A research team preparing for the birth of OpenAI's 'superintelligence' explains in detail how a weak AI model like GPT-2 can control a powerful AI like GPT-4

OpenAI, which is known for developing chat AI 'ChatGPT' and others,
WEAK-TO-STRONG GENERALIZATION: ELICITING STRONG CAPABILITIES WITH WEAK SUPERVISION
(PDF file) https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
Weak-to-strong generalization
https://openai.com/research/weak-to-strong-generalization
OpenAI thinks superhuman AI is coming — and wants to build tools to control it | TechCrunch
OpenAI Demos a Control Method for Superintelligent AI - IEEE Spectrum
https://spectrum.ieee.org/openai-alignment
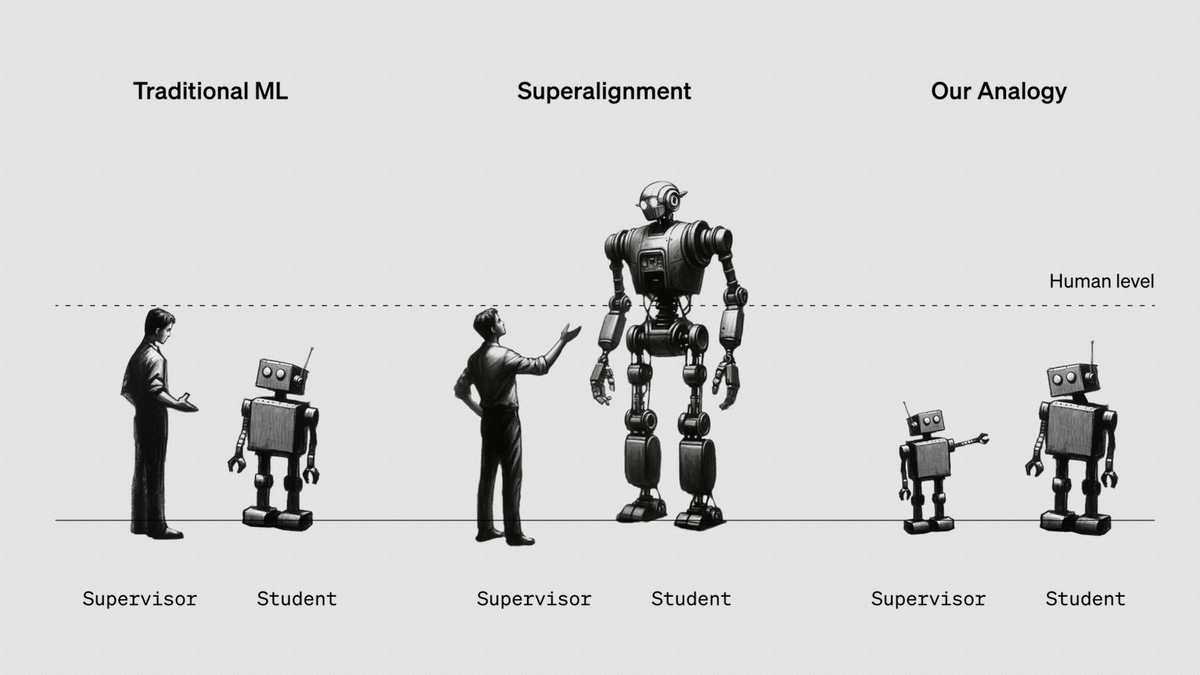
In preparation for the upcoming development of 'superintelligence' that will surpass human intelligence, OpenAI is allocating approximately 20% of its computing business to 'superalignment' to control superintelligence, and will continue to do so until 2027. aims to build solutions towards controlling superintelligence. On the other hand, Colin Burns of the Super Alignment Team said, ``It is extremely difficult to conduct research on super intelligence, which is currently undeveloped and we don't even know how to design it.'' He has problems with super alignment research. It makes it clear that.
Still, a paper published by the Super Alignment team in December 2023 showed a way around the problem of controlling superintelligence, which has yet to be developed.
Until now, AI that did not exceed the limits of human intelligence could be supervised by humans, but as superintelligence is developed in the future, it will become difficult for humans who are less intelligent than AI to monitor AI. Therefore, there is an urgent need to create a way for supervisors with low intelligence to control AI that is more powerful than themselves. So instead of seeing if humans could adequately supervise superintelligence, the Super Alignment team tested whether the large-scale language model GPT-2 could supervise the more powerful GPT-4. According to the scientific magazine IEEE Spectrum, GPT-2 has approximately 1.5 billion parameters, while GPT-4 has approximately 176 billion parameters.
The Super Alignment team gave each large-scale language model three types of tasks: a set of natural language processing (NLP) benchmarks such as chess puzzles and common sense reasoning, and questions based on a dataset of ChatGPT responses. GPT-2 has been trained specifically for these tasks, while GPT-4 has only received basic training and no fine-tuning for these tasks. However, in terms of basic training, GPT-4 outperforms GPT-2.
GPT-2 gives instructions to GPT-4 on how to perform a task, and GPT-4 executes that task. Therefore, the super alignment team predicted that ``GPT-4 would make the same mistakes as its supervisor, GPT-2.'' However, the strong model, GPT-4, consistently outperformed its supervisor, GPT-2. In particular, it was shown to perform at a level of accuracy comparable to GPT-3.5 on NLP tasks, and it was shown that it succeeded in bringing out much of the capabilities of GPT-4 even under the supervision of the less intelligent GPT-2. It has been reported.
The Super Alignment team refers to this phenomenon as 'weak-to-strong generalization,' which means that 'strong models have tacit knowledge about how to perform a task, and receive inappropriate instructions from weak supervisors.' It shows that a person can use his or her own knowledge to perform a task, even when presented with a problem. In other words, even if a weak model that is a supervisor gives instructions that contain errors or biases, a strong model will output a result that is in line with the supervisor's intentions, so a strong AI will lead to the supervisor's destruction. It is said that there will be no negative results.

On the other hand, the Super Alignment team stated, ``This verification method is only conceptual, and it did not work well in experiments using ChatGPT data.As a result, it will be difficult to generalize from weak to strong in the future. ``I hope that this will be the first step in research toward controlling superintelligence in the future.'' In fact, the Super Alignment Team has released the source code used in this experiment on GitHub, and has also provided grants of $10 million (approximately 1.4 billion yen) to students and researchers working on research on controlling superintelligence. We have announced that the financial system will start from February 2024.
Leopold Aschenbrenner of the Super Alignment Team said, ``It is part of OpenAI's mission to contribute not only to the safety of OpenAI's AI models, but also to the safety of other AI development organizations' models and other advanced AI. 'We believe that conducting this research is absolutely essential to making superintelligence useful to humans and safely handling it.'
Related Posts:








in Software, Posted by log1r_ut