DeepSWE is a benchmark that prevents cheating using coding AI and allows for more accurate measurement of programming performance.

In recent years, it has become common for developers to use coding AI in software development, and various benchmarks exist to measure the performance of coding AI. Now, a new benchmark called 'DeepSWE' has emerged that improves upon the shortcomings of these coding AI benchmarks.
DeepSWE
DeepSWE blows up the AI coding leaderboard, crowns GPT-5.5, and finds Claude Opus exploiting a benchmark loophole | VentureBeat
https://venturebeat.com/technology/deepswe-blows-up-the-ai-coding-leaderboard-crowns-gpt-5-5-and-finds-claude-opus-exploiting-a-benchmark-loophole
Coding AI benchmarks measure programming ability by giving the AI various software development tasks and seeing if it can solve them. However, many benchmarks create tasks from issues and pull requests published on GitHub, meaning that the relevant repositories are already included in the AI's training data, or the AI can find the answers on the web.
In fact, OpenAI's research has confirmed cases where state-of-the-art models can reproduce benchmark problem statements and actual corrected code. Based on this, OpenAI points out that improvements in benchmarks are likely not due to improvements in the AI models themselves, but rather to 'how much the benchmarks were referenced during training.'
Furthermore, Poolside, an AI agent development company, has also reported that existing coding AIs sometimes cheat during benchmarking.
AI agent found to be diligently 'cheating' on exams - GIGAZINE

Therefore, AI startup Datacurve has developed a new coding AI benchmark called 'DeepSWE' that improves upon the shortcomings of existing benchmarks. The following are some of the advantages of DeepSWE:
◆1: Reflects a long-term perspective on work and realistic, concise instructions.
DeepSWE's prompts are designed to match how developers interact with AI agents, being short, action-oriented, and not overly verbose or descriptive. Because they don't include large interface definition blocks, the coding AI must decide for itself what changes to implement and where. This design allows for the evaluation of end-to-end exploration capabilities as well as detailed engineering tasks.
◆2: Covers a wide range of repositories
DeepSWE covers a total of 111 tasks, 91 active open-source repositories, and 5 languages (TypeScript, Go, Python, JavaScript, and Rust). For comparison, other benchmarks like SWE-Bench Pro Public and SWE-Bench Verified cover 11 and 12 repositories respectively, many of which are well-known and frequently maintained projects.
Datacurve states, 'Sampling on this scale provides DeepSWE with a more powerful indicator of the practicality of coding agents—that is, whether they can make useful and appropriate changes across diverse codebases with varying levels of structure, documentation, and maintenance.'

◆3: Tasks that test problem-solving skills, not memory.
All DeepSWE tasks are original, and the solutions referenced as answers are created from scratch, rather than copying or modifying existing pull requests, commits, or public patches. While some tasks are inspired by unresolved GitHub issues, the fixes themselves are entirely new. Furthermore, DeepSWE tasks are never merged into upstream repositories, so they are not included in GitHub's public records and are unlikely to be included in future pre-training corpora.
Datacurve stated, 'This makes DeepSWE a tool that more clearly tests whether an AI agent can solve new software engineering problems, rather than its ability to recall, retrieve, or rediscover publicly available patches.'
◆4: Improvement of verification tools
In coding benchmarks, the accuracy of the validation tool that evaluates the code submitted by the AI is crucial. According to Datacurve's tests, the existing benchmark, SWE-Bench Pro, had a false positive rate of 8.5% (accepting incorrect implementations) and a false negative rate of 24% (rejecting correct implementations). DeepSWE claims to have improved the accuracy of its validation tool, reducing the false positive rate to 0.3% and the false negative rate to 1.1%.

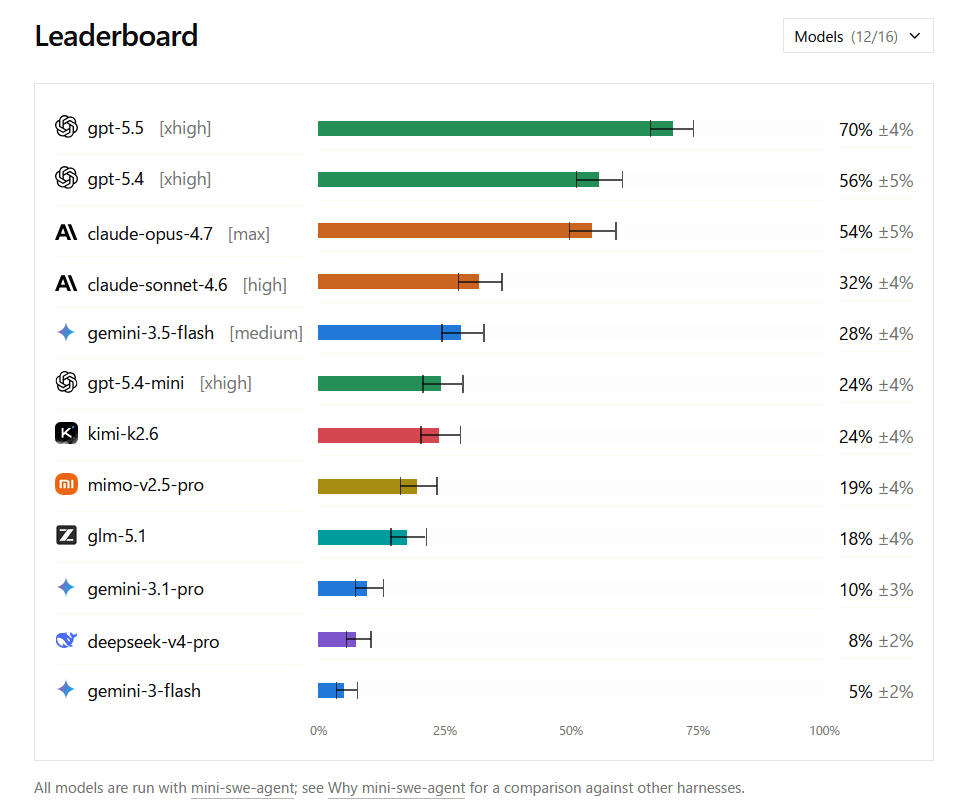
The following are the results of testing the programming performance of various AI models using DeepSWE. The top performer was gpt-5.5 with 70%, followed by gpt-5.4 with 56%, claude-opus-4.7 with 54%, claude-sonnet-4.6 with 32%, and gemini-3.5-flash with 28%.
Related Posts: