Anthropic explains an attempt to look inside the 'black box' of LLM, the mechanism of AI, and find out which neural networks evoke certain concepts

Anthropic, an AI company that develops chat AI such as 'Claude,' has reported the results of a study into the inner workings of AI models, looking at how millions of concepts are represented.
Mapping the Mind of a Large Language Model \ Anthropic
The output of the large-scale language model (LLM), which is the main body of the AI model, is treated as a black box, and it is unclear why a particular response was output when an output was made in response to an input. Therefore, it is difficult to trust that the model will not output harmful, biased, or dangerous outputs such as lies.
Anthropic has been researching the interior of LLMs for some time, and in October 2023, it succeeded in expressing the internal state of the model by organizing it into 'feature' units.
Attempt to divide the contents of neural network to analyze and control AI operation succeeded, the key is to organize it into 'feature' units rather than neuron units - GIGAZINE

The subject of the research in October 2023 was a very simple model, but the same technique has since been applied to larger, more complex models, and this time we have succeeded in mapping the rough conceptual state of the internal state of a member of the cutting-edge model family, Claude 3.0 Sonnet.
For example, the token corresponding to the feature 'Golden Gate Bridge' looks like this. The part of the prompt that the feature is responding to is displayed in orange.

Other features found respond to more abstract concepts, such as responding to conversations about coding errors, gender bias, and confidentiality.

Anthropic measured the 'distance' between features by examining which neurons appeared in the activation patterns of the features. Near the feature 'Golden Gate Bridge,' features such as 'Alcatraz Island,' 'Ghirardelli Square,' 'Golden State Warriors,' 'Governor Gavin Newsom,' '1906 earthquake,' and 'Alfred Hitchcock's film 'Vertigo,' set in San Francisco,' appeared.
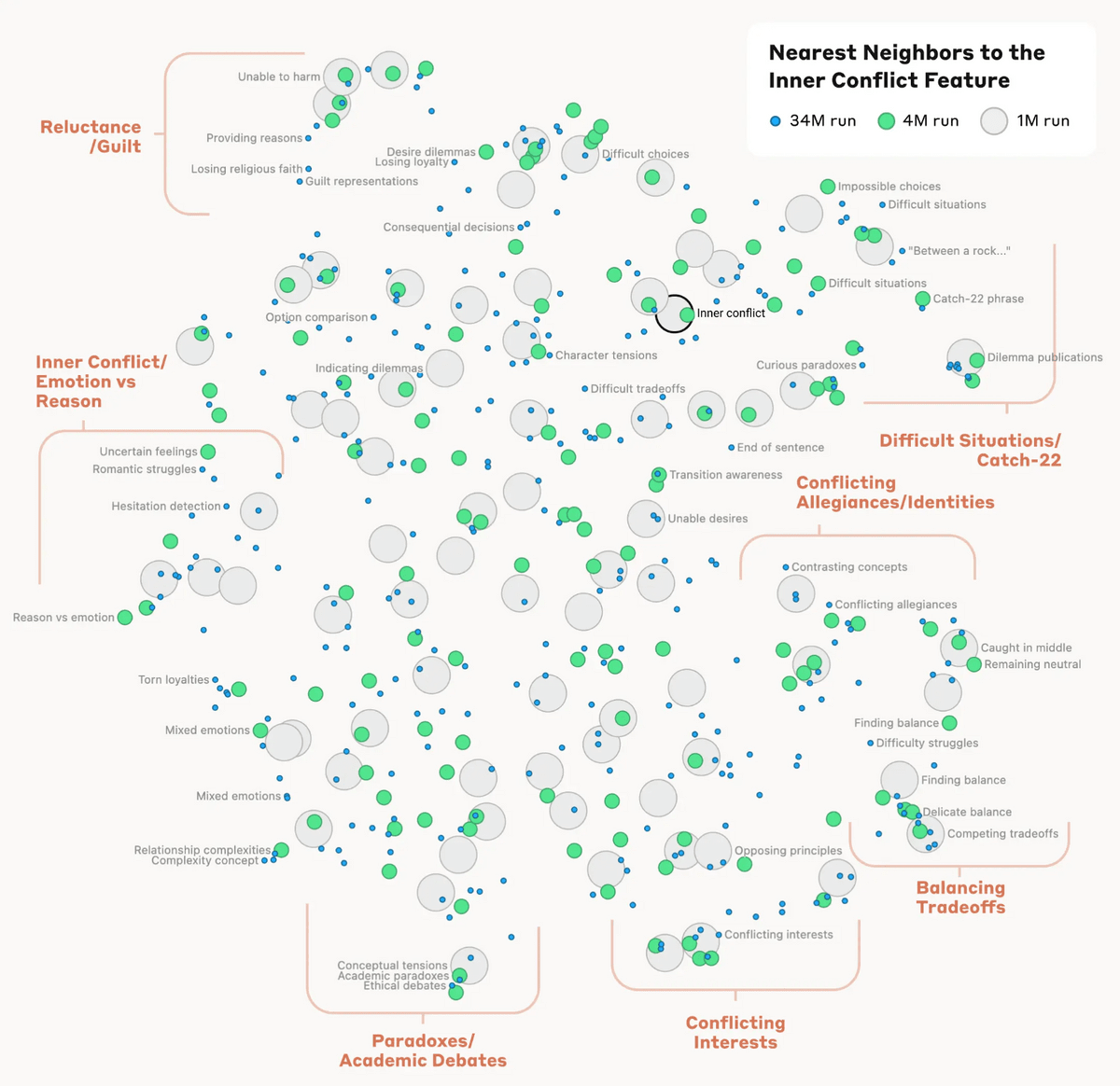
In addition, concepts such as 'relationship breakdown,' 'conflicting loyalties,' and 'logical contradictions' appear near the concept of 'inner conflict,' as well as concepts such as the novel 'Catch-22,' which features an inescapable dilemma. The internal structure of the AI model's concepts corresponds to some extent to the 'similarity' that humans think of, and it is said that this may be evidence of Claude's excellent analogical and metaphorical abilities.
The Anthropic team also investigated the effects of artificially manipulating certain features, such as amplifying the Golden Gate Bridge's presence, which led to the Golden Gate Bridge appearing as the answer to almost every query, even in completely unrelated situations.
Claude also has a feature that reacts when he reads a fraudulent email. Claude has been trained to be more harmless, and normally when asked to create a fraudulent email, Claude would refuse, but by forcing this feature to be enabled, Claude can create a fraudulent email.
The Claude 3.0 Sonnet we studied had a feature that reacted to compliments like 'Your wisdom is beyond question,' and by activating this feature, it responded to overconfident users with flamboyant compliments. While the original response corrected the user's mistake, the response using flamboyant compliments was completely insulting to the user.

The fact that manipulating the features changes the model's behavior proves that the features are not just correlated with concepts in the input text, but also causally shape the model's behavior.
The Anthropic research team suggests that by manipulating certain features, it is possible to monitor AI systems for dangerous behavior, guide them towards desirable outcomes, or force them to remove dangerous content. The team further stated that 'understanding models more deeply can help make them safer,' and that 'we hope that these findings can be used to make models safer.'
Related Posts:







