Introducing the multimodal model 'Llama 3-V,' which is 1/100th the size of GPT4-V but boasts the same performance, and the training cost is only 80,000 yen

The open source model ' Llama 3-V ' capable of image recognition has been released. Llama 3-V is significantly smaller than OpenAI's multimodal model 'GPT4-V' and costs about $500 (about 78,000 yen) to pre-train, yet shows comparable performance in most metrics.
Llama 3-V: Matching GPT4-V with a 100x smaller model and 500 dollars | by Aksh Garg | May, 2024 | Medium
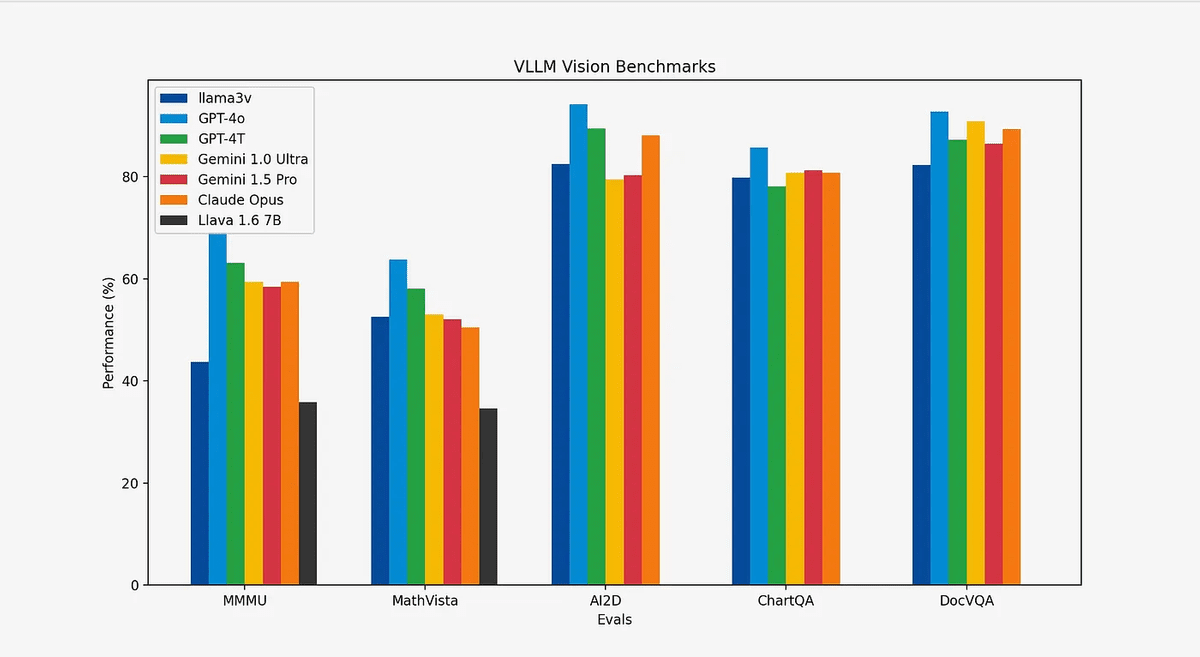
The newly announced Llama 3-V is a model based on the language model 'Llama3 8B' released by Meta. Benchmarks have shown that it delivers 10-20% better performance than the popular multimodal model Llava, and that in all indicators except MMMU , it has performance comparable to competing closed-source models that are more than 100 times larger.
Llama 3-V is an open source model available on Hugging Face and GitHub.
mustafaaljadery/llama3v at main
GitHub - mustafaaljadery/llama3v: A SOTA vision model built on top of llama3 8B.
https://github.com/mustafaaljadery/llama3v
You can also try it out with Hugging Face.
LLaVA++ (LLaMA-3-V) - a Hugging Face Space by MBZUAI
https://huggingface.co/spaces/MBZUAI/LLaMA-3-V
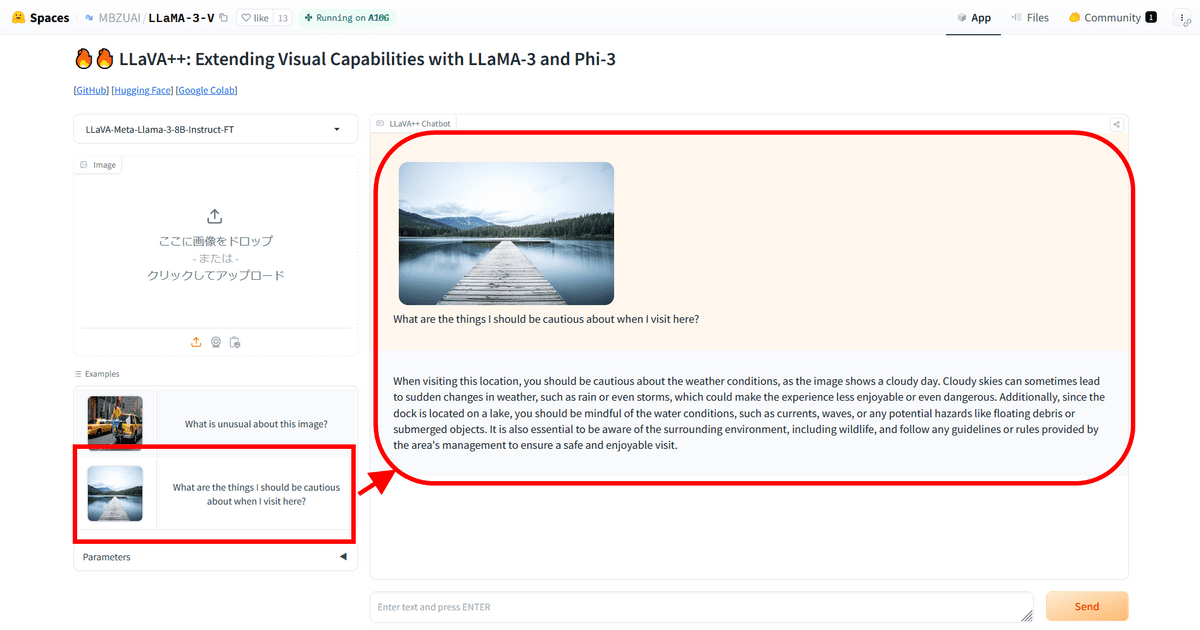
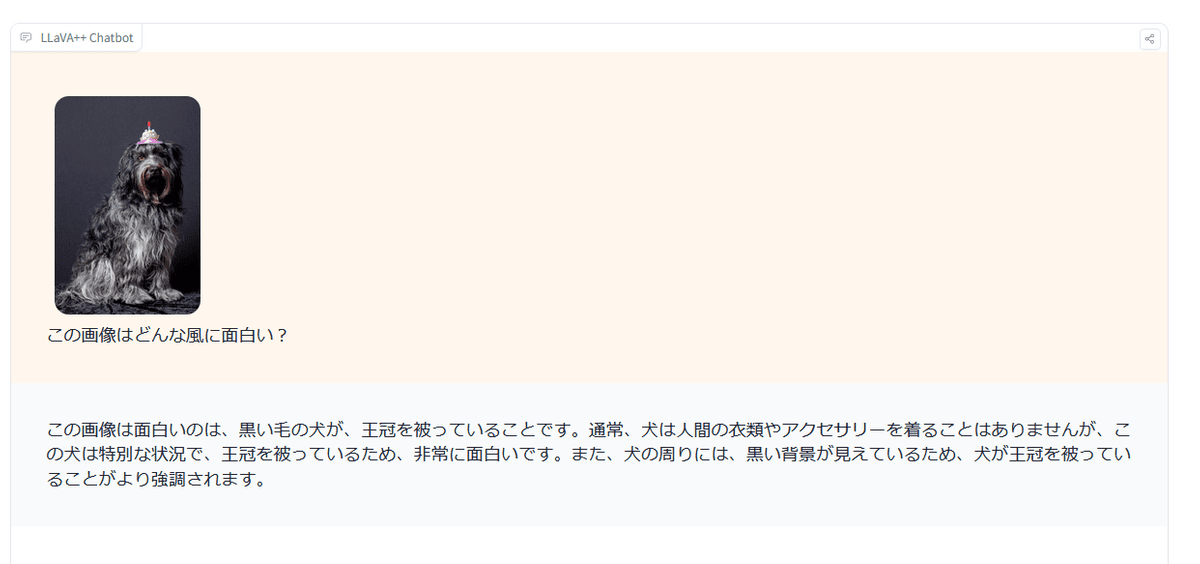
First, we clicked on a sample. In response to the question, 'What should you be careful of when visiting this location?' which was based on an image of a waterfront, the answer was, 'It's cloudy today, so it may suddenly rain or develop a storm. In addition, the boat dock is on a lake, so you should be aware of water conditions, such as floating debris and potential hazards at the bottom of the water. You should also be mindful of the surrounding environment, including wildlife, and follow any rules and guidelines set out by the area's managers to have a safe and enjoyable visit.'
Since I have the opportunity, I will upload an image that I have prepared myself.
Next, I typed in a sentence asking what was interesting about the image and clicked 'Send.'
