Meta releases 'Segment Anything Model,' an AI model that can separate and select objects in photos
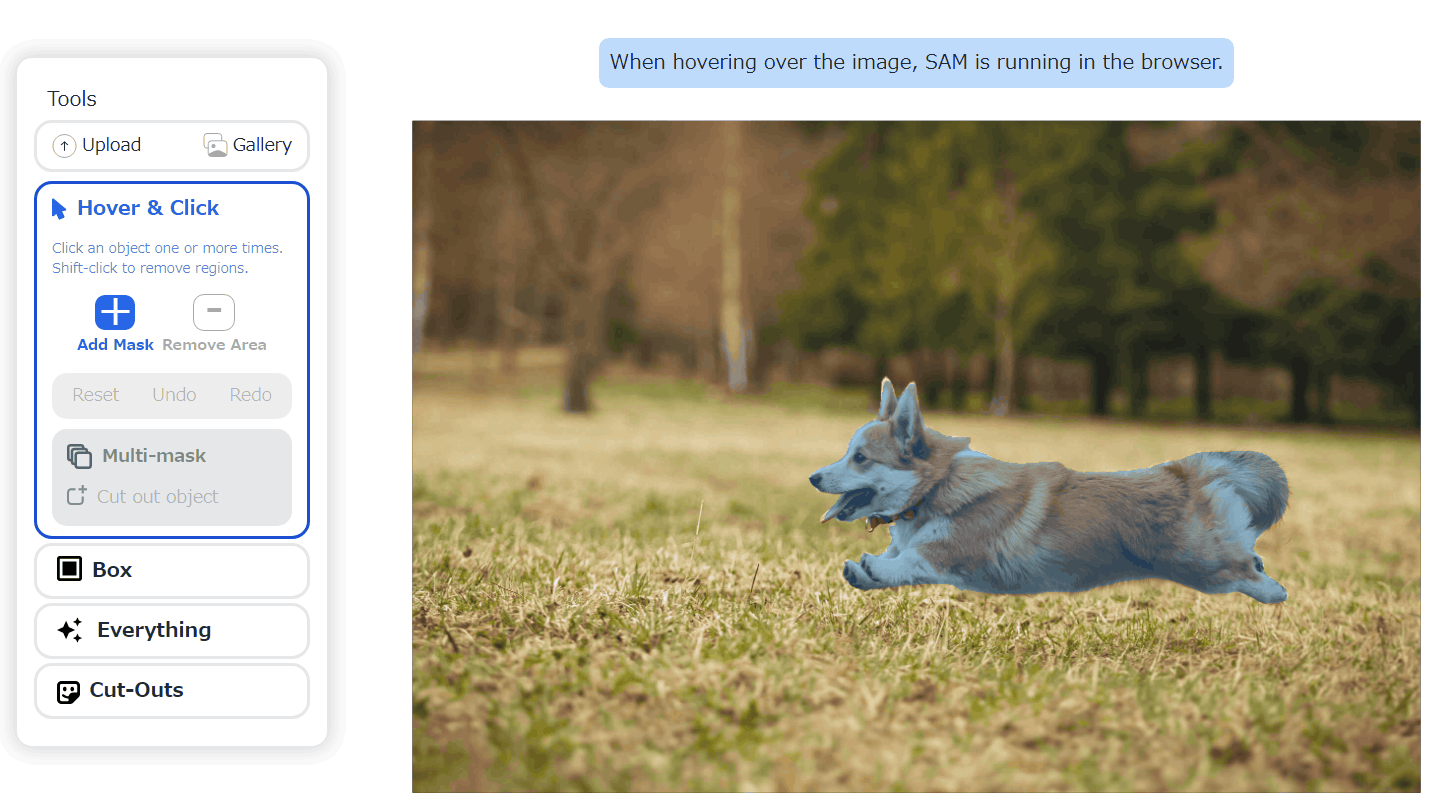
Meta has announced the Segment Anything Model (SAM), an AI model that can identify individual objects in images and videos, even those that have not been trained before.
Segment Anything | Meta AI Research
Introducing Segment Anything: Working toward the first foundation model for image segmentation
https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Meta believes that image segmentation, which divides images and videos into segments to distinguish them, can be useful for understanding web page content, augmented reality (AR) applications, and image editing. It also believes that image segmentation can be used for scientific research by automatically identifying the location of animals and objects in videos.
To see how accurate SAM can be in image segmentation, take a look at the following example provided by Meta: a photo of a kitchen scene.

This is what image segmentation looks like with SAM. It clearly identifies each knife and each lemon in the basket, and it also identifies the blade and handle of the knife.
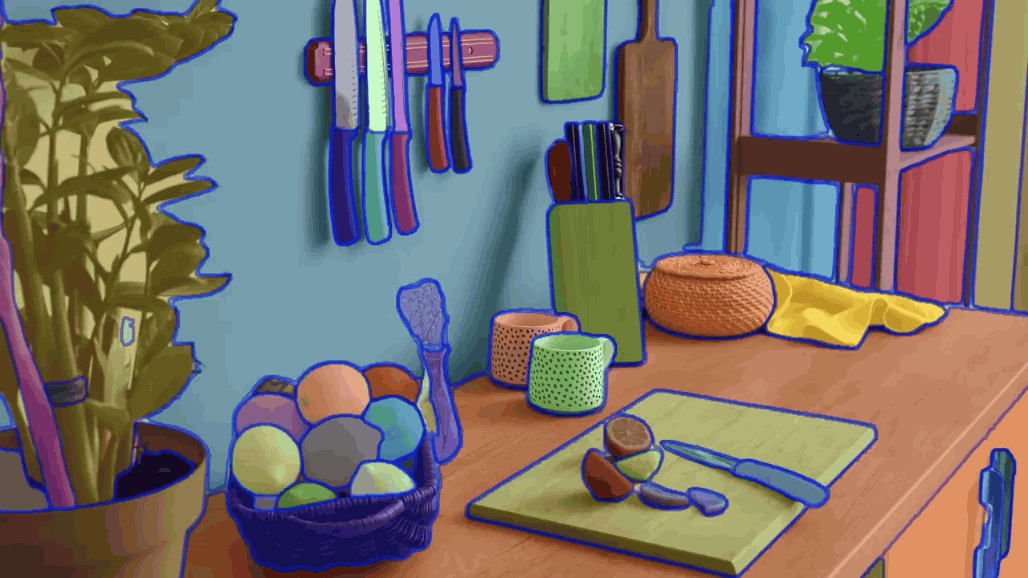
Photo of a box full of vegetables

Each vegetable can be recognized individually.

When you select a range by dragging and dropping, only the vegetables within that range are selected.

A demo of actually performing image segmentation using pre-prepared photos is available below, and it is also possible to perform image segmentation using images you upload yourself.
Segment Anything | Meta AI
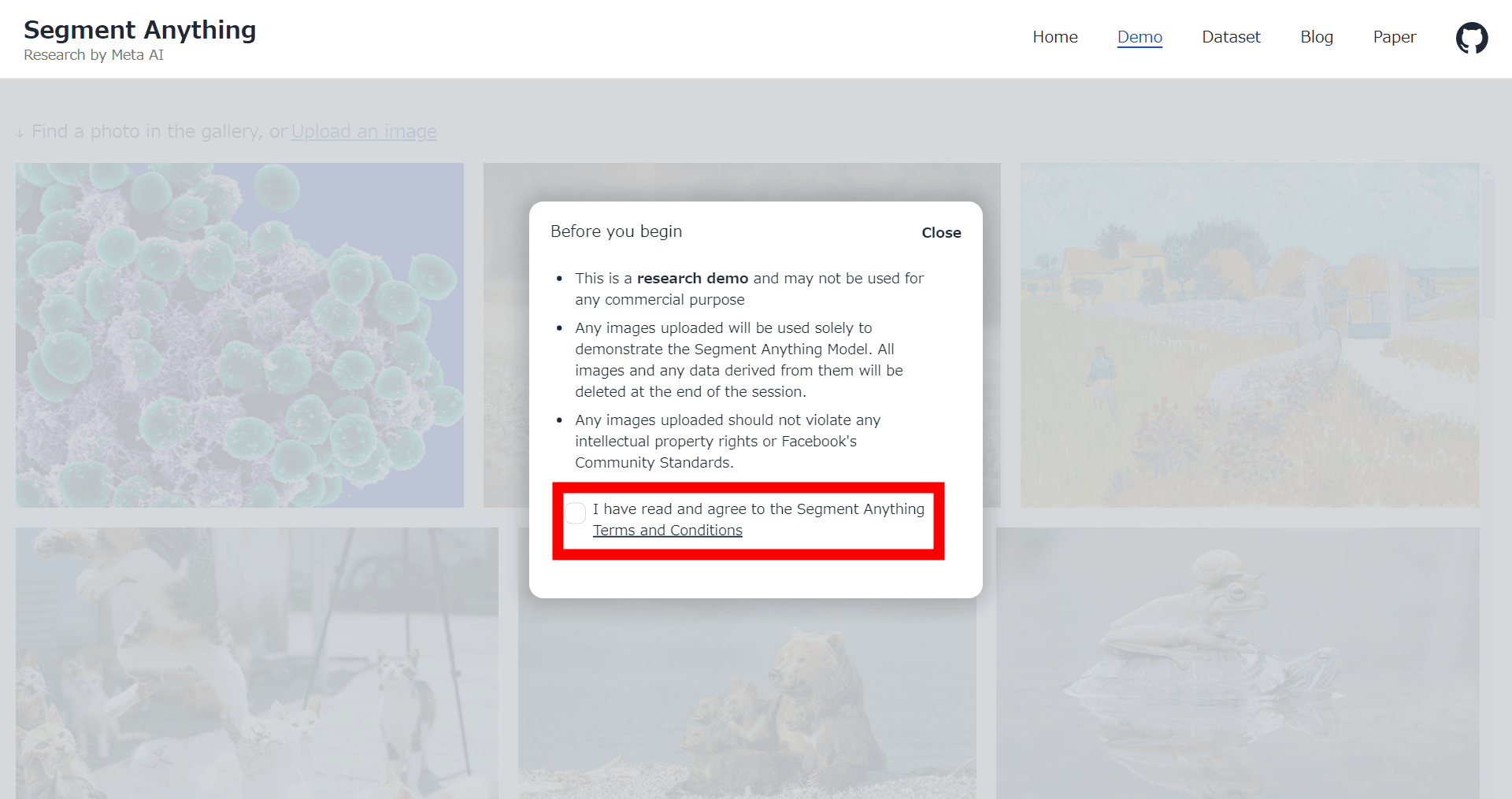
Once you access the SAM demo, click to check 'I have read and agree to the Segment Anything Terms and Conditions.'
Once you have checked the box, click 'Upload an image' at the top of the screen. This will launch File Explorer, allowing you to select the image you want to load.
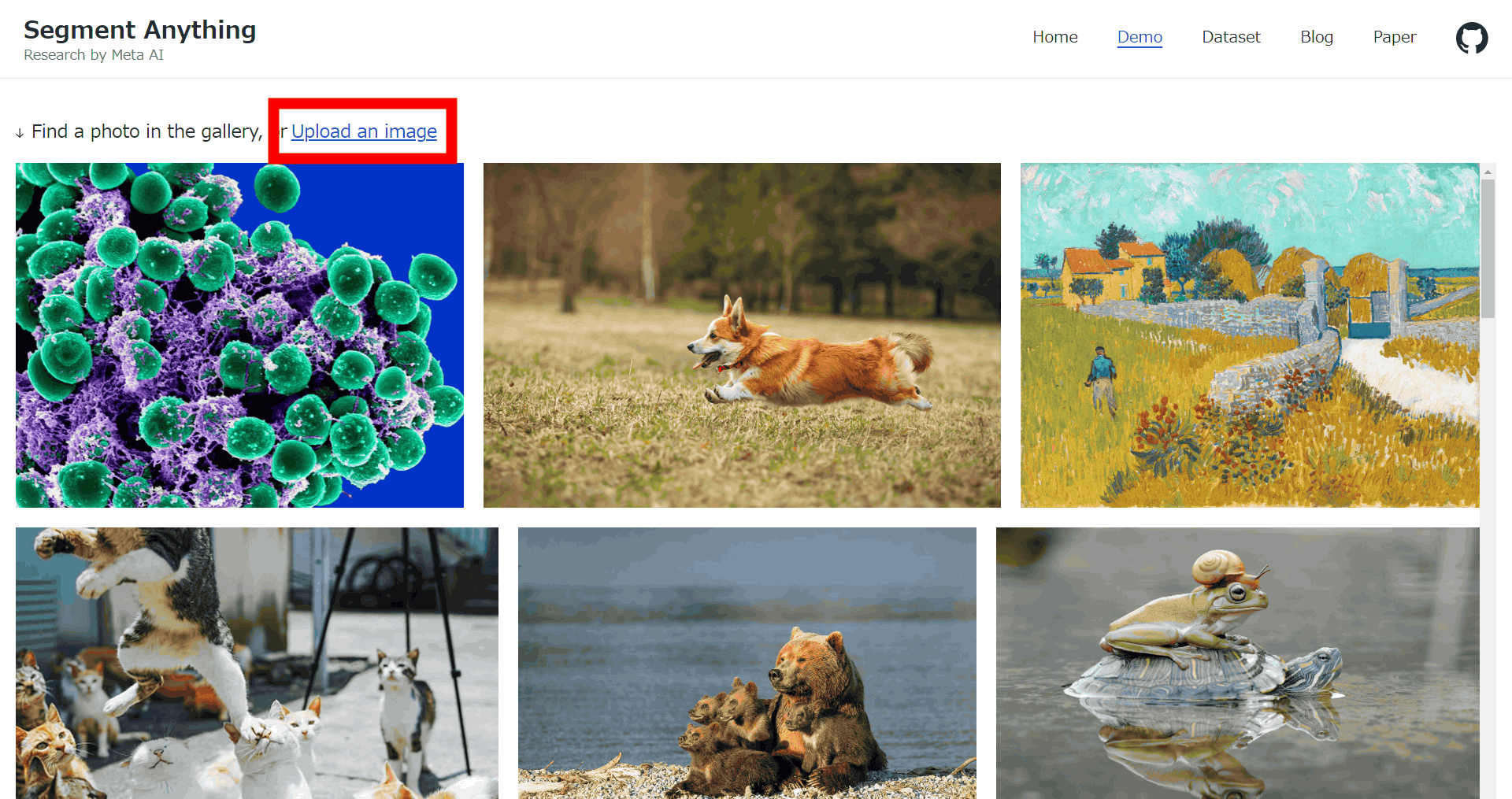
This time, I uploaded an image of
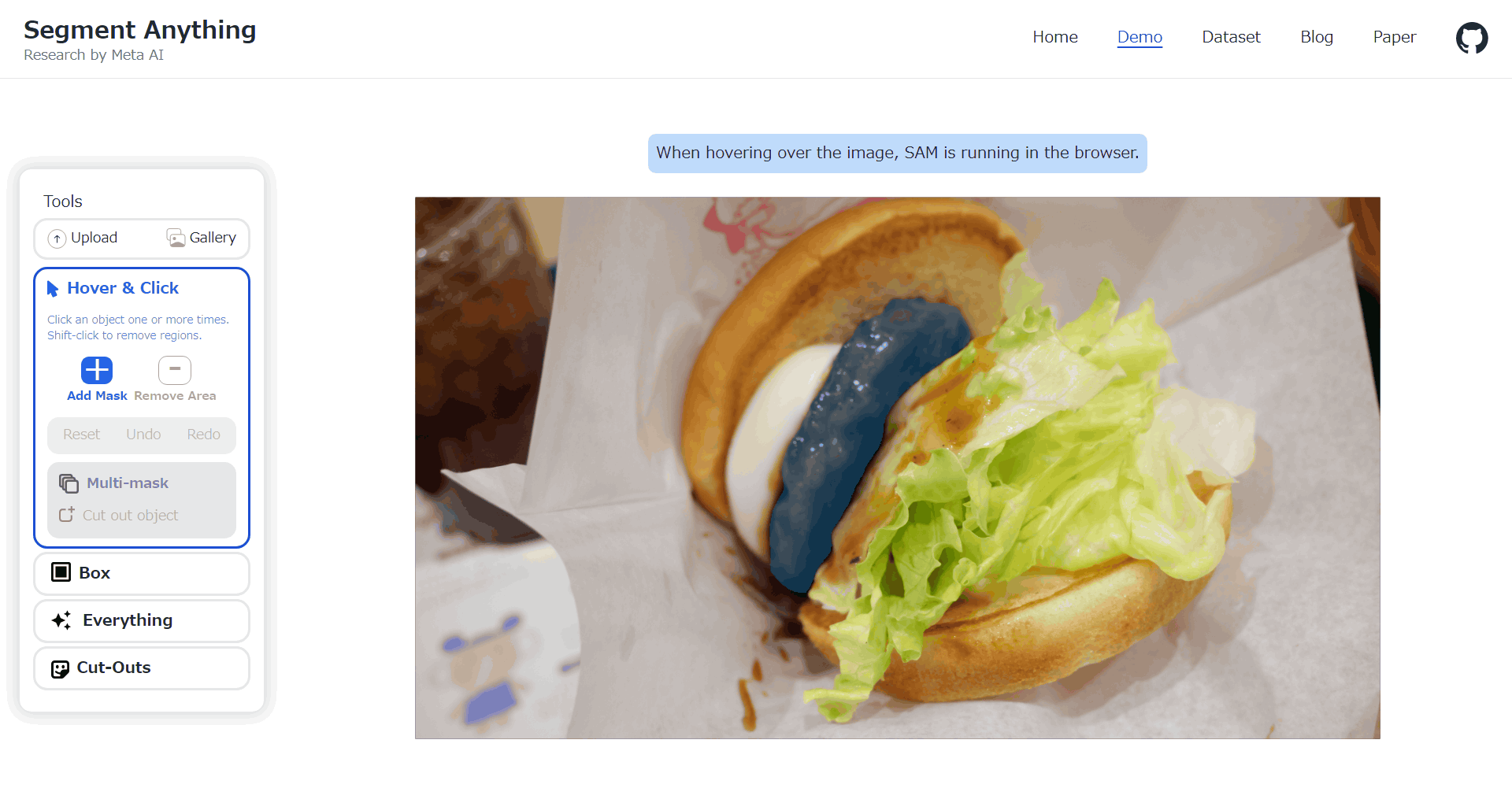
When you select lettuce it looks like this.
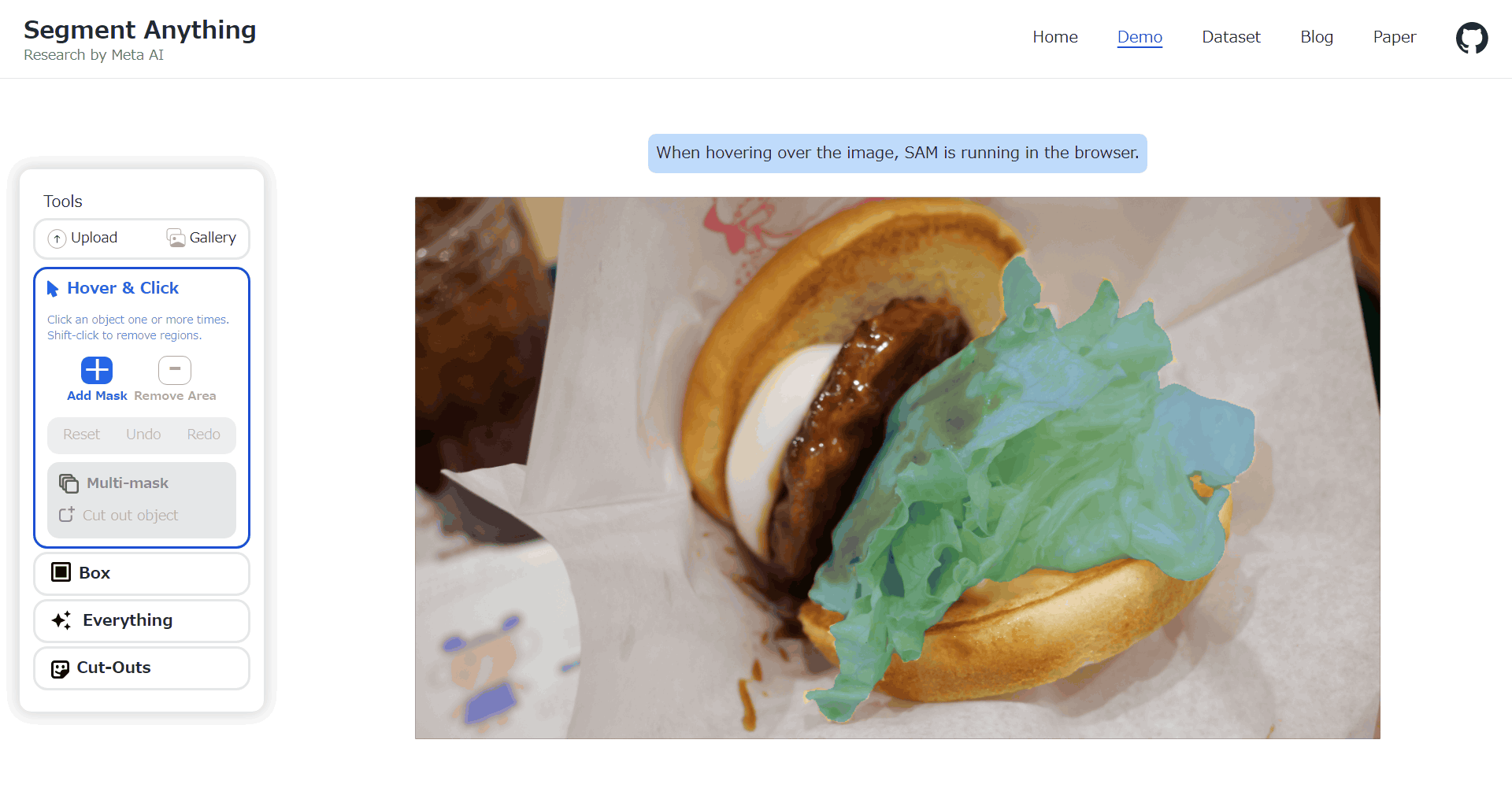
When you click on the buns, only the buns will turn blue as shown below.
