OpenAI releases AI benchmark 'SWE-Lancer' to measure whether a machine can perform tasks that would cost a freelance engineer $1 million

On February 18, 2025, OpenAI released SWE-Lancer , an open source benchmark for evaluating the coding performance of AI models.
[2502.12115] SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?
Introducing the SWE-Lancer benchmark | OpenAI
https://openai.com/index/swe-lancer/

Today we're launching SWE-Lancer—a new, more realistic benchmark to evaluate the coding performance of AI models. SWE-Lancer includes over 1,400 freelance software engineering tasks from Upwork, valued at $1 million USD total in real-world payouts.
https://t.co/c3pFcL41uK — OpenAI (@OpenAI) February 18, 2025
SWE-Lancer is a benchmark tool that measures whether an AI can perform tasks that freelance software engineers would receive for a total of about $1 million (about 150 million yen). It can test both independent engineering tasks, ranging from fixing a bug worth $50 (about 7,500 yen) to implementing a feature worth $32,000 (about 4.8 million yen), and management tasks in which the model selects technical implementation plans.
SWE-Lancer tasks span the full engineering stack, from UI/UX to systems design, and include a range of task types, from $50 bug fixes to $32,000 feature implementations. SWE-Lancer includes both independent engineering tasks and management tasks, where models choose between… pic.twitter.com/3Dg8bjHOSk
— OpenAI (@OpenAI) February 18, 2025
Task prices measured by SWE-Lancer reflect actual market value, and the more difficult the task, the higher the price.
SWE-Lancer task prices reflect real-world market value. Harder tasks demand higher payments. pic.twitter.com/0FGWm88RE8
— OpenAI (@OpenAI) February 18, 2025
OpenAI reports that 'When we measured the performance of AI models using SWE-Lancer, we found that current AI models are still unable to solve the majority of tasks.' In fact, a paper published by OpenAI showed that for a task worth $1 million, GPT-4o, o1, and Claude 3.5 Sonnet were able to complete tasks worth about $300,000 (about 45 million yen) to $400,000 (about 60 million yen).
Current frontier models are unable to solve the majority of tasks. pic.twitter.com/GP3C3UR3cB
— OpenAI (@OpenAI) February 18, 2025
'By mapping model performance to monetary value, we hope that SWE-Lancer will enable more research into the economic impact of AI model development,' OpenAI said.
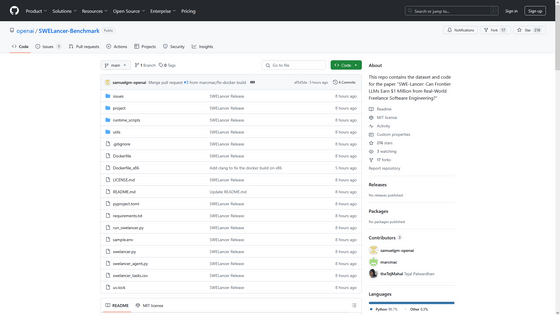
OpenAI has also open-sourced SWE-Lancer to facilitate future research. The SWE-Lancer source code can be found on GitHub.
GitHub - openai/SWELancer-Benchmark: This repo contains the dataset and code for the paper 'SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?'
https://github.com/openai/SWELancer-Benchmark
Related Posts: