Summary of typical mistakes that are often made when conducting A/B testing

On the official blog of
A/B testing mistakes I learned the hard way
https://newsletter.posthog.com/p/ab-testing-mistakes-i-learned-the
Neuner said he has run hundreds of A/B tests while working at Meta and in personal projects. He listed six typical mistakes that he learned the hard way from hundreds of experiences.
◆1: The hypothesis to be tested is unclear
When conducting testing, the hypothesis should be clear about 'what to test' and 'why to test'. If the hypothesis is unclear, not only will you waste time, but you may unknowingly make changes that damage the product.
As an example of a bad hypothesis, Neuner introduced the hypothesis that 'changing the color of the 'Proceed to Checkout' button will increase purchases.' In this hypothesis, it is unclear why you expect this change to increase purchases, and it is unclear whether you should measure only the number of button clicks or what other indicators you should look at.
On the other hand, a good hypothesis is something like, 'User research has shown that users don't know how to proceed to the purchase page. If you change the color of the button, more users will notice and proceed to the purchase page. This will lead to more purchases.' If you follow this hypothesis, you can see that you just need to check the number of button clicks and the number of purchases.
To avoid this mistake, make sure your hypothesis answers three questions: 'Why are you running the test?', 'What changes are you testing?', and 'What is expected to happen?'
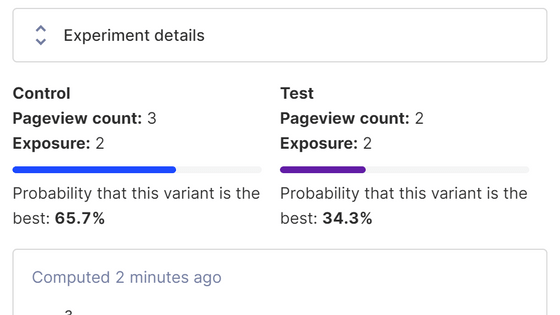
◆2: Show only the overall results
For example, suppose you run an A/B test on all users and get the following results: Looking at the results alone, it looks like the modified 'Test' version doubled the conversion rate.
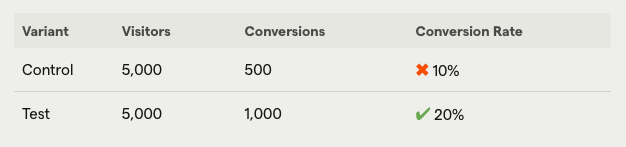
However, when we look at the results by device type, we see that on desktop devices, not changing the settings resulted in a higher conversion rate.

Because there is a possibility of '
◆ 3: Include unaffected users in the experiment
Including users who don't have access to the feature you're testing, or who have already achieved your objective, can skew the results, changing your conclusions or extending the duration of the experiment.
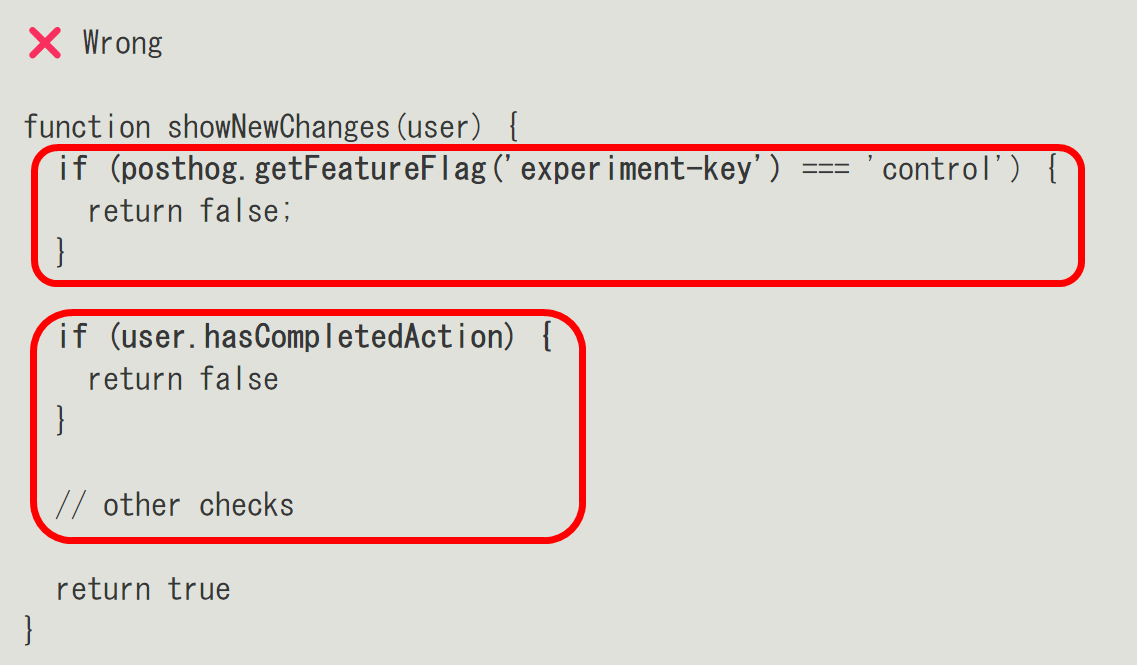
For example, if you get the A/B testing tool's flag before checking whether the user should participate in the experiment, as shown below, the flag assigned by the tool will differ from the actual user display.
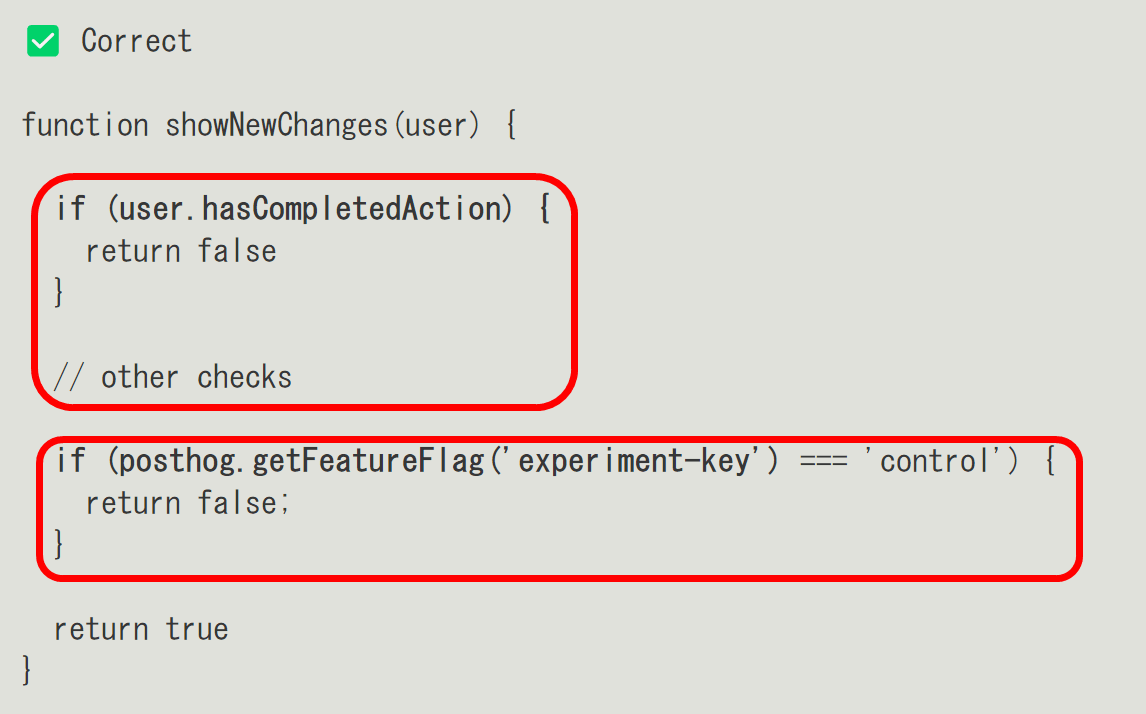
To ensure proper results, the A/B testing tool flag should be pulled after other checks.
4. Finish the test quickly
Neuner calls this mistake the 'peek problem,' which is when you look at the results of a test before the test is complete and make a decision based on incomplete data. Even if the early results show up as statistically significant, you don't know if the final results will be statistically significant.
When conducting A/B testing, you should calculate the required period in advance and follow that period. Some tools will automatically calculate the required period for you.
◆5: Run an experiment on the entire population right away
If you run an experiment on all users from the beginning in order to get results quickly, you may not be able to run the experiment if there is a bug. For example, if you start an A/B test on all users and then realize that a change you made crashes the app and makes it impossible to get correct results, you will not be able to run the A/B test again even if you fix it because many users have already seen the change.
It is a good idea to start with an experiment with a small number of users and gradually increase the number of users participating as you verify that the app is working properly using various data.

◆6: Ignore counter metrics
A counter metric is a metric that may be indirectly affected by an experiment. For example, if you are testing a change to your account registration page, a counter metric could be the number of active users. If your registration rate increases but the number of active users remains the same, it could be that your change to the page is misleading users about the app's functionality, which is why your dropoff rate is also increasing.
By setting and tracking indicators to check the health of the product, such as 'user retention rate,' 'session duration,' and 'number of active users,' you can ensure that there are no unexpected side effects that adversely affect the changes. In addition, 'hold-out testing,' in which a small number of users continue to see the version before the change even after the experiment is over, is also effective in examining the long-term effects.
'Running A/B tests is powerful because it allows you to verify that changes change your product for the better, but it's also scary because there are so many ways to screw up the test,' Neuner said, stressing the importance of doing A/B tests correctly.
Related Posts:




in Software, , Posted by log1d_ts