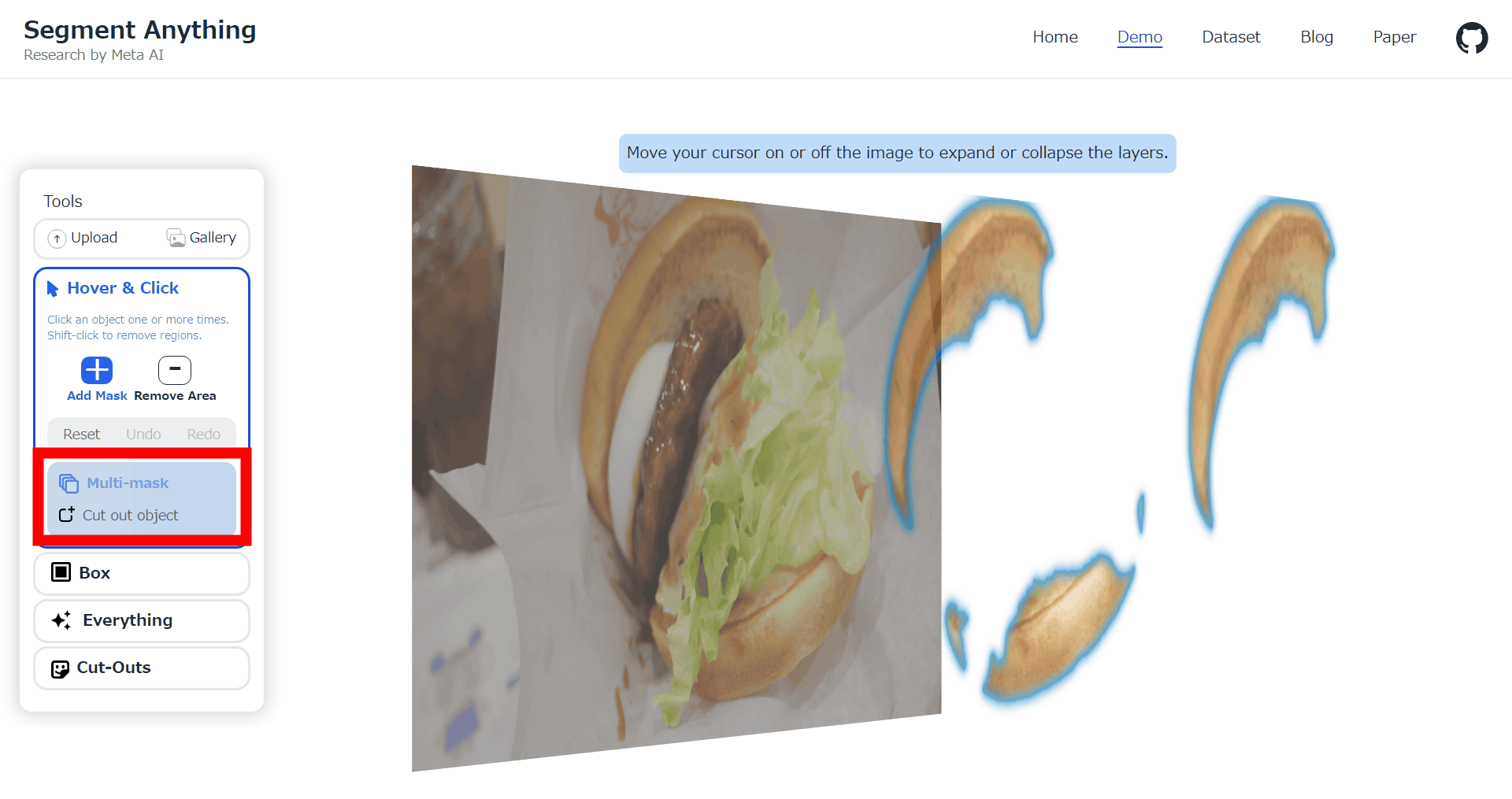
Furthermore, when I clicked 'multi-mask' in the left column, only the bun part popped out and was displayed three-dimensionally. Also, it said that items on the same layer were automatically cut out, so not only the upper buns but also the lower buns popped out.
SAM is an image segmentation model that can respond to text prompts or user clicks to isolate specific objects in an image. While image segmentation technology itself is not new, what makes SAM unique is its ability to identify objects that are not present in the training dataset.
According to Meta, creating highly accurate image segmentation models typically requires 'highly specialized work by technical experts with access to AI training infrastructure and large amounts of carefully annotated data.' By reducing the need for specialized training and expertise, SAM 'democratizes image segmentation' and hopes to further accelerate computer vision research.
The SA-1B dataset used to train SAM consists of approximately 1.1 billion high-quality segmentation masks collected by Meta's data engine under license from a major photography company and is available for research purposes under the Apache 2.0 open license.
The source code, excluding the SAM weight data, is available on GitHub.
GitHub - facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.
https://github.com/facebookresearch/segment-anything
Related Posts:







in AI, Software, Web Service, Review, Web Application, Posted by log1i_yk