkafk succeeded in generating tokens at 'reading speed.' He states, 'The bottleneck when running cutting-edge AI in a local environment is not simply the silicon itself. You need a deep understanding of how the inference engine actually works.'
Additionally, cafkafk appeared on the engineer-focused news sharing site ' Hacker News ' and answered questions.
When asked what 'reading speed' specifically translates to in terms of tokens per second, cafkafk stated that he ran a simple benchmark with the server handling other tasks, and the generation speed was 11.94 tokens per second. He also mentioned that it could exceed 20 tokens per second under no load, but this was based on intuition rather than a rigorous benchmark. He explained that since a reading speed of 250 words per minute is roughly equivalent to 5-6 tokens per second, even 11.94 tokens per second under load is still considered a 'reading speed.'
Related Posts:







