OpenAI co-founder publishes report on reproducing 'GPT-2' in just 90 minutes and at a cost of 3,100 yen

A report has been published on the creation of OpenAI's 'GPT-2,' which became a
Reproducing GPT-2 (124M) in llm.c in 90 minutes for $20 · karpathy/llm.c · Discussion #481 · GitHub
https://github.com/karpathy/llm.c/discussions/481
# Reproduce GPT-2 (124M) in llm.c in 90 minutes for $20 ✨
— Andrej Karpathy (@karpathy) May 28, 2024
The GPT-2 (124M) is the smallest model in the GPT-2 series released by OpenAI in 2019, and is actually quite accessible today, even for the GPU poor. For example, with llm.c you can now reproduce this model on one 8X… pic.twitter.com/C9GdaxGPhd
The person who reproduced GPT-2 this time was Andrej Karpathy, co-founder of OpenAI. Karpathy explains that he chose GPT-2 because it is the ancestor of large-scale language models (LLMs) and because, despite being a 2019 model, the basic mechanism itself is almost the same as GPT-3 and other models.
The first thing needed to create AI is a GPU, and Karpathy chose Lambda , a service that provides GPUs for AI in the cloud.
According to Karpathy, the configuration often used in such cases is Linux x86 64bit Ubuntu 22.04 with CUDA 12 installed as a library. In this environment, Karpathy used the following startup command. It's long, but in summary it means 'Train 12-layer GPT-2 (124M) from scratch using the FineWeb dataset with 1 billion tokens and a maximum sequence length of 1024 tokens.'
# install miniconda
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
source ~/.bashrc
# pytorch nightly (optional) https://pytorch.org/get-started/locally/
# conda install --yes pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch-nightly -c nvidia
# pip installs so we can tokenize the FineWeb dataset
yes | pip install tqdm tiktoken requests datasets
# install cudnn so we can use FlashAttention and run fast (optional)
# https://developer.nvidia.com/cudnn-downloads
# for me, CUDA 12 (run `nvcc --version`) running on Linux x86_64 Ubuntu 22.04
wget https://developer.download.nvidia.com/compute/cudnn/9.1.1/local_installers/cudnn-local-repo-ubuntu2204-9.1.1_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2204-9.1.1_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2204-9.1.1/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn-cuda-12
# 'install' cudnn-frontend to ~/
git clone https://github.com/NVIDIA/cudnn-frontend.git
# install MPI (optional, if you intend to use multiple GPUs)
sudo apt install openmpi-bin openmpi-doc libopenmpi-dev
# tokenize the FineWeb dataset 10B tokens sample (takes ~1 hour, get lunch?)
# writes ~19GB of raw GPT-2 tokens to dev/data/fineweb10B
# and ~46GB in ~/.cache/huggingface/datasets/HuggingFaceFW___fineweb
git clone https://github.com/karpathy/llm.c.git
cd llm.c
python dev/data/fineweb.py --version 10B
# compile llm.c (mixed precision, with cuDNN flash-attention)
# First compilation takes ~1 minute, mostly due to cuDNN
make train_gpt2cu USE_CUDNN=1
# train on a single GPU
./train_gpt2cu \
-i 'dev/data/fineweb10B/fineweb_train_*.bin' \
-j 'dev/data/fineweb10B/fineweb_val_*.bin' \
-o log124M \
-e 'd12' \
-b 64 -t 1024 \
-d 524288 \
-r 1 \
-z 1 \
-c 0.1 \
-l 0.0006 \
-q 0.0 \
-u 700 \
-n 5000 \
-v 250 -s 20000 \
-h 1
# if you have multiple GPUs (eg 8), simply prepend the mpi command, eg:
# mpirun -np 8 ./train_gpt2cu \ ... (the rest of the args are the same)
As a result, the smallest model of GPT-2, GPT-2 124M, was created in about 90 minutes on 8X A100 80GB SXM nodes. Lambda offers this node for up to $14 per hour, so the total cost is about $20. It is possible to train with only one GPU, but the time required increases proportionally, so it will take 4 to 24 hours depending on the GPU.
The evaluation on the FineWeb validation dataset (left) and the accuracy of the benchmark HellaSwag (right) are as follows.
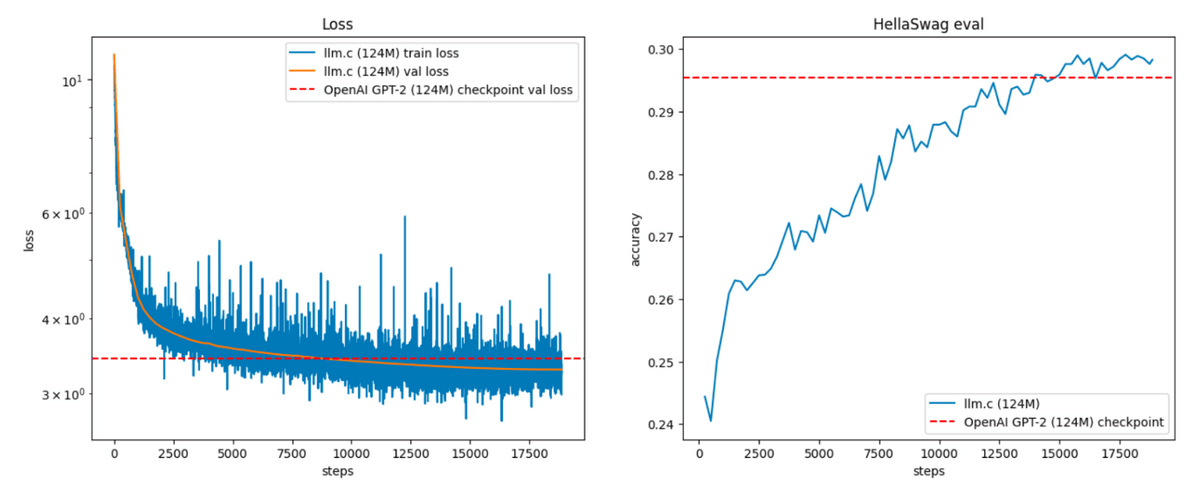
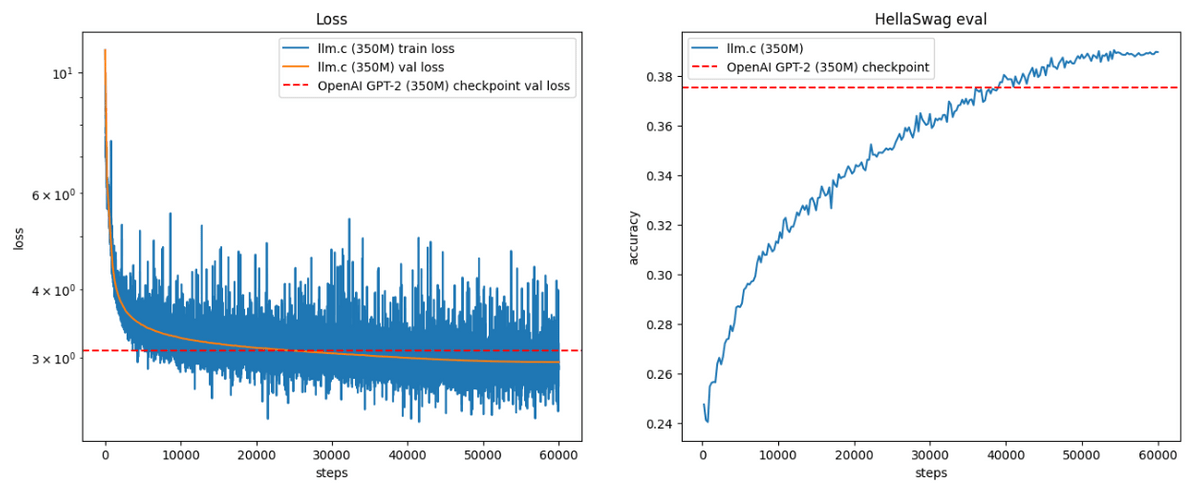
Karpathy also created GPT-2 350M, which took 14 hours to train and cost $200 (about 31,000 yen), 10 times more than GPT-2 124M.
In the future, Karpathy plans to increase the size of GPT-2 to 740M and 1558M, but it will cost a week and $2,500 (about 390,000 yen) to create a 1558M model with the aforementioned nodes. Therefore, Karpathy said, 'It's not impossible, but first I'll try to spend time refining the code, improving the tests, and making it possible to train on multiple nodes.'
Related Posts:








in Software, Posted by log1l_ks