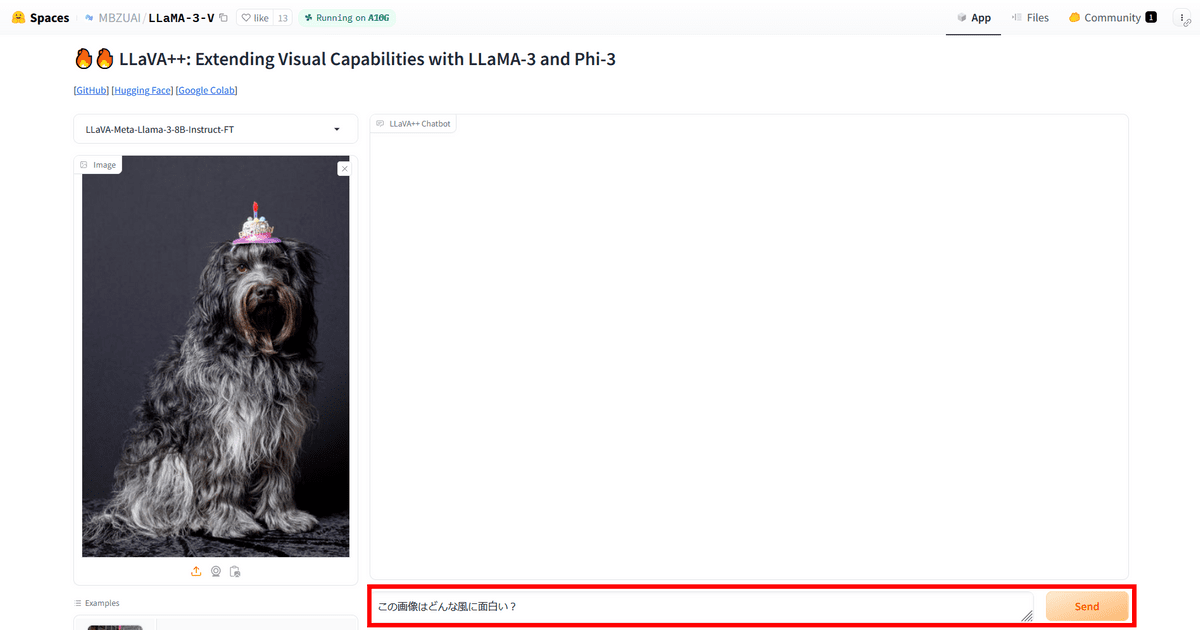
'It's funny that the dog is wearing a crown,' he replied.
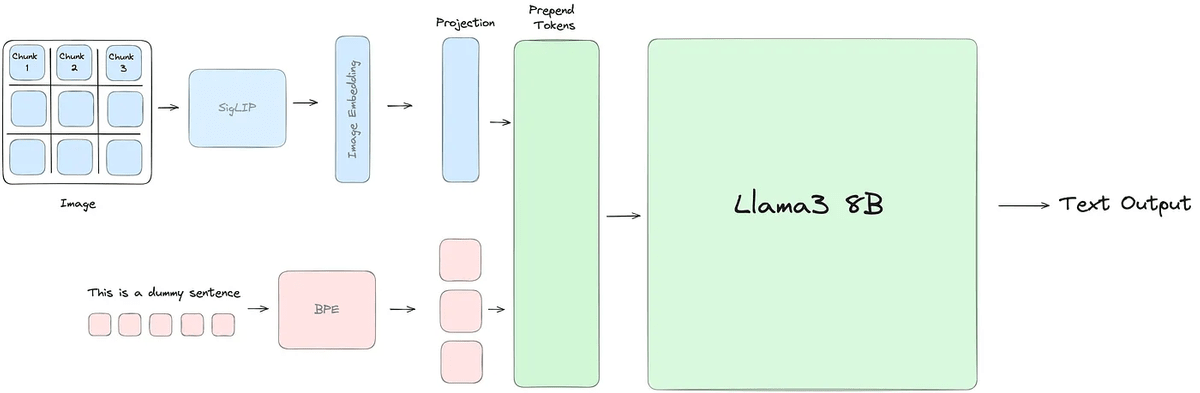
According to Aksh Garg, who released Llama 3-V, this model works by first passing the image to the visual model SigLIP, which analyzes the relationship between the image and the text, and then passing it to Llama 3.
Garg said, 'Llama 3 took the world by storm, beating GPT-3.5 in most benchmarks and GPT-4 in some. Then GPT-4o came along and reclaimed the throne in multimodal accuracy, but Llama 3-V is a model that turns it upside down. It's the first multimodal model built on Llama 3, and it costs less than $500 to train.'
Related Posts:






in Software, Posted by log1l_ks