A new spreading language model, 'ZAYA1-8B-Diffusion-Preview,' developed with an AMD AI chip, has emerged, transforming autoregressive models into spreading models.

AI startup
ZAYA1-8B-Diffusion-Preview: Efficient Parallel Decoding on AMD
https://www.zyphra.com/post/zaya1-8b-diffusion-preview
We present ZAYA1-8B-Diffusion-Preview, the first diffusion language model trained on @AMD .
— Zyphra (@ZyphraAI) May 14, 2026
Autoregressive LLMs generate one token at a time; diffusion generates a block in parallel, speeding up inference.
We show a 4.6-7.7x decoding speedup with minimal quality degradation 🧵 pic.twitter.com/xMXp4sFYkb
Zyphra has released 'ZAYA1-8B-Diffusion-Preview,' an early preview of its research findings on diffusion language models. Zyphra is a company working on AI development using AMD's GPU infrastructure, and on May 6, 2026, it announced its inference language model 'ZAYA1-8B.' Like most existing language models, ZAYA1-8B is an autoregressive model.
'ZAYA1-8B,' a large-scale AI approaching the capabilities of large-scale AIs with approximately 700 million parameters, has emerged. Trained in an AMD environment, it achieves performance comparable to large-scale models in mathematical and code inference - GIGAZINE

'ZAYA1-8B-Diffusion-Preview' is a conversion of the autoregressive model ZAYA1-8B into a discrete diffusion model while maintaining evaluation performance. 'ZAYA1-8B-Diffusion-Preview' is the first MoE diffusion model converted from an autoregressive large-scale language model (LLM), and also the first diffusion language model trained on an AMD GPU.
The autoregressive model decodes tokens one by one in sequence. For each token, the autoregressive model employs an attention mechanism that 'checks all past tokens and uses the results of past calculations (KV cache) to generate a new token.' This presents a problem in that decoding in the autoregressive model is constrained by memory bandwidth.
In contrast, the diffusion model can overcome the bottleneck of 'memory bandwidth constraints.' The diffusion model repeats the process of 'generating multiple drafts simultaneously for N tokens' multiple times. Because the diffusion model can generate N tokens at once as part of a single sequence using the same KV cache, the entire operation becomes computationally intensive rather than memory bandwidth-dependent, maximizing GPU utilization and dramatically speeding up inference compared to autoregressive models.
Since training a diffusion model from scratch is difficult, Zyphra proposed a method of 'converting an existing pre-trained autoregressive model into a diffusion model.' This method gave rise to 'ZAYA1.8B-Diffusion-Preview.'
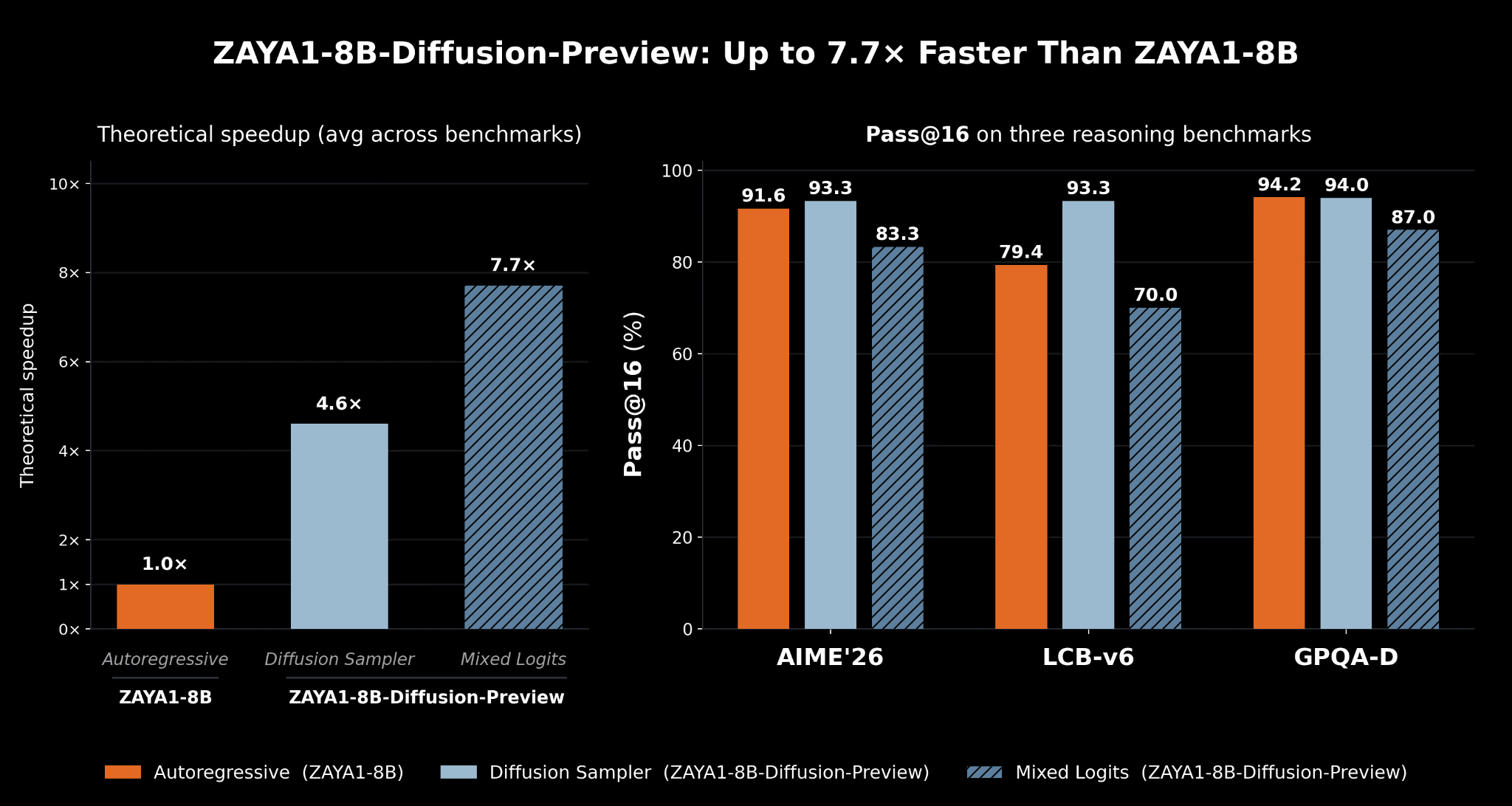
The graph on the right below compares the theoretical speedup in autoregressive decoding between the diffusion model 'ZAYA1.8B-Diffusion-Preview' and the base autoregressive model ZAYA1-8B. 'ZAYA1.8B-Diffusion-Preview' achieves a 4.6x speedup with the standard diffusion sampler and a 7.7x speedup with the mixed logit sampler. The graph on the left summarizes the results of evaluating Pass@16, which assesses the code generation and mathematical reasoning capabilities of LLMs, across multiple benchmarks. No degradation in systematic evaluation due to the diffusion transform is observed with the standard diffusion sampler. Regarding the mixed logit sampler, Zyphra explained that 'while there is some degradation (compared to ZAYA1-8B), a significant speed improvement is expected, resulting in a trade-off between quality and performance that can be selected at runtime.'
Related Posts:







in AI, Posted by logu_ii